Spark概述
2009年,Spark诞生于伯克利大学AMPLab,最初属于伯克利大学的研究性项目。它于2010年正式开源,于2013年成为了Aparch基金项目,并于2014年成为Aparch基金的顶级项目, 整个过程不到五年时间。Apache Spark诞生以后,迅速发展成为了大数据处理技术中的佼佼者,站在了 Hadoop MapReduce 这个“巨人”的肩膀上, 已经成为大数据处理领域炙手可热的技术,其发展势头非常强劲。
配套视频:
Spark简介
大数据分析带来的挑战
在对大数据的分析中,会面临两种类型的困难:
- 一是对一个巨量计算平台的需求。
- 二是就是分析和理解大规模的数据(如果有了这样的平台)。
Python和R的困难在于它们无法扩展,因此难于处理大数据。HPC(high-performance computing,高性能计算)的困难在于它相对较低的抽象和难以使用。 为HPC环境编写的工具常常不能将内存中的数据模型与较低级别的存储模型分离。 例如,许多工具只知道如何在单个流中读取POSIX文件系统的数据,但是无法使工具自然地并行化运行,或者使用其他存储后端,比如数据库。
而Hadoop生态系统的出现,提供了一些抽象概念,允许用户将海量数据进行分布式存储,执行并行计算,并从故障中自动恢复。Hadoop生态系统的使用成本远远低于HPC。
Hadoop出现后,迅速成为许多大型分布式数据处理基础设施的基石。但是很快,人们意识到Hadoop的局限性。Hadoop解决方案最适合于特定类型的大数据需求,比如ETL。但是经常有这样的需求场景:数据工程师或分析人员必须对数据集进行交互式数据分析的即席查询。每当在Hadoop上运行查询时,Hadoop都会从HDFS中读取数据并加载到内存中,这个过程很慢。实际上,作业(Job)的运行速度是由网络和磁盘集群的传输速度决定的,而不是CPU和RAM的速度。如图所示:
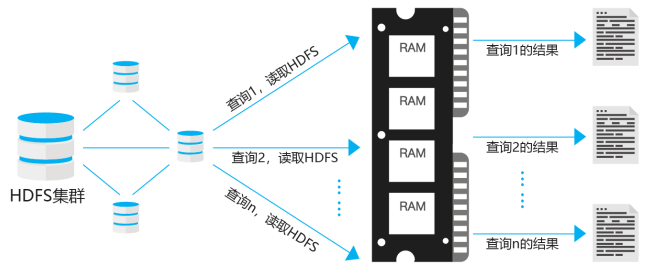
另外,Hadoop的MapReduce模型也不能很好地适应机器学习算法。机器学习在本质上是迭代的,但Hadoop MapReduce在迭代计算中有巨大的延迟,并不适合用于机器学习。由于MapReduce有一个受限制的编程模型,在Map和Reduce之间进行通信,中间结果需要存储在一个稳定的存储器中(而不是保存在内存中),然后在内存中重新加载用于后续的迭代。磁盘输入/输出的数量取决于算法中涉及的迭代次数,当保存和加载数据时随着序列化和反序列化而达到顶峰。总的来说,它的计算成本很高。下图这是种场景的描述:

因此,出现了很多解决方案,如Google's Pregel。新的解决方案不是要重新设计所有的算法,而是需要一个通用的引擎,可以利用大多数算法在分布式计算平台上进行内存计算,能够更快地执行迭代计算和即席数据分析。基于这样的需求,加州大学伯克利分校的AMPLab中开展了Spark项目。
将Spark用于大数据分析
Spark项目在AMP实验室取得成功后不久,于2010年被开源,并于2013年被转交给Apache软件基金会。Spark项目目前由Databricks所领导。
