Spark GraphX图处理库简介
数据通常以记录或行集合的形式存储和处理。它表示为一个二维表,数据分为行和列。然而,集合或表不是表示数据的唯一方法。有时,图比集合提供更好的数据表示。
对于面向图的数据,图为处理数据提供了易于理解和直观的模型。此外,还可以使用专门的图算法来处理面向图的数据。这些算法为不同的分析任务提供了有效的工具。
图(graph),作为链接对象的数学概念,由顶点(vertices,图中的对象)和连接顶点的边(edges)组成。
一旦表示为图,有些问题就变得更容易解决;它们自然地产生了图算法。例如,使用传统的数据组织方法(如关系数据库)呈现分层数据会是很复杂的,那么就可以用图来简化。除了使用它们来代表社交网络和网页之间的链接外,图算法还在生物学、计算机芯片设计、旅行、物理、化学等领域都有应用。
首先介绍一下本章中用到的基本图相关术语。
1. 图基本概念
图是一种数学结构,用来建模对象之间的关系。图是由顶点和连接它们的边组成的。顶点是对象,而边是它们之间的关系。顶点是图中的一个节点。一条边连接图中的两个顶点。一般来说,顶点代表一个实体,边代表两个实体之间的关系。图在概念上等价于顶点和边的集合。
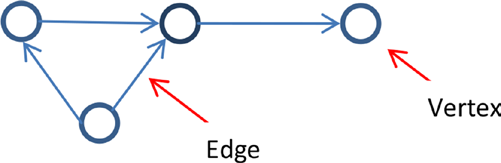
图可以有方向也可以无方向。 无向图是具有没有方向的边的图。无向图中的边没有源顶点或目标顶点。如下图所示,用户Bob和Carol构成图的顶点,它们之间的关系构成边:
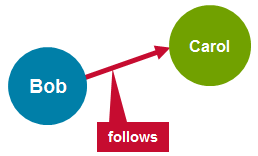
有向图就是边具有方向的图。有向图中的边具有源顶点和目标顶点。例如,Twitter follower就是一个有向图。用户Bob可以follow用户Carol,而不需要暗示用户Carol也follow用户Bob。
有向多图是一个有向图,它包含由两条或多条平行边连接的顶点对。有向多图中的平行边是具有相同起始和终止顶点的边。它们用于表示一对顶点之间的多个关系。
