Spark资源调度策略
Spark应用程序的资源被作为executors(JVM进程)和CPU(任务槽-task slots)进程调度,然后将内存分配给它们。当前正在运行的集群的集群管理器和Spark调度程序授予用于执行Spark作业的资源。
集群管理器启动driver所请求的executor进程,并且当运行在集群部署模式下时启动driver进程本身。集群管理器还可以重新启动和停止它已经启动的进程,并且可以设置executor进程可以使用的最大CPU数量。
一旦应用程序的driver和executors开始运行,Spark调度程序就会直接与它们通信,并决定哪些executors将运行哪些tasks,这称为“作业调度”,它会影响集群中的CPU资源使用情况。间接地,它也会影响内存使用,因为在单个JVM中运行的任务越多,使用的堆内存就越多。然而,内存并不是像CPU那样在任务级别上直接管理的。Spark管理由集群管理器分配的JVM堆内存。
在集群中运行的每个Spark应用程序都会被分配一组专用的executors。如果在单个集群中运行多个Spark应用程序(或其他类型的应用程序),它们就会争夺集群的资源。
因此,存在两个层次的Spark资源调度:
- 集群资源调度:为不同的Spark应用程序的Spark executors分配资源。
- Spark资源调度:用于在单个应用程序内调度CPU和内存资源。
CPU资源分配策略
Spark分配CPU资源的方式有两种:FIFO(先进先出)调度和fair scheduling(公平调度)。可通过Spark参数spark.scheduler.mode设置调度器模式,它有两个可能的值:FAIR和FIFO。
(1)FIFO调度
“先到先服务”。请求资源的第一个job占用了所有必需的(和可用的)executor task slots(假设每个job作业只包含一个stage阶段)。如下图所示:
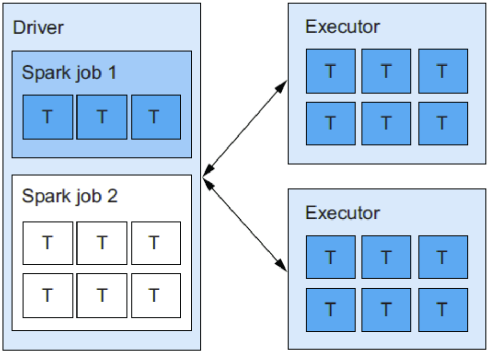
FIFO调度是默认的调度器模式,如果应用程序是一个只运行一个作业的单用户应用程序,那么它的效果最好。
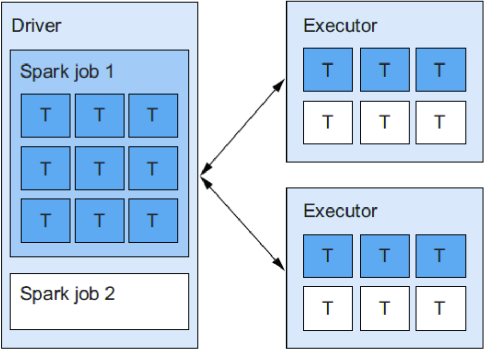
(2)FAIR调度
公平调度以循环的方式在竞争的Spark jobs中均匀地分配可用资源(executor线程)。对于同时运行多个作业的多用户应用程序来说,这是一个更好的选择。如下图所示:
Spark内存管理
要设置分配给executors的内存数量,使用spark.executor.memory参数。大小可以使用g和m做为后缀。默认的executor内存大小是1G。
Spark保留部分内存用于缓存的数据存储和临时shuffle数据。Spark为这些缓存数据和shuffle数据设置堆(heap),使用参数有spark.storage.memoryFraction(默认是0.6)和spark.shuffle.memoryFraction(默认是0.2)。因为堆的这些部分可以在Spark能够测量和限制它们之前增长,所以必须设置两个额外的安全参数:spark.storage.safetyFraction(默认是0.9)和spark.shuffle.safetyFraction(默认是0.8)。安全参数按指定的数量降低内存比例,如下图所示:
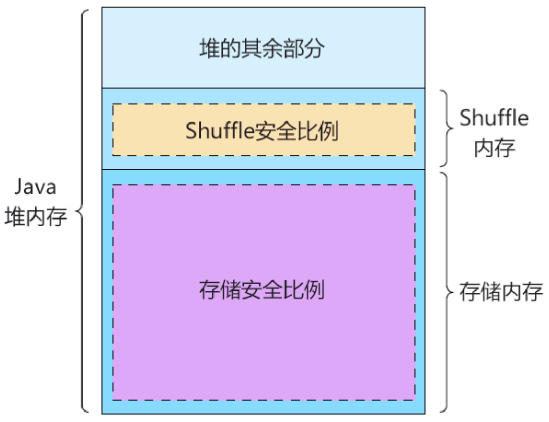
默认存储的堆的实际部分是0.6 x 0.9(安全系数乘以存储内存系数),等于54%。类似地,用于shuffle数据的堆的一部分是0.2 x 0.8(安全分数乘以shuffle内存分数),它等于16%。
然后,剩下30%的堆预留给其他Java对象和运行任务所需的资源(然而,应该只期望20%)。
可使用spark.driver.memory设置driver内存。当使用spark shell和spark-submit脚本(在集群和客户端部署模式中)启动应用程序时,这个参数就应用了。
如果从另一个应用程序(客户端模式)以编程方式启动,则使用-Xmx Java选项来设置包含进程的Java堆的大小上限。
在YARN上运行时,Spark的executors的内存布局如图所示:
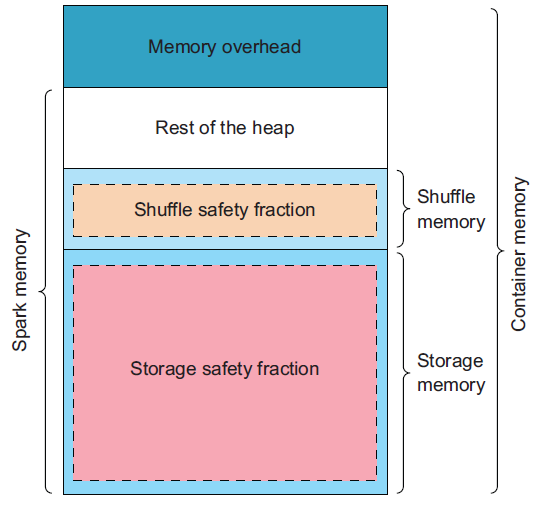
如果设置spark.executor.memoryOverhead的值不够高的话,会导致难以诊断的问题。确保指定至少1024 MB。
