理解RDD及RDD编程模型
Spark Core包含Spark的基本功能,包括任务调度组件、内存管理、故障恢复、与存储系统交互等。在Spark Core中,核心的数据抽象,称为弹性分布式数据集(RDD)。 RDD是Spark Core的用户级API,要真正理解Spark的工作原理,就必须理解RDD的本质。它们为其他抽象提供了一个非常坚实的基础。
配套视频:
Spark核心数据抽象RDD
Spark为Scala、Java、R和Python编程语言提供了APIs。Spark本身是用Scala编写的,但Spark通过PySpark支持Python。 PySpark构建在Spark的Java API之上(使用Py4J)。通过Spark(PySpark)上的Python的交互式shell,可以对大数据进行交互式数据分析。 数据科学界大多选择Scala或Python来进行Spark程序开发。
1、理解数据抽象RDD
在Spark的编程接口中,每一个数据集都被表示为一个对象,称为RDD。RDD是一个只读的(不可变的)、分区的(分布式的)、容错的、延迟计算的、类型推断的和可缓存的记录集合。
所谓RDD (Resilient Distributed Dataset,弹性分布式数据集),指的是:
- Resilient:不可变的、容错的
- Distributed:数据分散在不同节点(机器,进程)
- Dataset:一个由多个分区组成的数据集
Spark RDD是对跨集群分布的各个分区的引用的集合。参考下图理解:
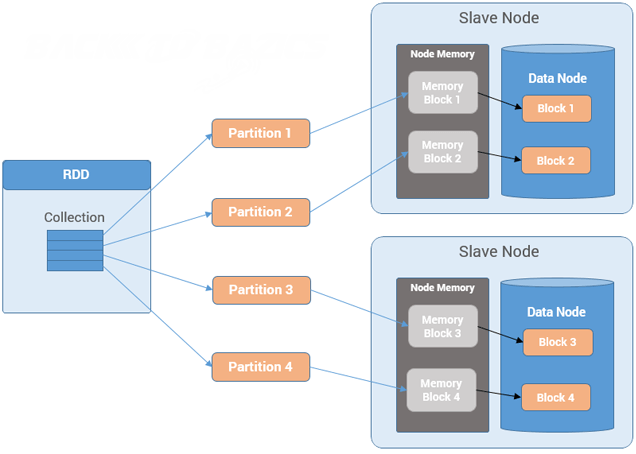
RDD是Resillient Distributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。通常RDD很大,会被分成很多个分区,分别保存在不同的节点上。RDD是不可变的、容错的、并行的数据结构,允许用户显式地将中间结果持久化到内存中,控制分区以优化数据放置,并使用一组丰富的操作符来操作它们。
RDD被设计成不可变的,这意味着我们不能具体地修改数据集中由RDD表示的特定行。如果调用一个RDD操作来操纵RDD中的行,该操作将返回一个新的RDD。原RDD保持不变,新的RDD将以我们希望的方式包含数据。RDD的不变性本质上要求RDD携带"血统"信息,Spark利用这些信息有效地提供容错能力。
RDD提供了一组丰富的常用数据处理操作。它们包括执行数据转换、过滤、分组、连接、聚合、排序和计数的能力。关于这些操作需要注意的一点是,它们在粗粒度级别上进行操作,这意味着相同的操作应用于许多行,而不是任何特定的行。
综上所述,RDD只是一个逻辑概念,它可能并不对应磁盘或内存中的物理数据。根据Spark官方描述,RDD由以下五部分组成:
- 一组partition(分区),即组成整个数据集的块;
- 每个partition(分区)的计算函数(用于计算数据集中所有行的函数);
- 所依赖的RDD列表(即父RDD列表);
- (可选的)对于key-value类型的RDD,则包含一个Partitioner(默认是HashPartitioner);
- (可选的)每个partition数据驻留在集群中的位置(可选);如果数据存放在HDFS上,那么它就是块所在的位置。
Spark运行时使用这5条信息来调度和执行通过RDD操作表示的用户数据处理逻辑。 前三段信息组成“血统”信息,Spark将其用于两个目的。第一个是确定RDDs的执行顺序,第二个是用于故障恢复目的。
Spark通过使用"血统"信息重建失败的部分,自动地代表其用户处理故障。
每一个RDD或RDD分区都知道如何在出现故障时重新创建自己。它有转换的日志,或者血统(lineage),可依据此从稳定存储器或另一个RDD中重新创建自己的。 因此,任何使用Spark的程序都可以确保内置的容错能力,而不考虑底层数据源和RDD类型。
作为Spark中最核心的数据抽象,RDD具有以下特征:
- In-Memory:RDD会优先使用内存;
- Immutable(Read-Only):一旦创建不可修改;
- Lazy evaluated:惰性执行;
- Cacheable:可缓存,可复用;
- Parallel:可并行处理;
- Typed:强类型,单一类型数据;
- Partitioned:分区的;
- Location-Stickiness:可指定分区优先使用的节点;
2、RDD编程模型
在Spark中,使用RDD对数据进行处理,通常遵循如下的模型:
- 首先,将待处理的数据构造为RDD;
- 对RDD进行一系列操作,包括Transformation和Action两种类型操作;
- 最后,输出或保存计算结果。
这个处理流程可以用下图表示:

下面我们使用Spark RDD来实现经典的单词计数应用程序。
【示例】使用Spark RDD实现单词计数。这里我们使用Zeppelin作为开发工具,大家可以根据自己的喜好选择任意其他工具。
(1)首先准备一个文本文件wc.txt,内容如下:
good good study
day day up
(2)将该文本文件上传到HDFS的"/data/spark_demo/"目录下:
$ hdfs dfs -put wc.txt /data/spark_demo/
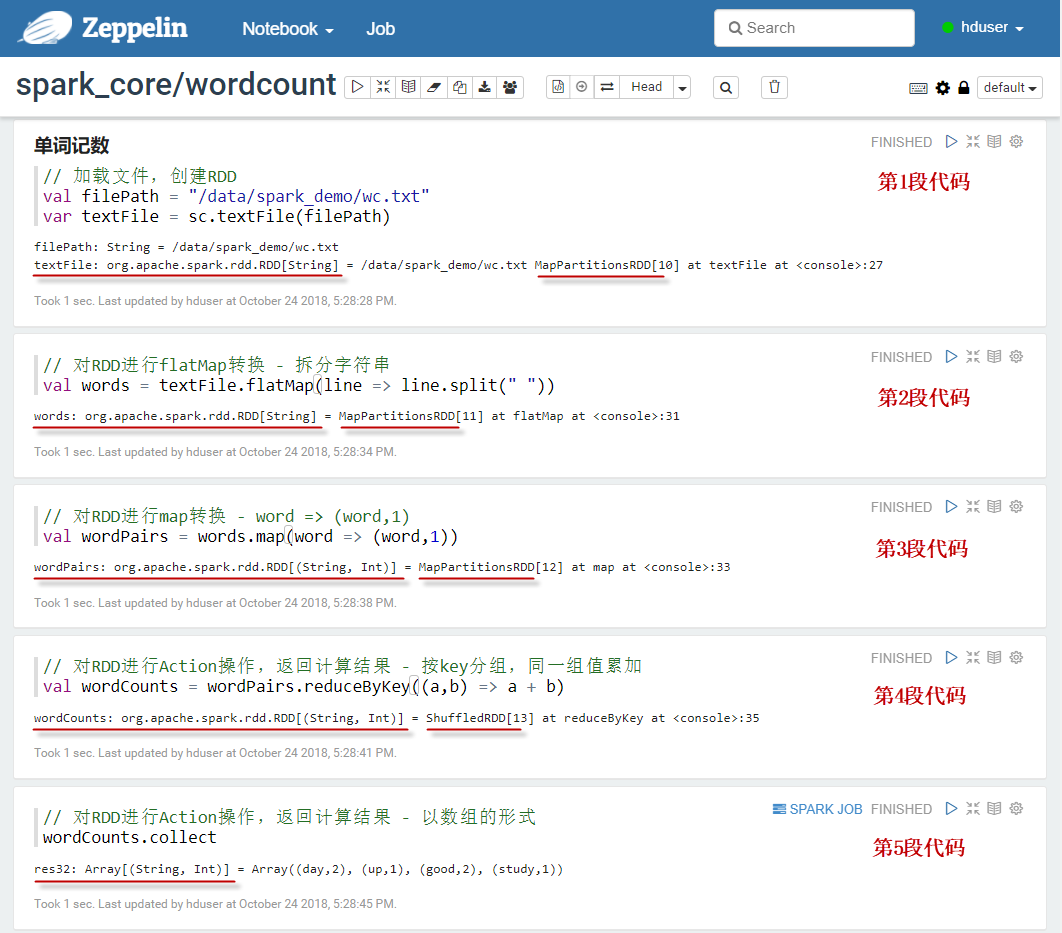
(3)在Zeppelin中新建一个notebook。在notebook的单元格中,执行代码。
(4)读取数据源文件,构造一个RDD
val source = "hdfs://localhost:8020/data/wc.txt"
var textFile = sc.textFile(source)
(5)将每行数据按空格拆分成单词 - 使用flatMap转换
val words = textFile.flatMap(line => line.split(" "))
(6)将各个单词加上计数值1 - 使用map转换
val wordPairs = words.map(word => (word,1))
(7)对所有相同的单词进行聚合相加求各单词的总数 - 使用reduceByKey转换
val vordCounts = wordPairs.reduceByKey((a,b) => a + b)
(8)返回结果给Driver程序,这一步才触发RDD开始实际的计算 - Action
wordCounts.collect()
(9)或者,也可以将计算结果保存到文件中 - Action
val sink = "hdfs://localhost:8020/data/result"
wordCounts.saveAsTextFile(sink)
在Zeppelin中交互式数据处理过程如下图所示:
以上代码也可以精简为下面一句:
val source = "hdfs://localhost:8020/data/wc.txt"
sc.textFile(source)
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.collect
.foreach(println)