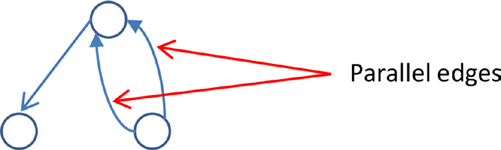
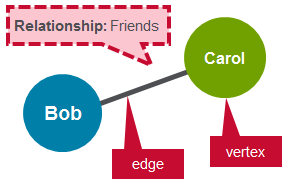
属性图是一个有向多图,它具有与顶点和边相关联的数据。属性图中的每个顶点都有一个或多个属性。类似地,每条边都有一个标签或属性。属性图如下所示:

属性图为处理面向图的数据提供了丰富的抽象。它是用图建模数据的最流行的形式。下面的图显示了一个属性图,表示公司中的两个员工及其关系。

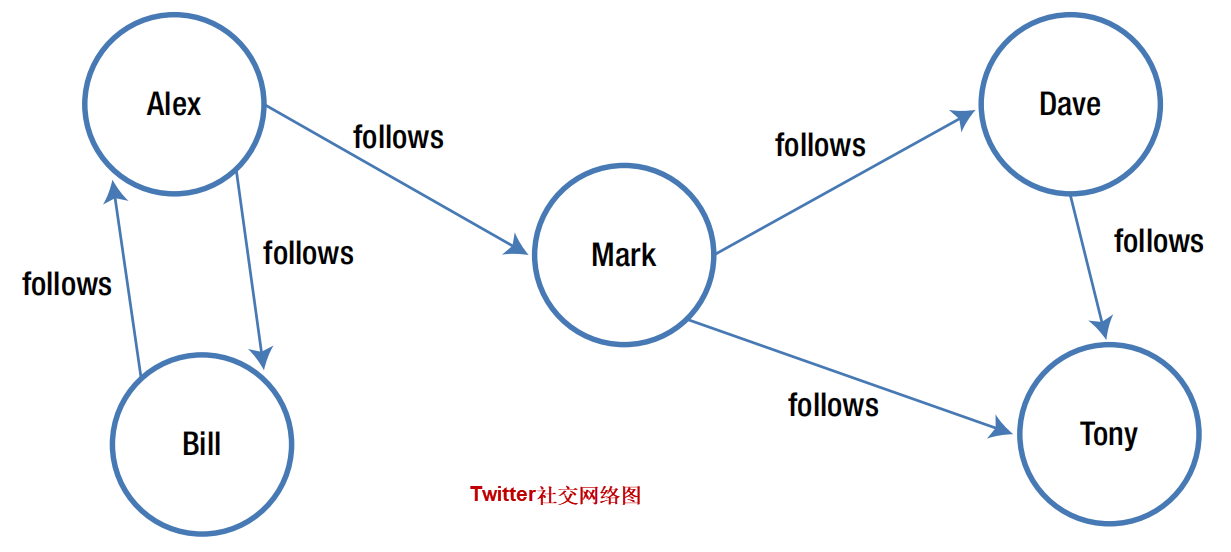
属性图的另一个例子是表示Twitter上的社交网络的图。用户具有姓名、年龄、性别和位置等属性。此外,用户可以关注其他用户,并可能有追随者。在表示Twitter上的社交网络的图中,顶点表示用户,边表示“关注”关系。下图显示了一个简单的示例。
2. Spark GraphX图处理库
Spark GraphX是一个分布式图分析框架,它是用于图并行计算的Spark组件,扩展了Spark以用于大规模图处理。它建立在一个称为“图论”的数学分支上,为图分析提供了比Spark Core API更高层次的抽象。Spark GraphX基于Spark平台提供了对图计算和图挖掘简洁易用的接口,极大的方便了对分布式图处理的需求。
GraphX的核心抽象是Resilient Distributed Property Graph,一种顶点和边都带属性的有向多图,我们称为“Spark属性图”。它扩展了Spark RDD的抽象,有Table和Graph两种视图,而只需要一份物理存储。两种视图都有自己独有的操作符,从而获得了灵活操作和执行效率。(注:GraphX基于RDD)
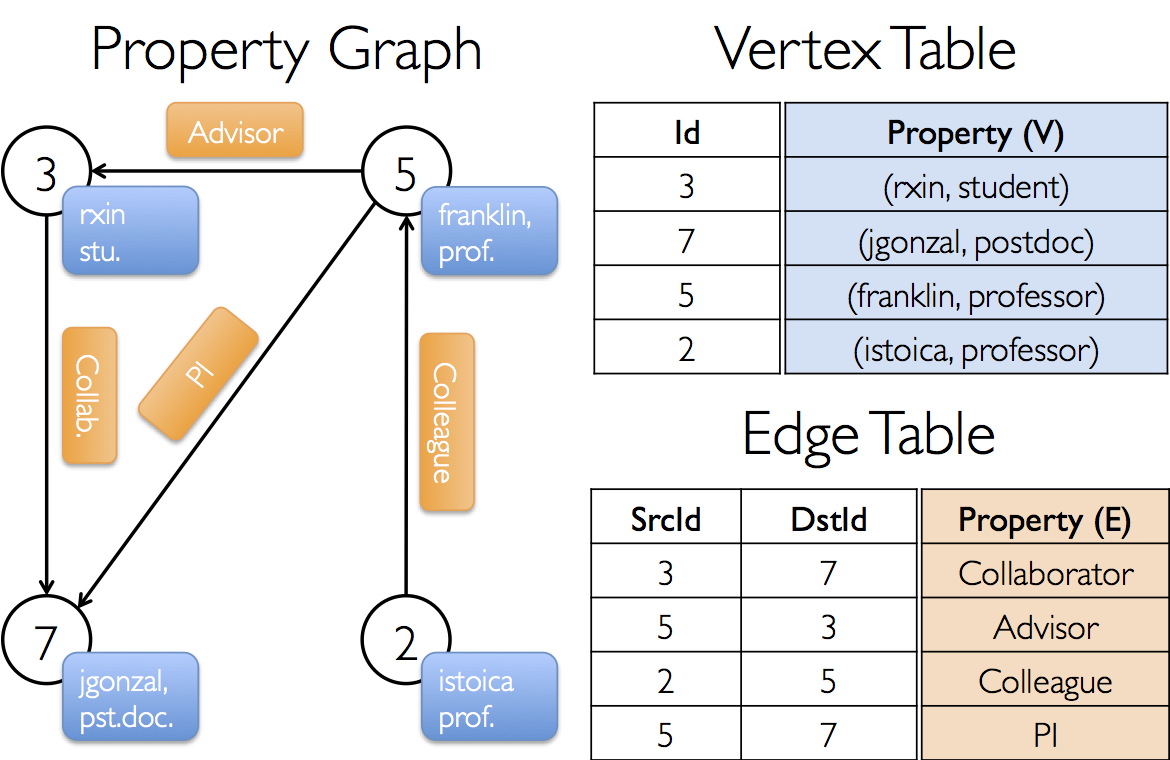
