创建RDD
在对数据进行任何transformation或action操作之前,必须先将这些数据构造为一个RDD。Spark提供了创建RDDs的三种方法,分别为:
- 第一种方法是将现有的集合并行化。
- 另一种方法是加载外部存储系统中的数据集,比如文件系统。
- 第三种方法是在现有RDD上进行转换来得到新的RDD。
1、将现有的集合并行化以创建RDD
创建RDD的第一种方法是将对象集合并行化,这意味着将其转换为可以并行操作的分布式数据集。 这种方法最简单,是开始学习Spark的好方法,因为它不需要任何数据文件。 这种方法通常用于快速尝试一个特性或在Spark中做一些试验。对象集合的并行化是通过调用SparkContext类的parallelize方法实现的。
配套视频:
创建和操作RDD
请看下面的代码:
// 可以从列表中创建
val list1 = List(1,2,3,4,5,6,7,8,9,10)
val rdd1 = sc.parallelize(list1)
rdd1.collect
// 通过并行集合(range)创建RDD
val list2 = List.range(1,11)
val rdd2 = sc.parallelize(list2)
rdd2.collect
// 通过并行集合(数组)创建RDD
val arr = Array(1,2,3,4,5,6,7,8,9,10)
val rdd3 = sc.parallelize(arr)
rdd3.collect
// 通过并行集合(数组)创建RDD
val strList = Array("明月几时有","把酒问青天","不知天上宫阙","今夕是何年")
val strRDD = sc.parallelize(strList)
strRDD.collect
2、从存储系统读取数据集以创建RDD
创建RDD的第二种方法是从存储系统读取数据集,存储系统可以是本地计算机文件系统、HDFS、Cassandra、Amazon S3等等。请看下面的代码:
// 或者,也可以从文件系统中加载数据创建RDD
val file = "/data/spark_demo/rdd/wc.txt" // hdfs
val rdd1 = sc.textFile(file)
SparkContext类的textFile方法假设每个文件是一个文本文件,并且每行由一个新行分隔。此textFile方法返回一个RDD,它表示所有文件中的所有行。 需要注意的重要一点是,textFile方法是延迟计算的,这意味着如果指定了错误的文件或路径,或者错误地拼写了目录名, 那么在采取其中一项action操作之前,这个问题不会出现(被发现)。
3、从已有的RDD转换得到新的RDD
创建RDD的第三种方法是调用现有RDD上的一个转换操作。例如,下面的代码通过对rdd4的转换得到一个新的RDD - rdd5:
// 字符转为大写,得到一个新的RDD
val rdd5 = rdd4.map(line => line.toUpperCase)
rdd5.collect
注:关于map函数,在稍后部分讲解。
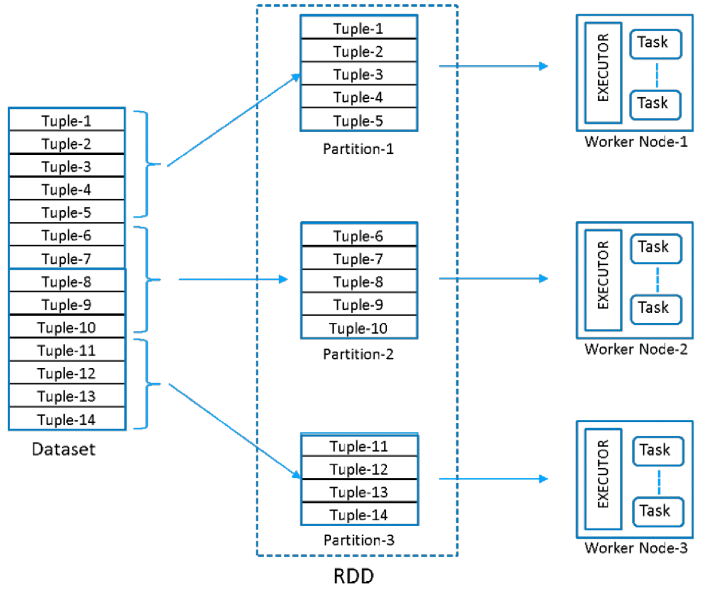
4、创建RDD时指定分区数量
Spark在集群的每个分区上运行一个任务(task),因此必须谨慎地决定优化计算工作。 尽管Spark会根据集群自动设置分区数量,但我们可以通过将其作为第二个参数传递给并行化函数。例如:
sc.parallelize(data,3) // 3个分区
下图表示创建一个RDD,包含14条记录(或元组),分区为3,分布在三个节点上: