Spark SQL编程模型
Spark SQL是Spark用于处理结构化和半结构化数据的接口,允许使用关系操作符表示分布式内存计算。结构化数据被认为是任何有模式的数据,如JSON、Hive表、Parquet。模式意味着为每个记录拥有一组已知的字段。半结构化数据是指模式和数据之间没有分离。
Spark SQL被设计用来集成关系型处理和函数式编程的功能,这样复杂的逻辑就可以在分布式计算设置中实现、优化和扩展。
Spark SQL提供了使用结构化和半结构化数据的三个主要功能:
- 它提供了由Python、Java和Scala语言所支持的DataFrame/Dataset抽象,以简化使用结构化数据集的工作。DataFrame/Datase类似于关系数据库中的表。
- 它可以读写各种结构化格式的数据(如JSON、Hive表、Parquet)。
- 它允许在Spark程序内部和通过标准数据库连接器(JDBC/ ODBC)连接到Spark SQL的外部工具(如Tableau等商业智能工具)中使用SQL查询数据。
Spark SQL的主要数据抽象是Dataset,它表示结构化数据(具有已知模式的记录)。这种结构化数据表示Dataset支持使用存储在JVM堆外的托管对象中的压缩柱状格式的紧凑二进制表示。它可以通过减少内存使用和GC来加快计算速度。
Spark SQL编程模型
所有的Spark SQL应用程序都以特定的步骤来工作。这些工作步骤如下图所示:
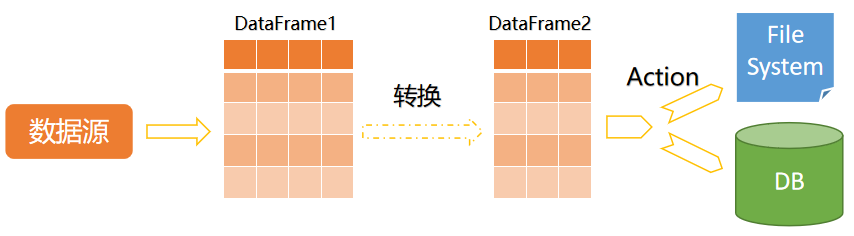
也就是说,每个Spark SQL应用程序都由相同的基本部分组成:
- 从数据源加载数据,构造DataFrame/Dataset;
- 对DataFrame/Dataset执行转换(transformation)操作;
- 将最终的DataFrame/Dataset存储到指定位置。
【示例】加载json文件中的人员信息,并进行统计。
下面我们实现一个完整的的Spark SQL应用程序。请按以下步骤执行。
1)准备数据源文件。
Spark安装目录中自带了一个people.json文件,位于“examples/src/main/resources/”目录下。其内容如下:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
我们将这个people.json文件,拷贝到项目的resources目录下。
2)创建一个Spark项目,并创建一个Scala源文件,编辑代码如下:
import org.apache.spark.sql.SparkSession
/**
* Created by www.xueai8.com
*
* Spark SQL编程模型
* 实现: 加载json文件中的人员信息,并进行计算。
*/
object Demo01 {
def main(args: Array[String]): Unit = {
// 1)创建SparkSession
val spark = SparkSession
.builder()
.master("local[*]")
.appName("Spark SQL basic example")
.getOrCreate()
// 用于隐式转换,如将rdd转换为DataFrame
import spark.implicits._
// 2)加载数据源,构造DataFrame
val input = "./src/main/resources/people.json"
val df = spark.read.json(input)
// 3)执行转换操作
// -- 找出年龄超过21岁的人
val resultDF = df.where($"age" > 21)
resultDF.show() // 显示DataFrame数据
// 4)将结果保存到csv文件中
val output = "tmp/people-output"
resultDF.write.format("csv").save(output)
}
}
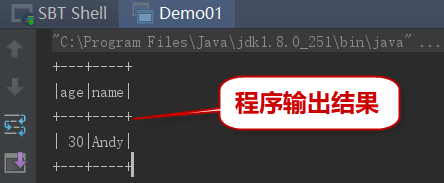
3)执行以上代码,在控制台中可以看到输出结果如下:
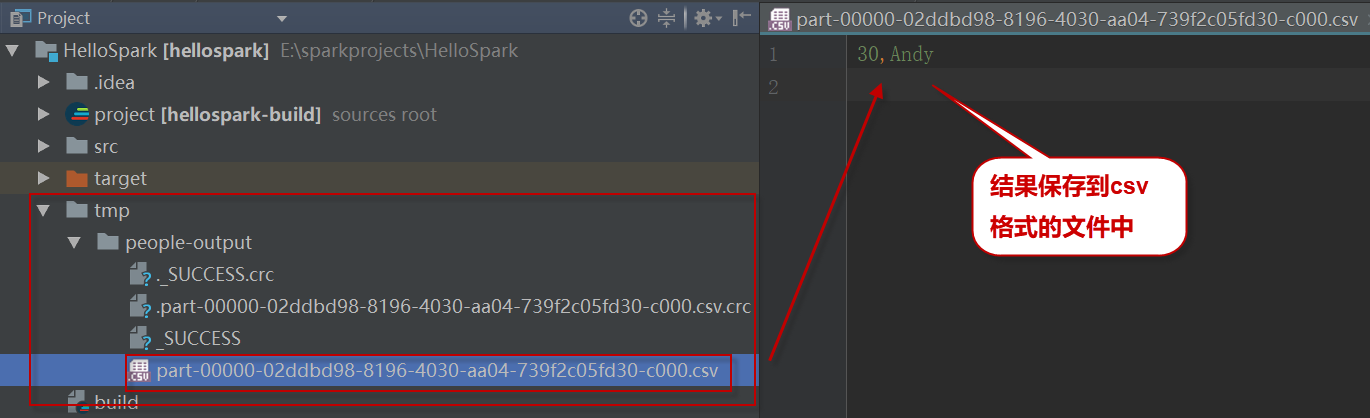
4)查看存储结果的csv文件。如下图中所示:
在本例中,我们使用了本地文件系统。大家可自行修改代码,使用HDFS文件系统。