对Graph视图的所有操作,最终都会转换成其关联的Table视图的RDD操作来完成。一个图的计算在逻辑上等价于一系列RDD的转换过程。因此,Graph最终具备了RDD的3个关键特性:不变性、分布性和容错性。其中最关键的是不变性。逻辑上,所有图的转换和操作都产生了一个新图;物理上,GraphX会有一定程度的不变顶点和边的复用优化,对用户透明。
两种视图底层共用的物理数据,由RDD[VertexPartition]和RDD[EdgePartition]这两个RDD组成。点和边实际都不是以表Collection[tuple]的形式存储的,而是由VertexPartition/EdgePartition在内部存储一个带索引结构的分片数据块,以加速不同视图下的遍历速度。不变的索引结构在RDD转换过程中是共用的,降低了计算和存储开销。
图的分布式存储采用点分割模式,而且使用partitionBy方法,由用户指定不同的划分策略。
在Spark GraphX中,边是有方向的,并且边和顶点都有附属于它们的属性对象。顶点表示对象,边表示这些对象之间的各种关系。例如,在包含关于网页和链接的数据的图中,附加到顶点的属性对象可能包含关于网页的URL、标题、日期等的信息,并且附加到边的属性对象可能包含对链接的描述(一个 HTML标记的内容)。

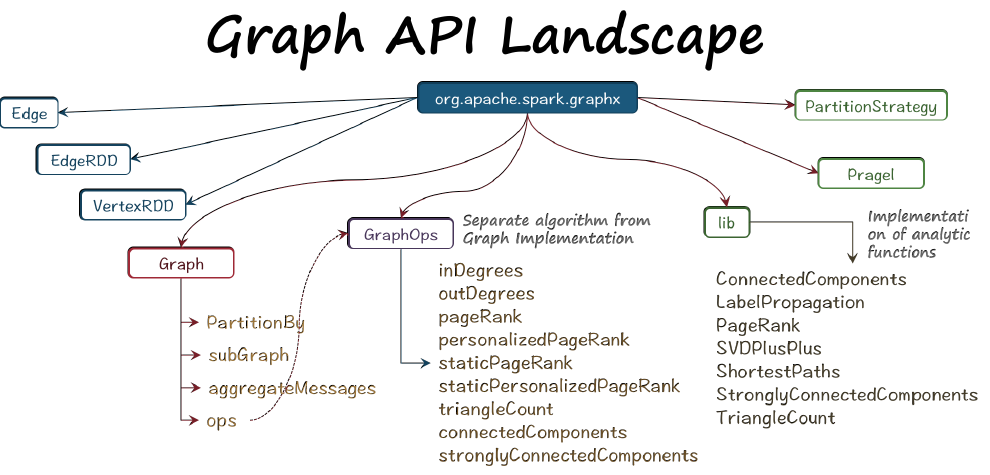
GraphX API提供了用于表示面向图数据的数据类型,以及用于图分析的基本的图运算符和图算法实现,它还提供了一个优化过的Pregel API实现。另外,GraphX包含了一个快速增长的图算法和图构建器的集合,用以简化图分析任务。
在org.apache.spark.graphx包下有Edge、EdgeRDD、VertexRDD、Graph和EdgeTriplet等对象;Graph对象具有如triplets、persist、subgraph等对象。而GraphX所实现的图算法位于GraphOps对象下(图算法和图实现分离),在lib下是一些分析函数,如SVD++、ShortestPath等。
注:Spark GraphX API对Python或Java不可用(只支持Scala的API)。
Graph类是Spark GraphX提供的主要类,它代表一个图对象,用于表示属性图的抽象,并提供对顶点和边的访问,以及用于转换图的各种操作。与RDD类似,它是不可变的、分布式的、容错的。在Spark中顶点和边是由两个特殊的RDD实现的:
- VertexRDD。包含元组,元组由两个元素组成:Long型的顶点ID和任意类型的属性对象。
- EdgeRDD。包含Edge对象,它由源和目标顶点ID(分别为srcId和dstId)和任意类型的属性对象(attr字段)组成。
VertexRDD
VertexRDD表示属性图中顶点的分布式集合。它提供属性图中顶点的集合视图。VertexRDD只为每个顶点存储一个条目。此外,它还为快速连接索引条目。
每个顶点都由一个key-value对表示,其中key是惟一的id,value是与该顶点关联的数据。key的数据类型是VertexId,它本质上是64位Long型。value可以是任何类型的。
VertexRDD是一个泛型类或参数化类,它需要一个类型参数。它被定义为VertexRDD[VD],其中类型参数VD指定与图中每个顶点关联的属性或属性的数据类型。例如,VD可以是Int、Long、Double、String或用户定义的类型。因此,图中的顶点可以用VertexRDD[String]、VertexRDD[Int]或用户定义类型的VertexRDD来表示。
Edge
Edge类是属性图中的有向边的抽象表示。Edge类的一个实例包含源顶点id、目标顶点id和边属性。Edge也是一个需要类型参数的泛型类。类型参数指定边属性的数据类型。例如,边可以具有Int、Long、Double、String或用户定义类型的属性。
EdgeRDD
EdgeRDD表示属性图中的边的分布式集合。EdgeRDD类是通过edge属性的数据类型参数化的。
EdgeTriplet
EdgeTriplet类的一个实例表示一条边和它连接的两个顶点的组合。它存储一条边的属性和它连接的两个顶点。它还包含边的源顶点和目标顶点的唯一标识符。EdgeTriplet如下图所示:

EdgeTriplets的集合表示属性图的表格视图。
GraphX
Graph是GraphX用于表示属性图的抽象;Graph类的一个实例表示一个属性图。与RDD类似,它是不可变的、分布式的和容错的。GraphX使用顶点分区启发式在集群中划分和分布图形。如果一台机器出现故障,它将在另一台机器上重新创建分区。
实际上,Graph类以RDD的形式提供对顶点和边的访问。顶点或边的RDD可以像任何其他RDD一样操作。所有的RDD方法都可用于转换或分析与顶点和边相关的数据。Graph类还提供了通过图视图转换和分析顶点和边的方法。因此,图类的实例可以作为一对集合或一个图形来处理。
Graph类不仅提供了修改顶点和边属性的方法,还提供了修改属性图结构的方法。由于Graph是不可变的数据类型,任何修改属性或结构的操作符都返回一个新的属性图。
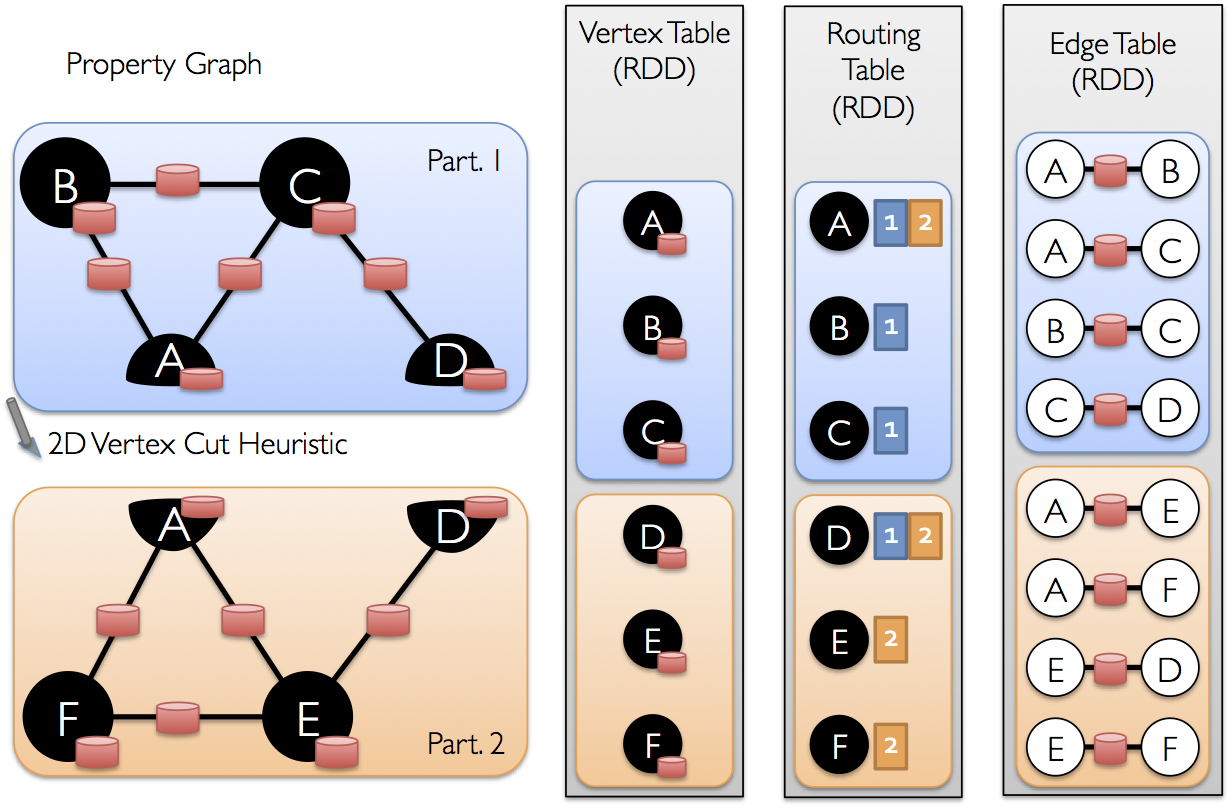
GraphX的图存储模式
图存储的两种方式:点分割存储和边分割存储。GraphX使用的是顶点分割(Vertex-Cut)方式存储图。这种存储方式特点是任何一条边只会出现在一台机器上,每个点有可能分布到不同的机器上。
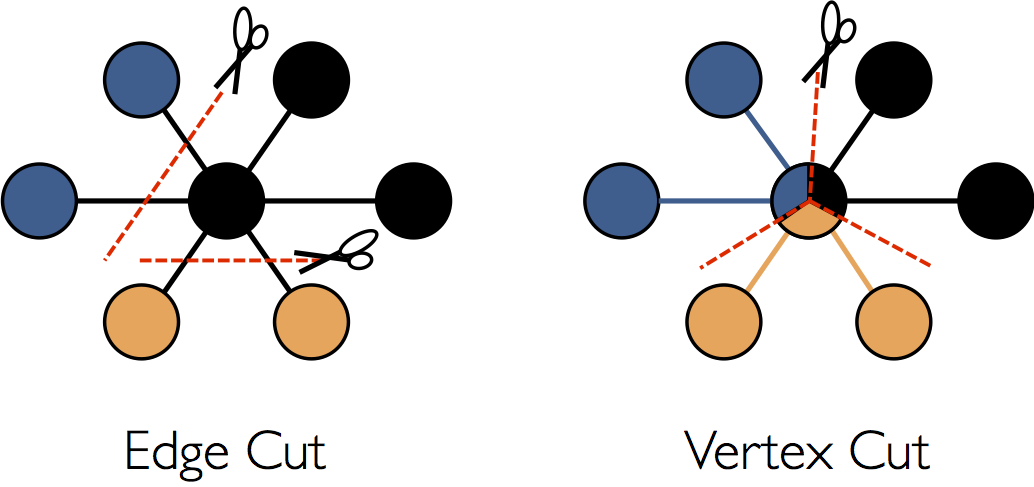
当点被分割到不同机器上时,是相同的镜像,但是有一个点作为主点,其他的点作为虚点,当点的数据发生变化时,先更新主点的数据,然后将所有更新好的数据发送到虚点所在的所有机器,更新虚点。
GraphX不是沿着边分割图,而是沿着顶点分割图,这样可以同时减少通信和存储开销。这样做的好处是在边的存储上是没有冗余的,而且对于某个点与它的邻居的交互操作,只要满足交换律和结合律,就可以在不同的机器上面执行,网络开销较小。但是这种分割方式会存储多份点数据,更新点时,会发生网络传输,并且有可能出现同步问题。
