案例_银行客户数据分析
在本案例中,我们尝试对某银行客户数据集进行分析。部分客户数据样例如下:
"age";"job";"marital";"education";"default";"balance";"housing";"loan";"contact";"day";"month";"duration";"campaign";"pdays";"previous";"poutcome";"y" 58;"management";"married";"tertiary";"no";2143;"yes";"no";"unknown";5;"may";261;1;-1;0;"unknown";"no" 44;"technician";"single";"secondary";"no";29;"yes";"no";"unknown";5;"may";151;1;-1;0;"unknown";"no" 33;"entrepreneur";"married";"secondary";"no";2;"yes";"yes";"unknown";5;"may";76;1;-1;0;"unknown";"no" 47;"blue-collar";"married";"unknown";"no";1506;"yes";"no";"unknown";5;"may";92;1;-1;0;"unknown";"no" ......
其中第一行是标题行。每个字段之间用分号(;)分隔。
加载数据文件
我们的银行客户数据集位于PBLP平台的~/bigdata/data/spark/bank-full.csv文件。执行如下语句加载:
val filePath = "file:///home/hduser/data/spark/bank-full.csv" val bankText = sc.textFile(filePath) bankText.take(2).foreach(println)
在上面的代码中,我们将数据加载到RDD[String]中,然后查看其中前两行。输出内容如下所示:
"age";"job";"marital";"education";"default";"balance";"housing";"loan";"contact";"day";"month";"duration";"campaign";"pdays";"previous";"poutcome";"y" 58;"management";"married";"tertiary";"no";2143;"yes";"no";"unknown";5;"may";261;1;-1;0;"unknown";"no"
从输出内容可以看到,数据集的第一行是标题行。
定义case class
下面定义case class,代表银行客户数据类型。
case class Bank(age:Integer, // 客户年龄
job:String, // 客户职业
marital:String, // 客户婚姻状况
education:String, // 受教育程序
balance:Integer) // 存款余额
注意到,这里我们没有为原始数据集中所有列定义字段,只定义了我们用到的这些字段。
数据预处理
对于这个数据集,我们需要进行一些预处理工作。主要包括两方面:
- 1) 过滤掉标题行,并对其余每行进行拆分,遇到了case class Bank。
- 2) 注意到原始数据中字符串类型的字段都带有双引号,我们需要在分析之前把这些双引号删除掉。
val bank = bankText
.map(s => s.split(";")) // 拆分
.filter(s => s(0) != "\"age\"") // 过滤标题行
// 每行转换为一个Bank对象,同时删除字段中的双引号
.map(s => Bank(s(0).replaceAll("\"","").replaceAll(" ", "").toInt,