Spark与其他分布式计算平台相比有许多独特的优势,例如:
- 用于迭代机器学习和交互式数据分析的更快的执行平台。
- 用于批处理、SQL查询、实时流处理、图处理和复杂数据分析的单一技术栈。
- 通过隐藏分布式编程的复杂性,提供高级API来供用户开发各种分布式应用程序。
- 对各种数据源的无缝支持,如RDBMS、HBase、Cassandra、Parquet、MongoDB、HDFS、Amazon S3,等等。
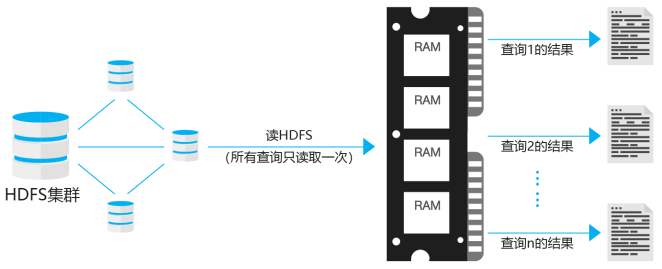
下图演示了Spark的内存计算模型。Spark一次性从HDFS中读取所有的数据并以分布式的方式缓存在计算机集群中各节点的内存中。
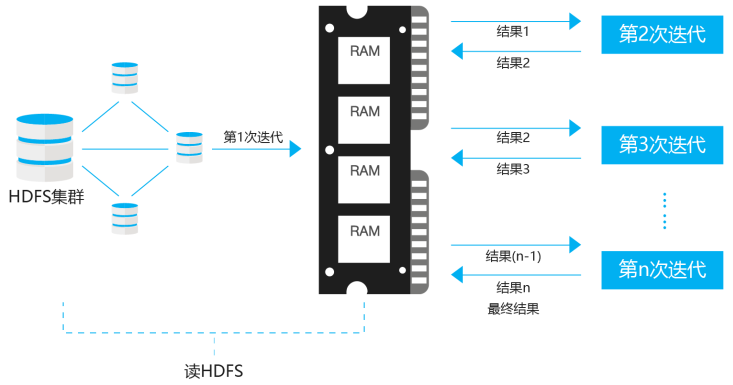
下图是Spark用于迭代算法的内存数据共享表示:
Spark隐藏了编写核心MapReduce作业的复杂性,并通过简单的函数调用提供了大部分功能。由于它的简单性,它能够迎合更广泛和更大的受众群体,比如数据科学家、数据工程师、统计学家,以及R /Python/Scala/Java开发人员。
由于Spark采用了内存计算,并采用函数式编程,提供了大量高阶函数和算子,因此它具有以下三个显著特性:速度、易用性和灵活性。
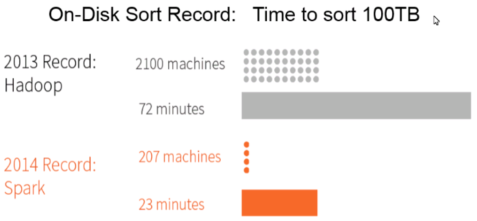
在2014年,Spark赢得了Daytona GraySort竞赛,该竞赛是对100 TB数据进行排序的行业基准(1万亿条记录)。来自Databricks的提交声称Spark能够以比之前的Hadoop MapReduce所创造的世界记录的速度快三倍的速度对100 TB的数据进行排序,并且使用的资源减少了10倍。
因为Scala编程语言的简洁性以及函数式编程和静态类型的结合,Spark的创建者为该项目选择了Scala语言。世界上最大的公开宣布的Spark集群拥有超过8000台机器。
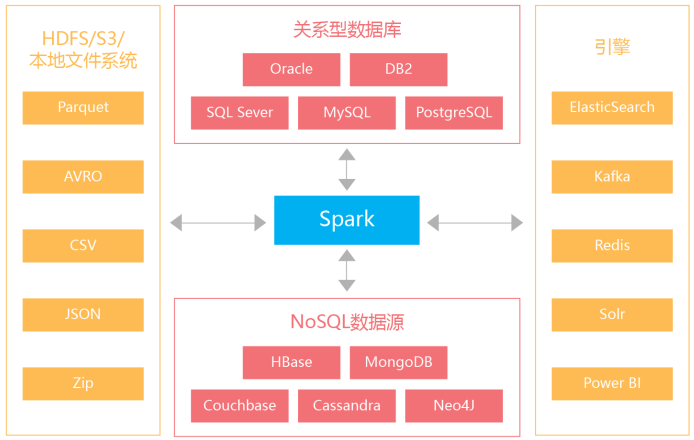
Spark可以连接到许多不同的数据源,包括文件(CSV,JSON,Parquet,AVRO)、MySQL、MongoDB、HBase和Cassandra。此外,它还可以连接到特殊用途的引擎和数据源,如ElasticSearch、Apache Kafka和Redis。这些引擎支持Spark应用程序中的特定功能,如搜索、流、缓存等。Spark提供了DataSource API以支持到各种数据源(包括自定义数据源)的Spark连接。
Spark官网地址
| 内容 | 地址 |
|---|---|
| Spark官网 | Spark官网 |
| Spark Scala API文档 | Spark Scala API |
| Spark Java API文档 | Spark Java API |
| Spark Python API文档 | Spark Pytho API |
| Spark R API文档 | Spark R API |
| Spark SQL内置函 | Spark SQL内置函数 |
