实验:使用Spark Shell
在进行数据分析的时候,通常需要进行交互式数据探索和数据分析。为此,Spark提供了一个交互式的工具Spark Shell。通过Spark Shell,用户可以和Spark进行实时交互,以进行数据探索、数据清洗和整理以及交互式数据分析等工作。
spark-shell命令及其常用的参数如下:
$ ./bin/spark-shell [options]
要查看完整的参数选项列表,可以执行“spark-shell --help”命令,如下:
$ spark-shell --help
Spark的运行模式取决于传递给SparkContext的Master URL的值。参数选项"--master"表示当前的Spark Shell要连接到哪个master(即告诉Spark使用哪种集群类型)。
如果是local[*],就是使用本地模式启动spark-shell,其中,中括号内的星号表示需要使用几个CPU核心(core),也就是启动几个线程模拟Spark集群。可选地,默认为local。
当运行spark-shell命令时,Master URL(即--master参数)的值如下表所示:


1、启动和退出Spark Shell
以下操作均在终端窗口中进行。
(1)启动Spark Shell方式一:local模式
$ cd ~/bigdata/spark-2.4.5
$ ./bin/spark-shell
然后可以看到如下的启动过程:
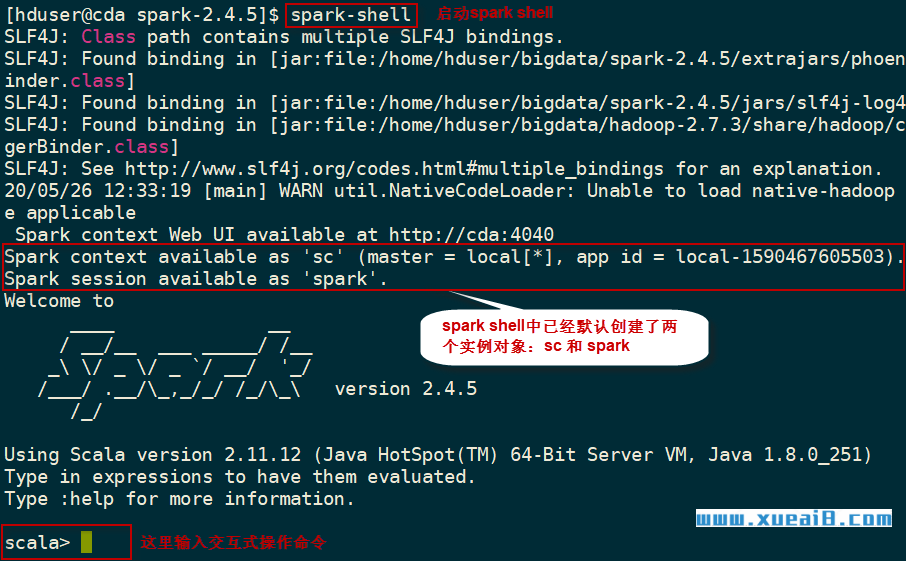
从上图中可以看出,Spark Shell在启动时,已经帮我们创建好了SparkContext对象的实例sc和SparkSession对象的实例spark,我们可以在Spark Shell中直接使用sc和spark这两个对象。另外,默认情况下,启动的Spark Shell采用local部署模式。
在创建SparkContext对象的实例sc之后,它将等待资源。一旦资源可用,sc将设置内部服务并建立到Spark执行环境的连接。
退出Spark Shell,使用如下命令:
scala> :quit
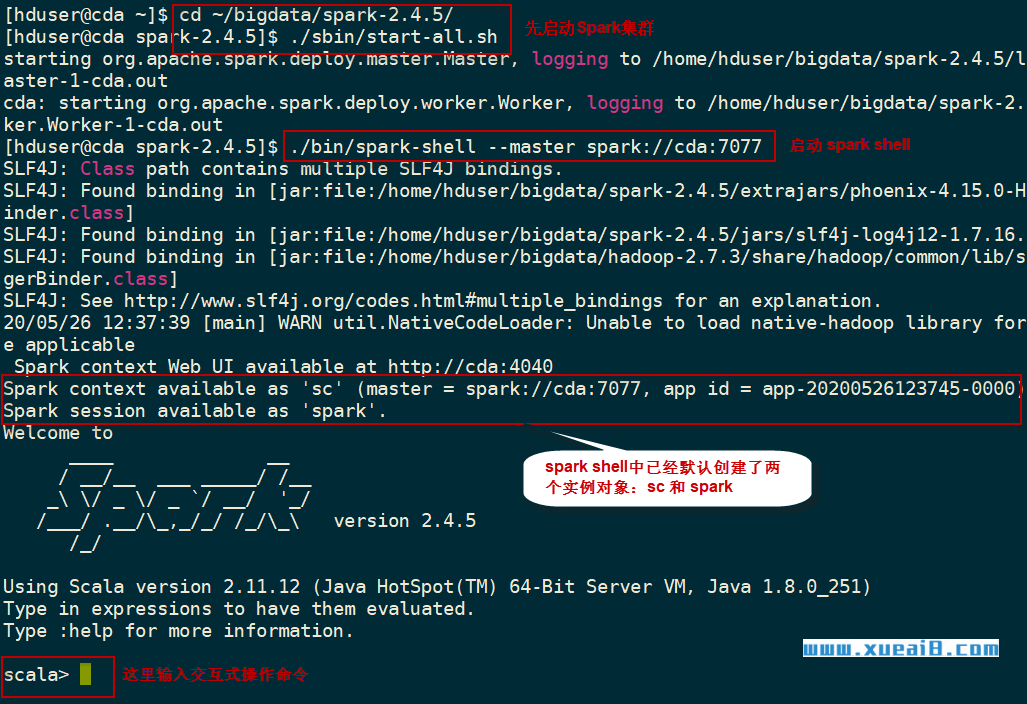
(2)启动Spark Shell方式二:standalone模式
首先要确保启动了Spark集群,然后指定--master spark://cda:7077参数:
$ cd ~/bigdata/spark-2.4.5
$ ./sbin/start-all.sh
$ ./bin/spark-shell --master spark://cda:7077
在Master URL中指定的cda是当前的机器名。请读者在实验时替换为自己的机器名。
2、Spark Shell常用命令
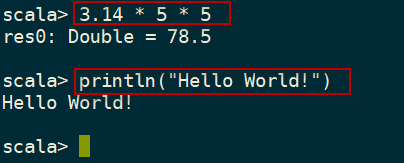
可以在Spark Shell里面输入scala代码进行调试:
可以Spark Shell中键入以下命令,查看Spark Shell常用的命令:
scala> :help
如下图所示:

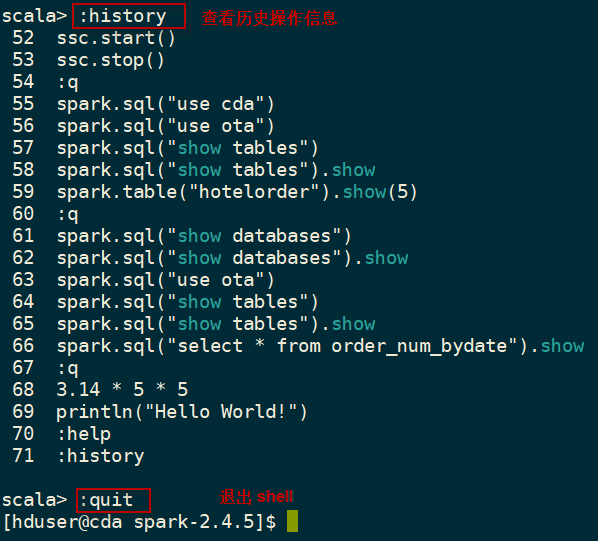
例如,可以使用":history"命令查看历史操作记录,使用":quit"命令退出shell界面。
3、认识SparkContext和SparkSession
在Spark 2.0中引入了SparkSession类,以提供与底层Spark功能交互的单一入口点。这个类具有用于从非结构化文本文件读取数据的API,以及各种格式的结构化和二进制数据,包括JSON、CSV、Parquet、ORC等。此外,SparkSession还提供了检索和设置与spark相关的配置的功能。
SparkContext在Spark 2.0中,成为了SparkSession的一个属性对象。
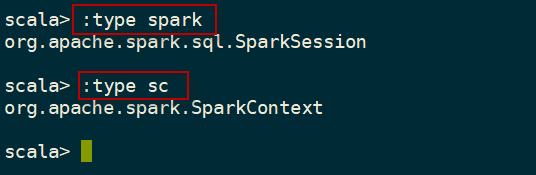
一旦一个Spark shell成功启动,它就会初始化一个SparkSession类的实例,名为spark,以及一个SparkContext类的实例,名为sc。 这个spark变量和sc变量可以在Spark shell中直接使用。我们可以使用:type命令来验证这一点。
scala> :type spark
scala> :type sc
执行过程如下图所示:
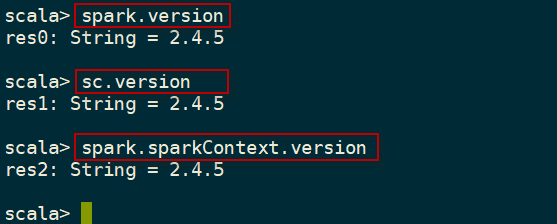
查看当前使用的Spark版本号,使用如下命令:
scala> spark.version
scala> sc.version
执行过程如下图所示:
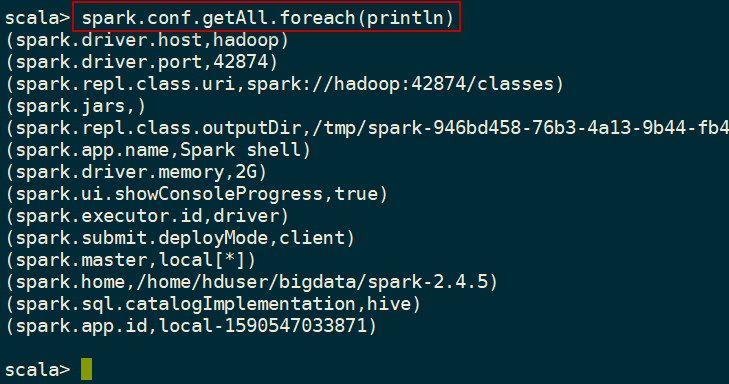
要查看在Spark shell中配置的默认配置,可以访问Spark的conf变量。下面的命令显示Spark shell中默认的配置信息:
scala> spark.conf.getAll.foreach(println)
执行过程如下图所示:
4、Spark Web UI
每次初始化SparkSession对象时,Spark都会启动一个web UI,提供关于Spark环境和作业执行统计信息的信息。 web UI默认端口是4040,但是如果这个端口已经被占用(例如,被另一个Spark web UI),Spark会增加该端口号,直到找到一个空闲的。
在启动一个Spark shell时,将看到与此类似的输出行(除非关闭了INFO log消息):
Spark context Web UI available at http://cda:4040
一个示例Spark web UI欢迎页面如下图所示。这个web UI是从一个Spark shell启动的,所以它的名字被设置为Spark shell,如图右上角所示。
在运行spark-submit命令时,也可以在命令行上设置它,使用--conf spark.app.name=new_name,但不能在启动Spark shell时更改应用程序名称。 在这种情况下,它总是默认为Spark shell。

在Spark web UI的Environment页面,可以查看影响Spark应用程序的配置参数的完整列表。如下图所示:

