使用不同的文件存储格式进行优化
HDFS上文件一般都是文本格式存储的,因为源数据本身就是文本格式的,但是在Hive执行过程中,可以采用其他优化的文本格式。
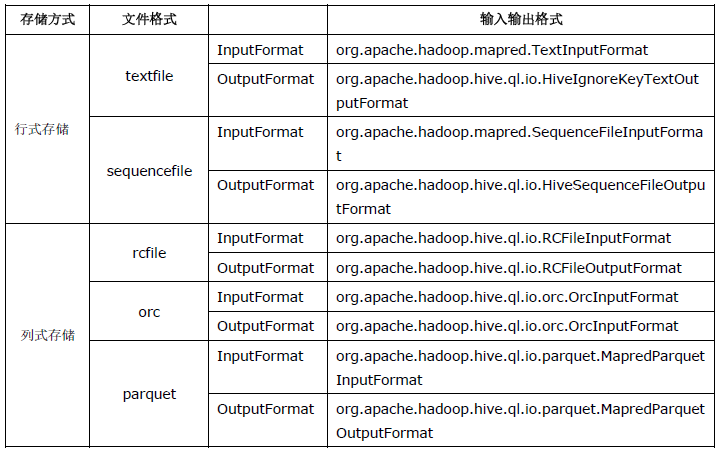
Hive中的文件格式常见的有:textfile文件格式、sequencefile(二进制序列化文件格式)、rcfile、orc、parquet。
Hive表的文件格式一般是在创建表时用stored as语句声明,如:
create table demo_textfile(
id int,
name string
) stored as textfile;
TextFile是Hive的默认文件格式,数据不做压缩,磁盘开销比较大,数据解析时开销也比较大。从本地文件向Hive load数据只能用textfile文件格式。
将一个基于文本的外部表转换为orc文件:
create table users_orc stored as orc tblproperties("ORC.COMPRESS"="SNAPPY")
as select user_id,location,age from users;
describe extended users_orc;
1)使用sequencefile文件存储表数据:
如果想保存大的数据集,同时节约磁盘空间,最好以sequencefile格式存储文件。
参考2)使用rcfile文件存储表数据:
rcfile,即Record Columnar File, 在磁盘上以压缩格式存储数据。
它提供了如下存储特性和处理优化:
- 1)数据的快速存储;
- 2)优化存储利用率;
- 3) 更好的查询处理。
rcfile格式在行和列方面都使得数据变平化。如果需要一个特定的列用于分析,它不会扫描全部的数据;相反,它只会返回所需的列。(参考)
3)使用ORC文件存储表数据:
ORC: Optimized Row Columnar。这是一个在Hive中存储和处理数据的高效地方式
以ORC格式存储的数据在Hive读、写和处理数据方面改善了性能
4)使用parquet文件存储表数据:
这是一个面向列的存储格式,在查询表中特定的列时非常高效。