GraphX在进行图分割时,分配边的确切方法取决于划分策略。用户可以通过用Graph.partitionBy算子重新划分图来选择不同的策略。默认的分区策略是使用图构造时提供的边的初始分区。
有几种不同的分区(partition)策略,它通过PartitionStrategy专门定义这些策略。在PartitionStrategy中,总共定义了EdgePartition2D、EdgePartition1D、RandomVertexCut以及CanonicalRandomVertexCut这四种不同的分区策略。
- RandomVertexCut。这个方法比较简单,通过取源顶点和目标顶点id的哈希值来将边分配到不同的分区。这个方法会产生一个随机的边分割,两个顶点之间相同方向的边会分配到同一个分区。
- CanonicalRandomVertexCut。这种分割方法和前一种方法没有本质的不同。不同的是,哈希值的产生带有确定的方向(即两个顶点中较小id的顶点在前)。两个顶点之间所有的边都会分配到同一个分区,而不管方向如何。
- EdgePartition1D。这种方法仅仅根据源顶点id来将边分配到不同的分区。有相同源顶点的边会分配到同一分区。
- EdgePartition2D。这种分割方法同时使用到了源顶点id和目的顶点id。它使用稀疏边连接矩阵的2维区分来将边分配到不同的分区,从而保证顶点的备份数不大于2 * sqrt(numParts)的限制。这里numParts表示分区数。
Graphx使用的点分割图存储方式,用三个RDD存储图数据信息:
- VertexTable(id, data):id为顶点id, data为顶点属性。
- EdgeTable(pid, src, dst, data):pid 为分区id ,src为源顶点id ,dst为目的顶点id,data为边属性。
- RoutingTable(id, pid):id 为顶点id ,pid 为分区id。
点分割存储实现如下图所示: