使用Zeppelin进行交互式分析
对于公司的数据分析人员来说,虽然spark shell提供了交互式数据查询的功能,但是他们更喜欢使用的是基于web的notebook类工具。我们采用Zepplin作为Spark的交互式数据分析工具。
1、下载zeppelin安装包
下载地址:http://zeppelin.apache.org/download.html
选择图中所示的版本:
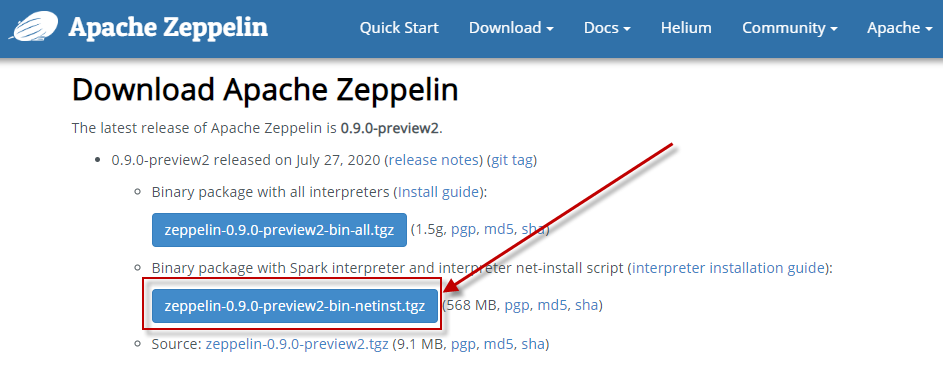
下载安装包到~/software目录下。(~代表用户主目录)
2、安装和配置zeppelin
2.1 将下载的安装包解压缩到~/bigdata目录下,并改名为zeppelin-0.8.0:
$ cd ~/bigdata $ tar xvf ~/software/zeppelin-0.8.0-bin-all.tgz $ mv zeppelin-0.8.0-bin-all zeppelin-0.8.0
2.2 配置环境变量:
$ cd $ sudo gedit /etc/profile
在文件最后,添加如下内容:
export ZEPPELIN_HOME=/home/hduser/bigdata/zeppelin-0.8.0 export PATH=$PATH:$ZEPPELIN_HOME/bin
保存文件并关闭。
2.3 执行/etc/profile文件使得配置生效:
$ source /etc/profile
2.4 打开conf/zeppelin-env.sh文件:(默认没有,从模板复制一份)
