Hive系统架构
Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。
Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,
- 1)网络日志分析:大部分互联网公司使用hive进行日志分析,包括百度、淘宝等。 统计网站一个时间段内的pv(page view,即页面浏览量)、uv(unique visitor,是指通过互联网访问、浏览这个网页的自然人)。
- 2)多维度数据分析
- 3)海量结构化数据离线分析
Hive执行原理
下图解释了Hive SQL查询提交到Hive执行的流程。
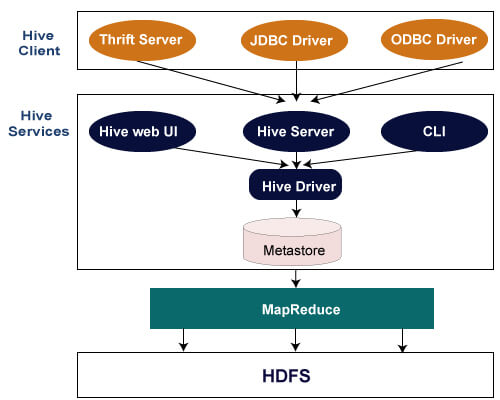
Hive SQL将通过CLI接入,或JDBC/ODBC接入,或者Thrift接入,通过Driver(Complier、Optimizer和Executor),进行编译,分析优化, 最后变成可执行的MapReduce。MapReduce开发人员可以把自己写的Mapper和Reducer作为插件支持Hive做更复杂的数据分析。
Hive体系架构
Hive的体系结构如下图所示,由四部分组成。
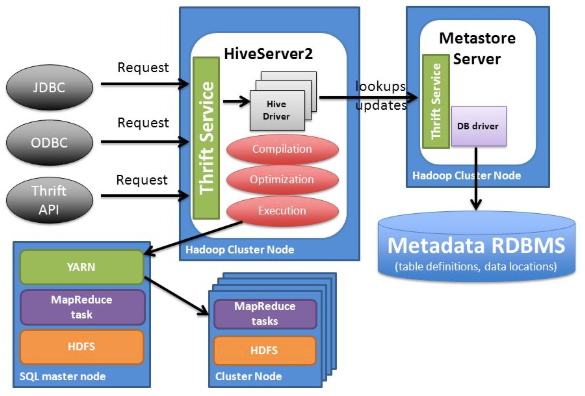
(1)用户接口。
Hive的用户接口主要有三个:命令行接口(CLI)、Web界面(WUI)和远程服务方式(Client)。其中最常用的是CLI,以命令行的形式输入SQL语句进行数据操作,CLI启动时会同时启动一个Hive副本。WUI是通过浏览器方式访问Hive。Client是Hive的客户端,用户连接至Hive Server,通过JDBC等方式进行访问。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。
(2)元数据存储。
Hive将元数据存储在数据库中,如MySql、Derby。Hive中的元数据包括表的名称,表的列,表的分区,表的属性(是否为外部表等)以及表的数据所在目录等。
(3)解释器、编译器、优化器。
分别完成HiveQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)数据存储。
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapReduce任务)。
Hive执行过程:
- (1)执行查询。Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。
- (2)获取计划。在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。
- (3)获取元数据。编译器发送元数据请求到Metastore(任何数据库)。
- (4)发送元数据。Metastore发送元数据,以编译器的响应。
- (5)发送计划。编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。
- (6)执行计划。驱动程序发送的执行计划到执行引擎。
- (7)执行工作。在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。
- (7.1)元数据操作。与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。
- (8)获得结果。执行引擎接收来自数据节点的结果。
- (9)发送结果。执行引擎发送这些结果值给驱动程序。
- (10)发送结果。驱动程序将结果发送给Hive接口。
Hive 的核心是驱动引擎,驱动引擎由四部分组成:
- 解释器:解释器的作用是将HiveSQL 语句转换为语法树(AST)。
- 编译器:编译器是将语法树编译为逻辑执行计划。
- 优化器:优化器是对逻辑执行计划进行优化。
- 执行器:执行器是调用底层的计算框架执行逻辑执行计划。
解析器、编译器、优化器:
Driver 调用解析器处理 HiveQL 字串,这些字串可能是一条 DDL、DML或查询语句。 编译器将字符串转化为计划(plan)。 计划(plan)仅由元数据操作和HDFS操作组成,元数据操作只包含DDL语句,HDFS操作只包含LOAD语句。
对插入和查询而言,策略由 MapReduce 任务中的有向无环图(DAG)组成,具体流程如下。
- 1)解析器(parser):将查询字符串转化为解析树表达式。
- 2)语义分析器(semantic analyzer):将解析树表达式转换为基于块(block-based)的内部查询表达式, 将输入表的模式(schema)信息从 metastore 中进行恢复。 用这些信息验证列名, 展开 SELECT * 以及类型检查(固定类型转换也包含在此检查中)。
- 3)逻辑计划生成器(logical plan generator):将内部查询表达式转换为逻辑策略,这些策略由逻辑操作树组成。
- 4)优化器(optimizer):通过逻辑策略构造多途径并以不同方式重写。
- 5)Hive中的执行器,是将最终要执行的MapReduce程序放到YARN上以一系列Job的方式去执行。
优化器的功能如下:
- 将多 multiple join 合并为一个 multi-way join;
- 对join、group-by 和自定义的 map-reduce 操作重新进行划分;
- 消减不必要的列;
- 在表扫描操作中推行使用谓词下推;
- 对于已分区的表,消减不必要的分区;
- 在抽样查询中,消减不必要的桶。
- 此外,优化器还能增加局部聚合操作用于处理大分组聚合和增加再分区操作用于处理不对称的分组聚合。
Hive 的底层存储:
- Hive的数据是存储在HDFS上的。
- Hive中的库和表可以看做是对HDFS上数据做的一个映射。
Hive的元数据存储
Hive表定义和数据库定义以及与HDFS中的数据映射,是存储在一个metastore中的。metastore是用于Hive元数据的中央存储库。每当创建一个Hive表时,就在HCatalog中创建了一个结构。
一个metastore由两个主要的组件组成:
- Services:响应客户端连接和metastore查询;
- 存储元数据的后台数据库。
Hive的元数据是一般是存储在MySQL这种关系型数据库上的,Hive和MySQL之间通过MetaStore服务交互。
Hive支持的关系数据库有derby和mysql。
元数据对于Hive十分重要,因此Hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦Hive服务和metastore服务,保证Hive运行的健壮性;
