使用桶表进行查询优化
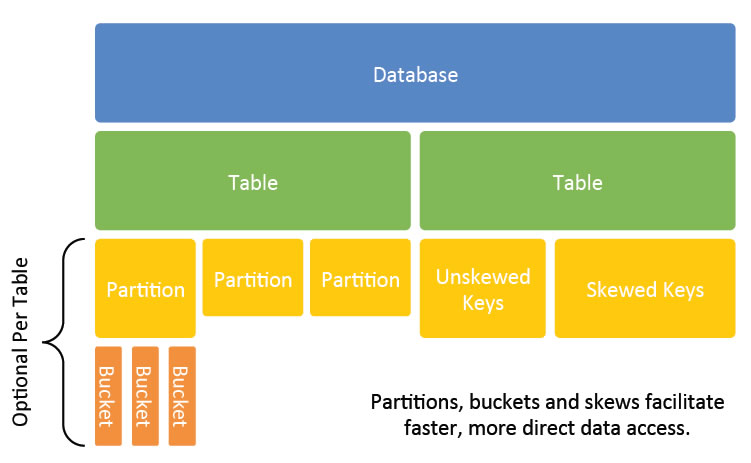
为了便于管理和提高性能,可以将Hive表拆分成更多的逻辑块。
Hive数据模型
在Hive中,数据库和表按照逻辑顺序排列为目录,便于操作和维护。即,Hive逻辑上将数据库和数据表存储为目录。
Hive桶表
在Apache Hive中,为了将表数据集分解为更易于管理的部分,它使用了Hive Bucketing概念。我们称之为“桶表”。
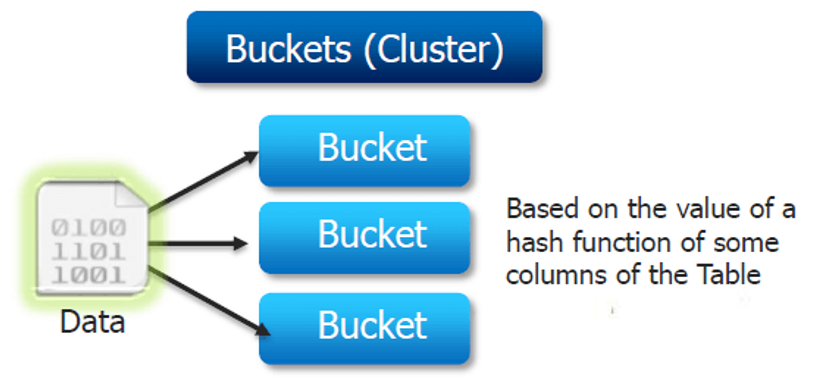
划分是基于我们在表中选择的特定列的Hash执行的。同一列中具有相同值的记录将始终存储在相同的bucket中。
桶在后端使用某种形式的哈希算法读取每条记录并将其放入存储桶中。每个桶作为一个文件存储在表的目录或HDFS上的分区目录中。

有了分区表,为什么还要使用桶表?
Hive Partitioning的概念提供了一种将Hive表数据隔离到多个文件/目录中的方法。然而,它只在少数情况下提供有效的结果。如:
- 当有有限的分区数量时。
- 或者,分区的大小相对相等。
然而,这不是在所有情况下都可能的。
为了解决过度分区(数据倾斜)的问题,Hive提出了Bucketing概念。它是将表数据集分解为更易于管理的部分的另一种有效技术。
Hive Bucketing是一种将表分割成有或没有分区的受管理集群的方法。可以只在一个列上创建桶,也可以在一个分区表上创建桶,以进一步分割数据,提高分区表的查询性能。
通过分区,Hive根据每一列的不同值将表划分(创建一个目录)成更小的部分,而通过bucket,可以在创建Hive表时指定要创建的桶的数量。
一般在两种情况下创建Hive桶表:
- 在Partitioned表上创建一个bucket,进一步划分表,以提高查询性能。
- 在无法选择分区列的表上创建Bucketing,因为列上有太多不同的值。
Hive分桶算法原理
分桶是基于桶列上的哈希函数。具有相同桶列的记录将始终存储在相同桶中。
桶数计算公式:hash_function(bucketing_column) mod num_buckets
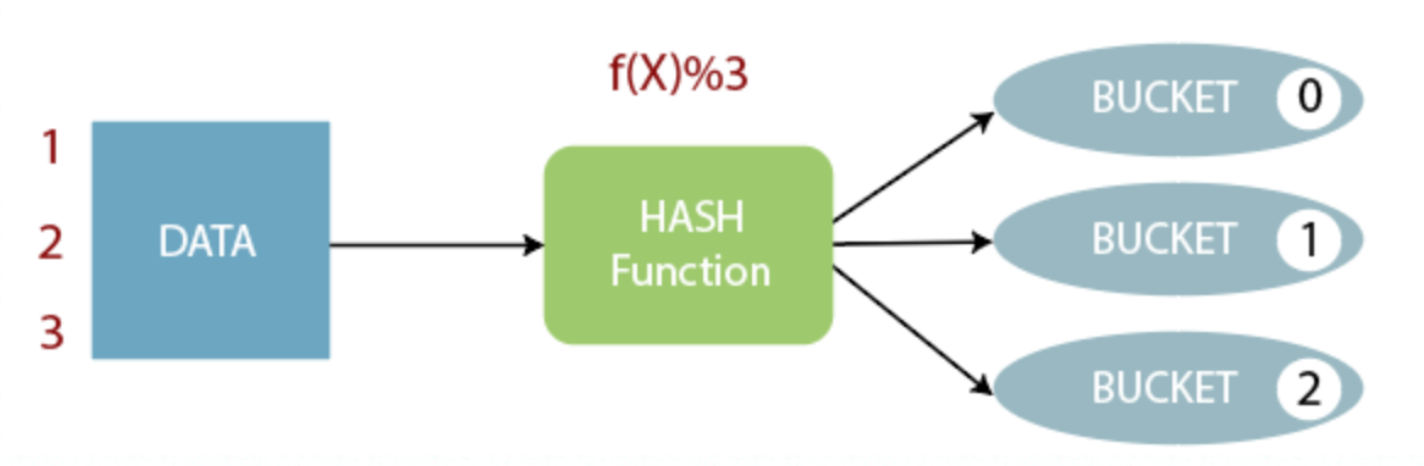
通常,在表目录中,每个桶只是一个文件。此外,bucket表将创建几乎均匀分布的数据文件部分。
Hive中Bucketing的优点
与非桶表相比,桶表提供了高效的采样。
桶表比非桶表提供更快的查询响应。在较大的表上,查询性能提高2-3倍。
在桶表上,map join将比非桶表更快,因为数据文件是大小相等的部分。由于每个bucket的连接成为一个高效的合并排序,这使得映射端连接更加高效。

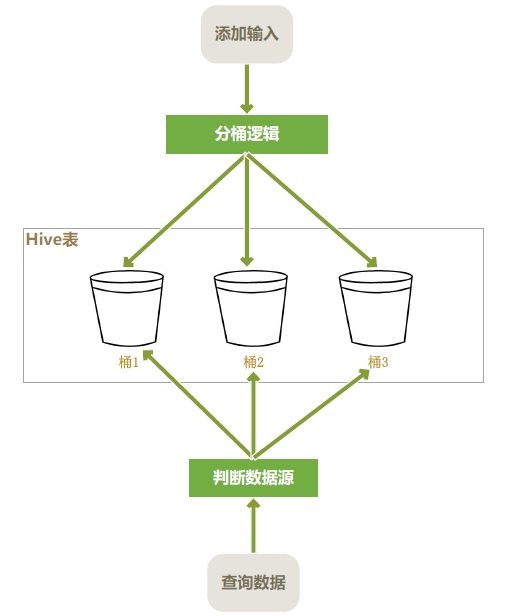
Hive桶表创建示例
在下面的示例中,创建一个带有桶的orders_bucket表,其中odate列作为bucketed列。它被分散为5个桶。
create table if not exists orders_bucket ( oid int, uid int, addr string, odate string ) clustered by (oid) into 5 buckets row format delimited fields terminated by ','; # 向桶表中插入数据 insert into table orders_bucket select * from orders; # 使用tablesample在一部分桶上查询而不是整个数据集上查询 select * from users_bucket where oid=1234565; select * from orders_bucket tablesample(bucket 1 out of 5 on odate); # 查询第一个桶 select * from orders_bucket tablesample(bucket 2 out of 5 on odate); # 查询第二个桶
