Spark核心组件和架构
在深入了解Spark的细节之前,一定要对Spark的核心概念和各种核心组件有一个深入的理解。包括:
- Spark集群
- 资源管理系统
- Spark应用程序
- Spark Driver
- Spark Executor
Spark集群和资源管理系统
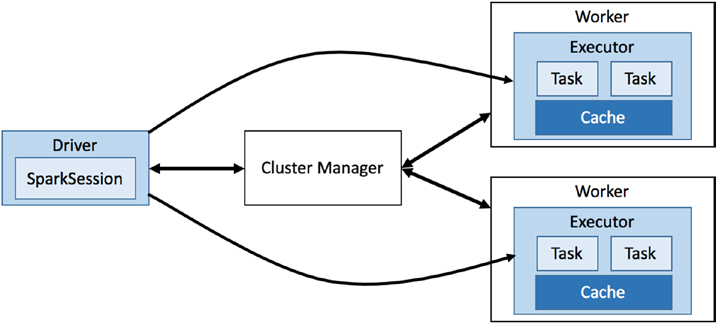
Spark本质上是一个分布式系统,它被设计用来高效、快速地处理海量数据。这个分布式系统通常部署在一个机器集合上,这就是所谓的Spark集群。为了高效和智能地管理一组机器,通常依赖于一个资源管理系统,如Apache YARN或Apache Mesos。 资源管理系统内部有两个主要组件:集群管理器(cluster manage)和工作节点(worker)。它有点像主从(master-slave)架构,其中Cluster Manager(集群管理器)充当主节点,Worker充当集群中的从节点。集群管理器跟踪与Worker节点及其当前状态相关的所有信息。集群管理器维护的信息包括:
- Worker节点的状态(busy/available)
- Worker节点位置
- Worker节点内存
- Worker节点的总CPU核数
集群管理器知道worker在哪里,他们有多少内存,以及每个worker的CPU核数量。集群管理器的主要职责之一是管理Worker节点并根据Worker节点的可用性和容量为它们分配任务。每个Worker节点都提供资源(内存,CPU等)到集群管理器,并负责执行集群管理器分配的任务,如下图所示:
Spark应用程序
一个Spark应用程序由两部分组成。第一个是使用Spark API表示的应用程序数据处理逻辑,另一个是Spark驱动程序(Spark Driver)。
应用程序数据处理逻辑(Task)是用Java或Scala或Python或R这几种语言编写的数据处理逻辑代码。它可以简单到几行代码来执行一些数据处理操作,也可以复杂到训练一个大型机器学习模型,这个模型需要多次迭代,可能要运行很多个小时才能完成。
Spark驱动程序是Spark应用程序的主控制器,它负责组织和监控一个Spark应用程序的执行。它与集群管理器进行交互,以确定哪台机器来运行数据处理逻辑。Driver及其子组件(Spark session和scheduler)负责如下职责:
- 向集群管理器请求内存和CPU资源
- 将应用程序逻辑分解为阶段和任务(stages和tasks)
- 请求集群管理器启动名为Spark Executor的进程(在运行task的节点上)
- 向executors发送tasks(应用程序数据处理逻辑),每个task都在一个单独的CPU core上执行。
- 与每个Spark Executor协调以收集计算结果并将它们合并在一起
Spark应用程序的入口点是通过一个名为SparkSession的类来实现的。一旦Driver程序被启动之后,它启动并配置SparkSession的一个实例。SparkSession是访问Spark运行时的主要接口。SparkSession对象连接到一个集群管理器,并提供了设置配置的工具,以及用于表示数据处理逻辑的API。
除此之外,还需要一个客户端组件(client)。客户端(client)进程负责启动driver程序。客户端(client)进程可以是一个用于运行程序的spark-submit脚本,也可以是一个spark-shell脚本或一个使用Spark API的自定义应用程序。客户端(client)进程为Spark程序准备classpath和所有配置选项,并传递应用程序参数(如果有的话)给运行在Driver中的程序。
Spark Driver和Executor
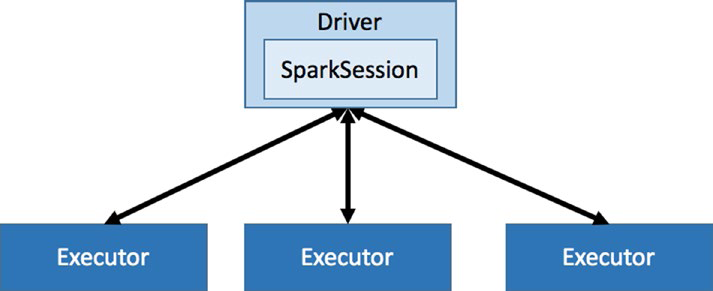
Spark应用程序也采用了主从架构,其中Spark Driver是master,Spark Executors是slave。每一个组件都作为一个独立的JVM进程在Spark集群上运行。Spark应用程序由一个且只有一个Spark Driver和一个或多个Spark Executors组成。
Spark Driver包含多个组件,负责将用户代码转换为在集群上执行的实际作业:

各个组件的功能如下:
- SparkContext:表示到Spark集群的连接,可用于在该集群上创建RDDs、累加器和广播变量。
- DAGScheduler:计算每个作业的stages的DAG,并将它们提交给TaskScheduler,确定任务的首选位置(基于缓存状态或shuffle文件位置),并找到运行作业的最低调度。
- TaskScheduler:负责将任务(Tasks)发送到集群,运行它们,在出现故障时重试,并减少掉队的情况。
- SchedulerBackend:用于调度系统的后端接口,允许插入不同的实现(Mesos、YARN、单机、本地)。
- BlockManager:提供用于在本地和远程将block块放入和检索到各种存储(内存、磁盘和非堆)中的接口。
每个应用程序都有一组Executor进程。每个Spark Executor都是一个JVM进程,扮演slave角色,专门分配给特定的Spark应用程序,执行命令,以任务(Task)的形式执行数据处理逻辑。每个任务在一个单独的CPU核心上执行。
Executors驻留在worker节点上,一旦集群管理器建立连接,就可以直接与Driver通信,接受来自Driver的任务(Tasks),执行这些任务,并将结果返回给该Driver。每个Executor都有几个并行运行任务的任务槽(Task Slots)。可以将任务槽的数量设置为2或3倍的CPU核心数量。尽管这些任务槽通常被称为Spark中的CPU cores,但它们是作为线程实现的,并且不需要与机器上的物理CPU cores数量相对应。另外,每个Spark Executor都由一个Block Manager组件组成,Block Manager负责管理数据块。这些块可以缓存RDD数据、中间处理的数据或广播数据。当可用内存不够时,它会自动将一些数据块移动到磁盘。Block Manager的还有一个职责是跨节点的数据复制。
在启动一个Spark应用程序时,可以请求一个应用程序需要多少个Spark Executor,以及每个Executor应该拥有多少内存和CPU内核。要计算出适当数量的Spark Executor、内存数量和CPU数量,需要了解将要处理的数据量、数据处理逻辑的复杂性以及Spark应用程序完成处理逻辑所需的持续时间。