$ cd ~/bigdata/zeppelin-0.8.0/conf $ cp zeppelin-env.sh.template zeppelin-env.sh $ gedit zeppelin-env.sh
在文件最后添加如下两行内容:
export JAVA_HOME=/usr/local/jdk1.8.0_162 export SPARK_HOME=/home/hduser/bigdata/spark-2.3.2
2.5 打开zeppelin-site.xml文件:(默认没有,从模板复制一份)
$ cd ~/bigdata/zeppelin-0.8.0/conf $ cp zeppelin-site.xml.template zeppelin-site.xml $ gedit zeppelin-site.xml
修改如下两个属性,设置新的端口号9090和9443,以避免和Spark Web UI的端口造成冲突:
<property> <name>zeppelin.server.port</name> <value>9090</value> <description>Server port.</description> </property> <property> <name>zeppelin.server.ssl.port</name> <value>9443</value> <description>Server ssl port. (used when ssl property is set to true)</description> </property>
3、启动zeppelin服务
在终端窗口中,执行以下命令,启动zeppelin服务:
$ zeppelin-daemon.sh start
4、配置Spark解释器
说明:如果是使用Spark local模式,此一步骤省略。如果是使用Spark standalone模式,需要配置Spark解释器。
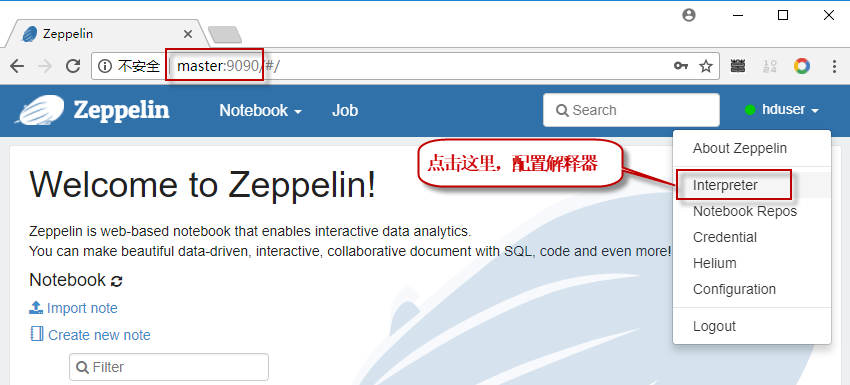
4.1 首先启动浏览器,在浏览器地址栏输入:http://192.168.190.128:9090/,打开访问界面,如下图。点击右上角的小三角按钮,打开下拉菜单,点击"Interpreter"菜单项,打开解释器配置界面。
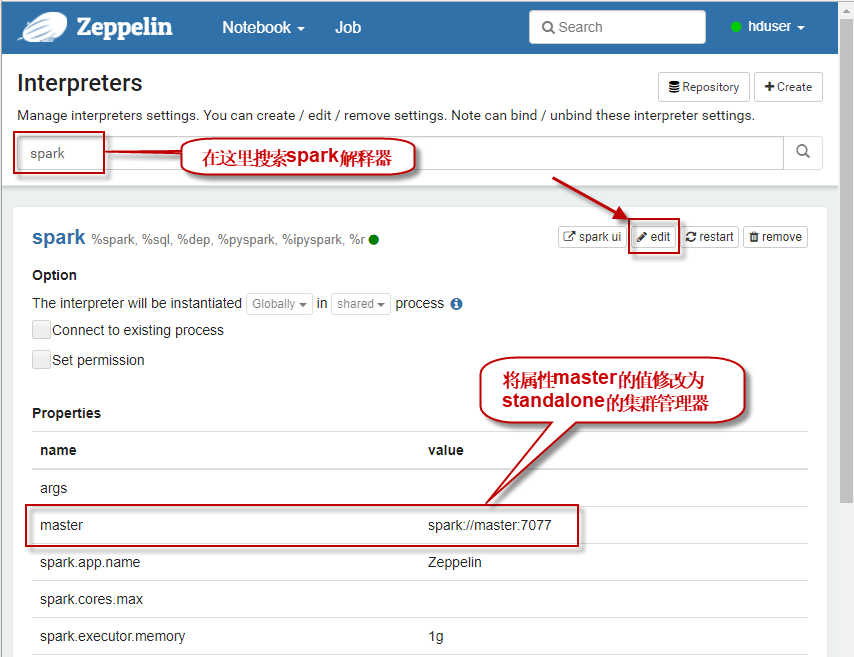
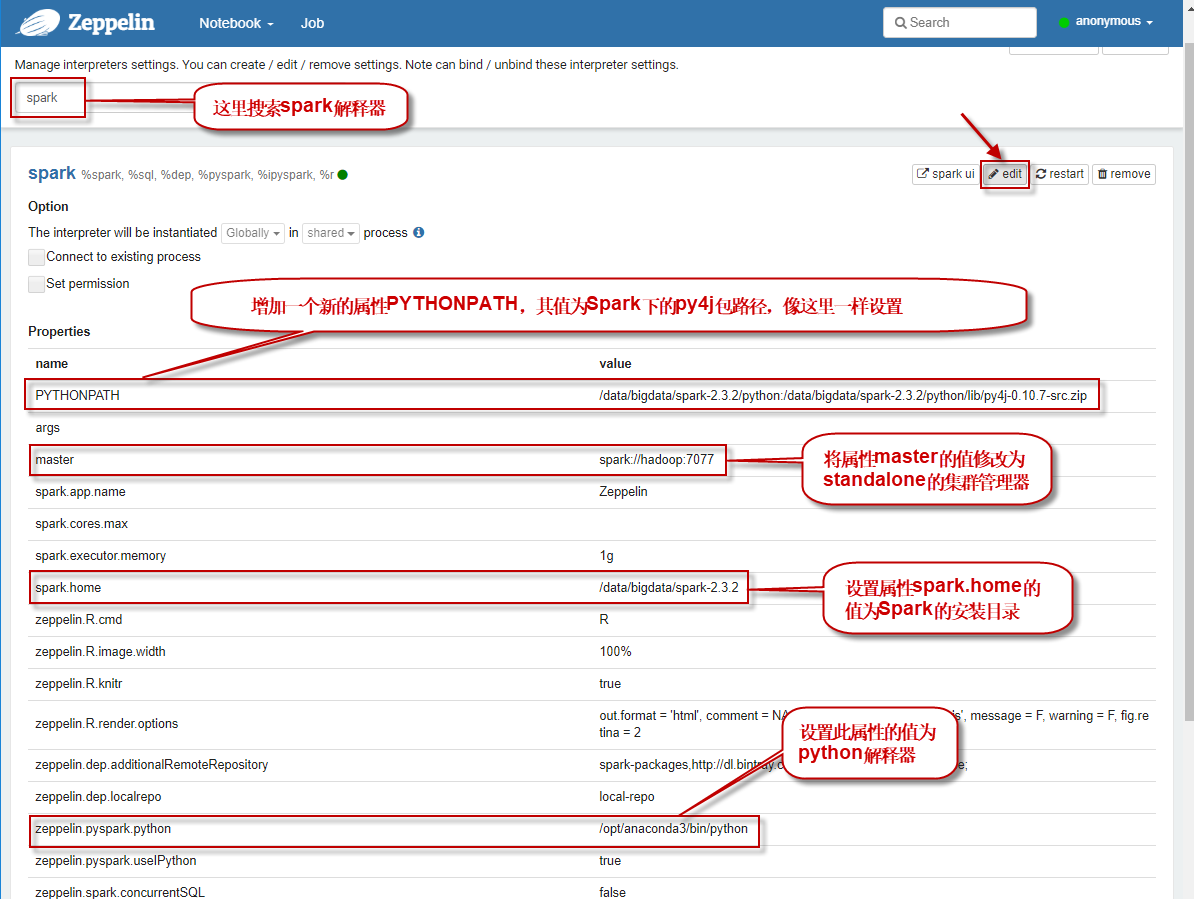
4.2 打开的解释器配置界面如下图所示。按图中所示找到spark解释器,然后修改master属性值为spark://master:7077(这实际上是连接到的集群管理器,我们这里使用的是spark standalone模式。这相当于启动Spark Shell时指定--master参数),然后单击【Save】按钮保存。其它参数酌情设置。
5、配置PySpark解释器
说明:如果是使用PySpark local模式,此一步骤省略。如果是使用PySpark standalone模式,需要配置Spark解释器。
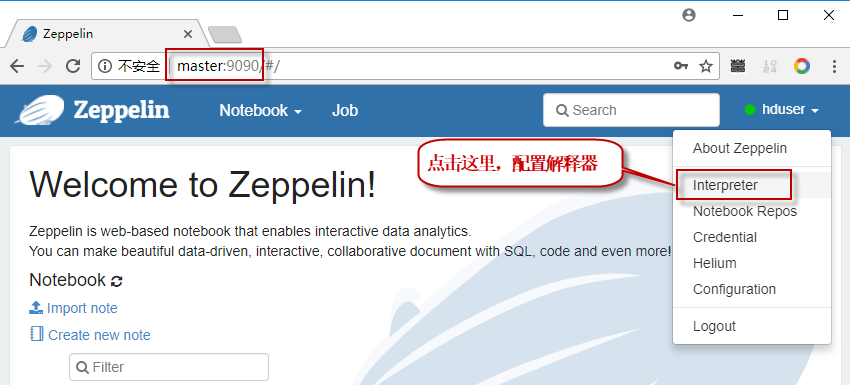
5.1 首先启动浏览器,在浏览器地址栏输入:http://192.168.190.128:9090/,打开访问界面,如下图。点击右上角的小三角按钮,打开下拉菜单,点击"Interpreter"菜单项,打开解释器配置界面。