s(1).replaceAll("\"",""),
s(2).replaceAll("\"",""),
s(3).replaceAll("\"",""),
s(5).replaceAll("\"","").toInt)
)
转换为DataFrame
执行下面的代码,将上面的RDD[Bank]转换为DataFrame:
val bankDF = bank.toDF() // 查看前5行记录 bankDF.show(5)
执行以上代码,输出内容如下:
+---+------------+-------+---------+-------+ |age| job|marital|education|balance| +---+------------+-------+---------+-------+ | 58| management|married| tertiary| 2143| | 44| technician| single|secondary| 29| | 33|entrepreneur|married|secondary| 2| | 47| blue-collar|married| unknown| 1506| | 33| unknown| single| unknown| 1| +---+------------+-------+---------+-------+ only showing top 5 rows
注册临时视图
将上面预处理过的DataFrame注册为临时视图bank_tb,以便进一步分析。
// 注册临时视图
bankDF.createOrReplaceTempView("bank_tb")
探索性分析
首先查看有多少客户信息(数据集大小):
bankDF.count
执行以上代码,统计结果如下:
45211
可以看到,数据集中共有45211条客户信息。
查看年龄小于30岁的客户信息:
spark.sql("select * from bank_tb where age<30").show
执行以上代码,统计结果如下:
+---+-----------+--------+---------+-------+ |age| job| marital|education|balance| +---+-----------+--------+---------+-------+ | 28| management| single| tertiary| 447| | 29| admin.| single|secondary| 390| | 28|blue-collar| married|secondary| 723| | 25| services| married|secondary| 50| | 25|blue-collar| married|secondary| -7| | 29| management| single| tertiary| 0| | 24| technician| single|secondary| -103| | 27| technician| single| tertiary| 0| | 29| services|divorced|secondary| 31| | 29| admin.| single|secondary| 818| | 28| unemployed| single| tertiary| 0| | 23|blue-collar| married|secondary| 94| | 26| student| single|secondary| 0| | 26| admin.| single|secondary| 82| | 28|blue-collar| married| primary| 324| | 22|blue-collar| single|secondary| 0| | 24| student| single|secondary| 423| | 24| student| single|secondary| 82| | 27| services| married|secondary| 8| | 23| student| single|secondary| 157| +---+-----------+--------+---------+-------+ only showing top 20 rows
