启用向量化进行查询优化
为了提高查询性能,Apache Hive中引入了新的向量化方法。
默认情况下,Apache Hive查询执行引擎一次处理一行表。在处理下一行之前,一行数据经过查询中的所有操作符,这导致CPU使用率非常低。在向量化查询执行中,数据行被批处理在一起,并表示为一组列向量。向量化查询执行的基本思想是将一批行处理为列向量数组。
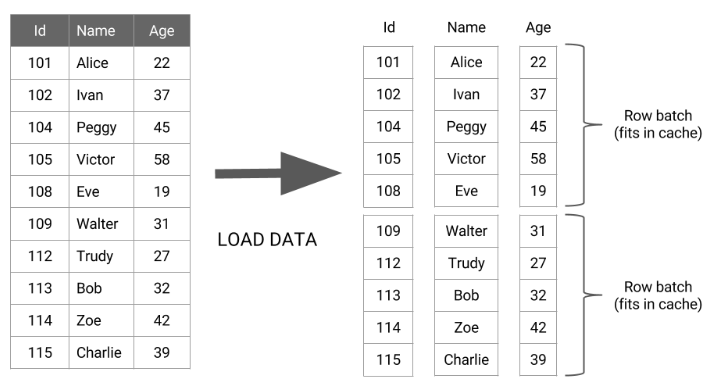
当启用查询向量化时,查询引擎处理列的向量,这极大地提高了典型查询操作(如扫描、筛选、聚合和连接)的CPU利用率。
启用Hive向量化
通过设置hive.vectorized.execution.enabled属性为true或false,可以为所有文件格式启用或禁用Apache Hive向量化。并确保未为hive.vectorized.input.format.excludes属性设置任何值。
要确保对Parquet文件格式使用查询向量化,必须确保hive.vectorized.input.format.excludes属性未设置为 org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat。
查看命令如下:
hive> set hive.vectorized.execution.enabled hive> set hive.vectorized.input.format.excludes
检查查询向量化
要验证查询是向量化的,使用EXPLAIN VECTORIZATION语句。此语句返回一个查询计划,该计划显示Hive查询执行引擎如何处理查询以及是否触发了向量化。
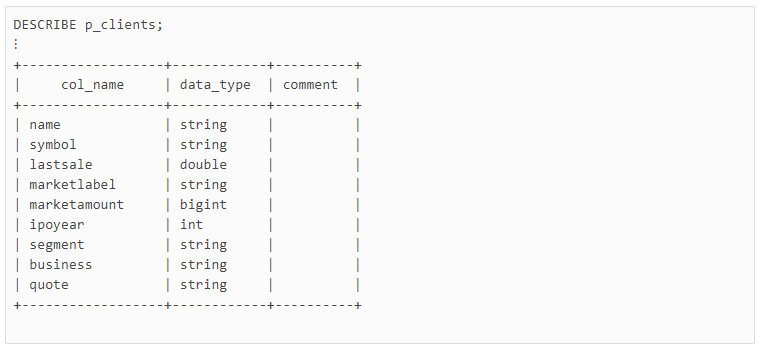
例如,这里我们使用一个示例表p_clients,它使用Parquet格式,包含以下列和数据类型:
要获得指定查询的查询执行计划,可在beeline中执行以下命令:
EXPLAIN VECTORIZATION SELECT COUNT(*) FROM p_clients WHERE ipoyear = 2009;
该命令返回如下的查询执行计划:
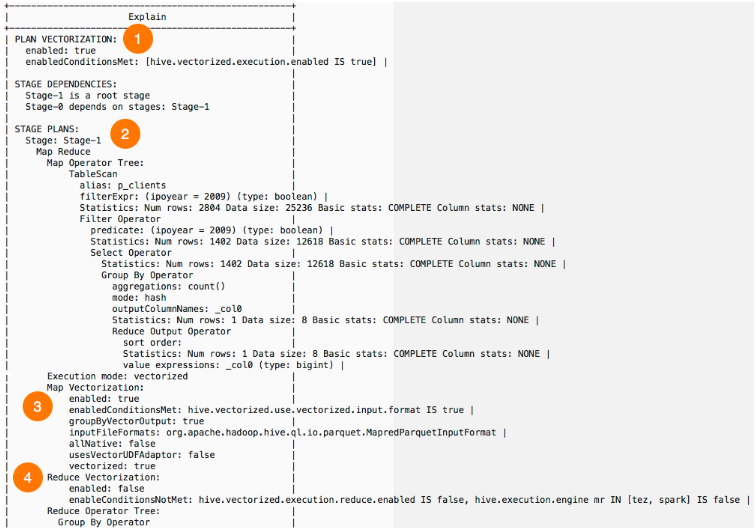
在这个查询计划的以下几个部分中解释了向量化(vectorization):
1)PLAN VECTORIZATION部门显示查询的向量化状态的高级视图。将enabled标志设置为true意味着启用了向量化,而enabledConditionsMet标志表示启用了向量化,因为hive.vectorized.execution.enabled属性设置为true。如果未启用向量化,enabledConditionsNotMet标志将显示原因。
2)然后在STAGE PLANS部分中,输出显示了每个查询执行任务的向量化状态。例如,一个查询可能有多个map和reduce任务,而且可能只有这些任务的一个子集是向量化的。在上面的示例中,Stage-1子部分显示只有一个map任务和一个reduce任务。map任务的Execution mode子部分显示任务是否向量化。在本例中,显示vectorized,这意味着向量化器能够成功地验证和向量化此map任务的所有操作符。
3)Map Vectorization子节显示map任务向量化的更多细节。具体来说,将显示影响map端向量化的配置,以及是否启用这些配置。如果配置是启用的,它们会在enabledConditionsMet中列出。如果配置没有启用,它们将在enabledConditionsNotMet中列出。在这个例子中,它显示查询执行的map端是启用的,因为hive.vectorized.use.vectorized.input.format属性被设置为true。这一子节还包含关于在查询执行的map端中使用的输入文件格式和适配器设置的详细信息。
4)Reduce Vectorization子节显示查询执行的reduce端没有向量化,因为hive.vectorized.execute.reduce.enabled属性被设置为false。本小节还显示了执行引擎没有设置为Tez或Spark,这是reduce端向量化所需的。在这个特定的示例中,要启用reduce端向量化,应该将执行引擎设置为Spark,并将hive.vectorized.execution.reduce.enabled属性设置为true。
通过对查询使用EXPLAIN VECTORIZATION语句,可以在部署查询之前查明是否会触发向量化,以及必须设置哪些属性才能启用它。