5.2 打开的解释器配置界面如下图所示。按图中所示找到spark解释器,然后修改master属性值为spark://master:7077(这实际上是连接到的集群管理器,我们这里使用的是spark standalone模式。这相当于启动Spark Shell时指定--master参数),然后单击【Save】按钮保存。其它参数酌情设置。
6、创建和notebook文件
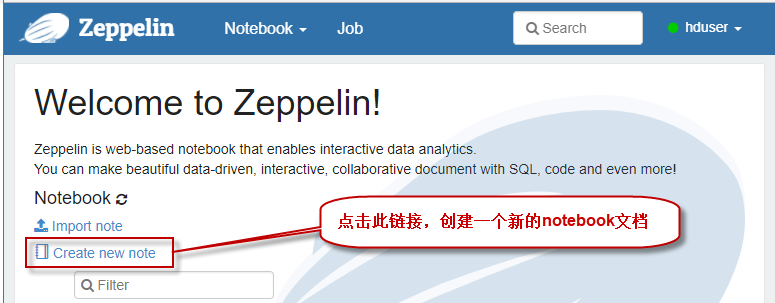
6.1 回到浏览器zeppelin首页,点击按钮,创建一个新的notebook文件,如下图所示:
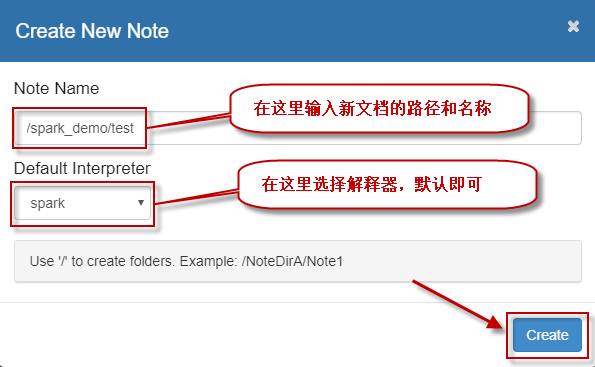
6.2 然后在弹出的创建窗口,填写相应信息,然后单击【Create】按钮即可:
7、执行Spark交互式操作-Scala语言
说明:如果是在standalone模式下使用Zeppelin,请先启动Spark集群。
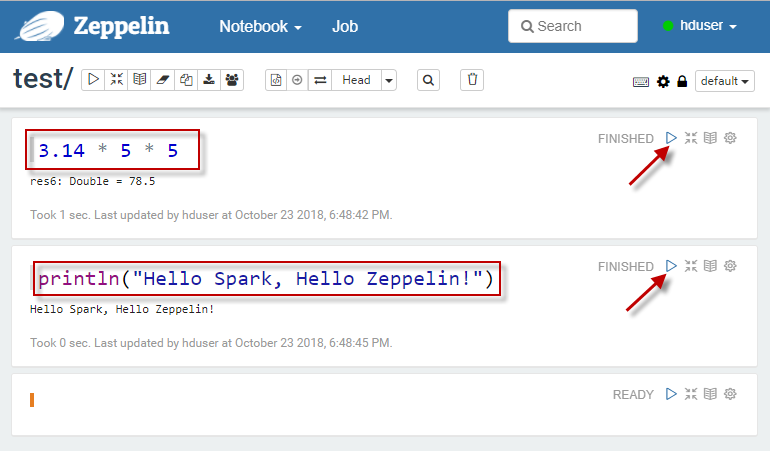
在新打开的notebook界面,执行Spark代码,如下图所示:
8、执行Spark交互式操作-Python语言
8.1 新创建一个notebook。
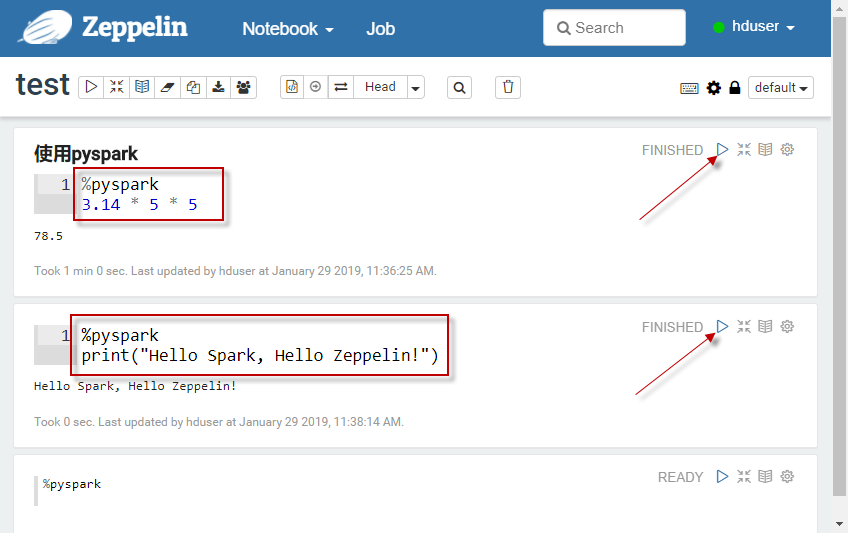
8.2 在新打开的notebook界面,执行Python代码。需要在第一行键入%pyspark,以告诉zeppelin使用pyspark解释器。如下图所示:
9、关闭zeppelin服务
在终端窗口中,执行以下命令,停止zeppelin服务:
$ zeppelin-daemon.sh stop