统计小于30岁的年青客户的按年龄客户数量分布:
spark.sql("""select age,count(age) as total_ages
from bank_tb
where age<30
group by age
order by age"""
).show
执行以上代码,输出内容如下所示:
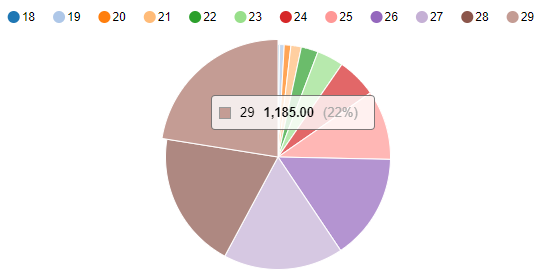
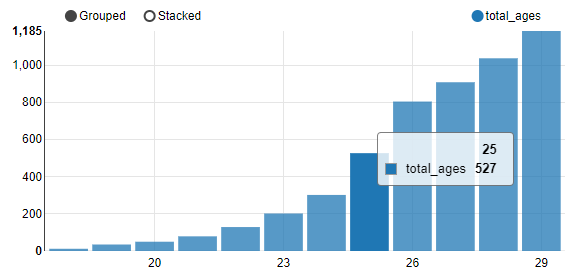
+---+----------+ |age|total_ages| +---+----------+ | 18| 12| | 19| 35| | 20| 50| | 21| 79| | 22| 129| | 23| 202| | 24| 302| | 25| 527| | 26| 805| | 27| 909| | 28| 1038| | 29| 1185| +---+----------+
可视化"年龄-人数"分布:饼状图。
%sql select age,count(age) as total_ages from bank_tb where age<30 group by age order by age
执行上面的分析语句,可以看到如下的分布图:
可视化"年龄-人数"分布:柱状图。
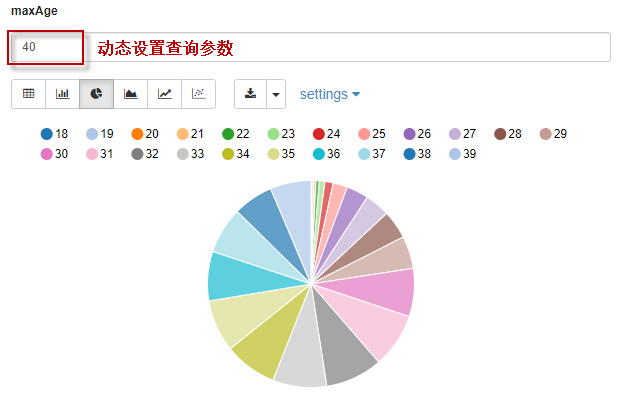
还可以动态修改查询参数。例如,下面代码在执行时,可以动态设置age的参数值:
%sql
select age,count(age) as total_ages
from bank_tb
where age<${maxAge=30}
group by age
order by age
我们将过滤条件设为age<40,再次执行,查询结果如下图所示:
下面根据婚姻状况的不同查询对应的年龄分布:
%sql
select age, count(1)
from bank_tb
where marital="${marital=single,single(未婚)|divorced(离婚)|married(已婚)}"
group by age
order by age
当选择查询条件是“未婚”时,查询结果如下图所示:
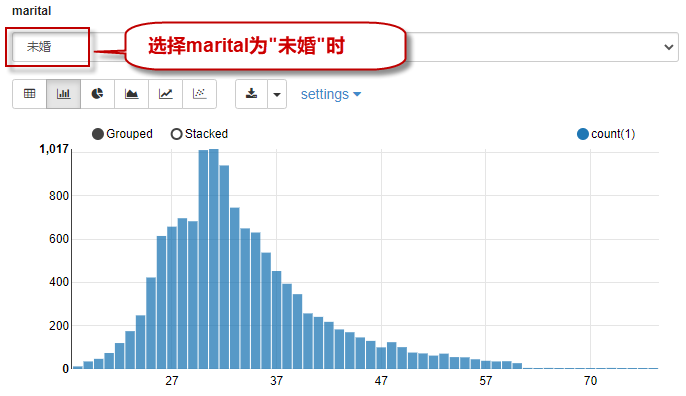
当选择查询条件是“离婚”时,查询结果如下图所示:
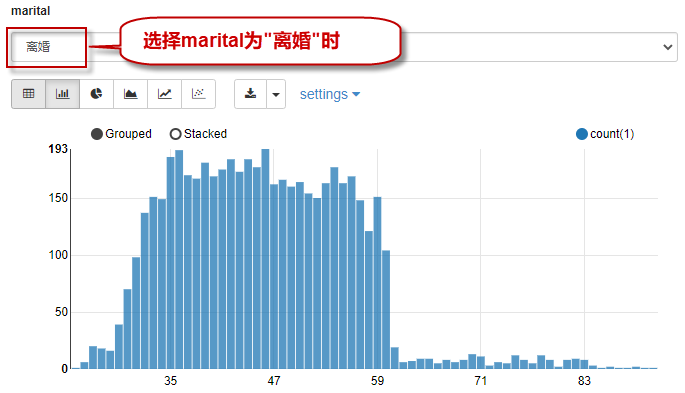
当选择查询条件是“已婚”时,查询结果如下图所示:
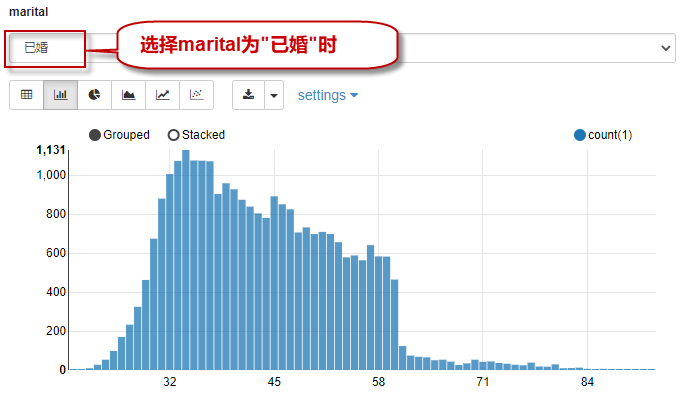
那么,客户的婚姻状况共有几种呢?
bankDF.select("marital").distinct.show
执行上面的代码,可以看到如下的输出:
+--------+ | marital| +--------+ |divorced| | married| | single| +--------+
即共有三种婚姻状况。
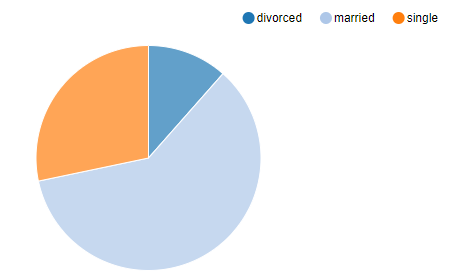
三种婚姻状况在客户中的占比分别是多少?
%sql select marital,count(1) from bank_tb group by marital
可视化显示如下: