使用GraphX构建图和查看图属性
使用GraphX可以为完整的图分析工作流或管道提供一个集成平台。图分析管道通常包括以下步骤:
- (1)读取原始数据。
- (2)预处理数据(如清洗数据)。
- (3)提取顶点和边来创建属性图。
- (4)切分子图。
- (5)运行图算法。
- (6)分析结果。
- (7)对图的另一部分重复步骤5和6。
GraphX的Graph对象是用户操作图的入口,它包含了边(edges)、顶点(vertices)以及triplets三部分,并且这三部分都包含相应的属性,可以携带额外的信息。
构建图的入口方法有两种,分别是根据边构建和根据边的两个顶点构建。
- 根据边构建图:Graph.fromEdges。
- 根据边的两个顶点数据构建:Graph.fromEdgeTuples。
不管是根据边构建图还是根据边的两个顶点数据构建,最终都是使用GraphImpl来构建的,即调用了GraphImpl的apply方法。
构建图的过程很简单,分为三步,它们分别是构建边EdgeRDD、构建顶点VertexRDD、生成Graph对象。在本节中,我们将学习如何使用GraphX构造和转换图。我们以一个社交网络为例,它有10个顶点和14条边,如下图所示:
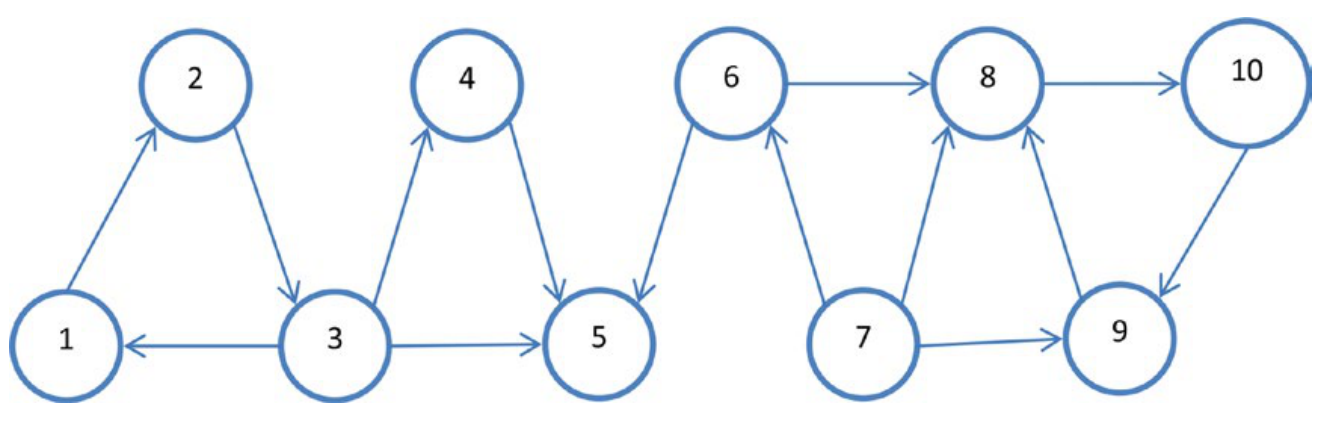
我们创建上边这个属性图,表示类似于Twitter的用户网络的社交网络。在这个属性图中,顶点表示用户,有向边表示“follows”关系。顶点中的数字代表顶点id。
1. 构造图
Spark GraphX库的Graph对象提供了从RDD构造图的工厂方法。一种常用的方法是使用一个包含元组(由一个顶点ID和一个顶点属性对象组成)的RDD和一个包含Edge对象的RDD来实例化一个Graph对象。我们将使用这个方法来构造上图中的示例图。
// 首先,需要导入所需的类
import org.apache.spark.graphx.{Edge, Graph}
import org.apache.spark.sql.SparkSession
......
// case class:用来代表顶点属性,存储一个用户的信息
case class User(name: String, age: Int)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local")
.appName("cep demo")
.getOrCreate()
// 构造顶点RDDs
val users = List(
(1L, User("Alex", 26)),
(2L, User("Bill", 42)),
(3L, User("Carol", 18)),
(4L, User("Dave", 16)),
(5L, User("Eve", 45)),
(6L, User("Farell", 30)),
(7L, User("Garry", 32)),
(8L, User("Harry", 36)),
(9L, User("Ivan", 28)),
(10L, User("Jill", 48))
)
val usersRDD = spark.sparkContext.parallelize(users)
// 构造边RDDs
val follows = List( Edge(1L, 2L, 1),
Edge(2L, 3L, 1),
Edge(3L, 1L, 1),
Edge(3L, 4L, 1),
Edge(3L, 5L, 1),
Edge(4L, 5L, 1),
Edge(6L, 5L, 1),
Edge(7L, 6L, 1),
Edge(6L, 8L, 1),
Edge(7L, 8L, 1),
Edge(7L, 9L, 1),
Edge(9L, 8L, 1),
Edge(8L, 10L, 1),
Edge(10L, 9L, 1),
Edge(1L, 11L, 1)
)
val followsRDD = spark.sparkContext.parallelize(follows)
// 创建默认属性集(id为11的顶点没有任何属性)
// 它会将默认属性分配给没有被显式分配任何属性的顶点
val defaultUser = User("NA", 0)
// 构造图对象
val socialGraph = Graph(usersRDD, followsRDD, defaultUser)
}
前面代码片段中的Graph对象从顶点RDD和边RDD创建Graph类的实例。
2. 使用GraphX API查看图属性
正如我们所说,在GraphX中表示图的主类是Graph。但是还有一个GraphOps类,它的方法被隐式添加到了Graph对象。其中包括获取顶点节点数量、入度、出度等的属性和方法。
GraphOps API:查看
下面查看图的一些属性:
// 边的数量
val numEdges = socialGraph.numEdges
println("边的数量:" + numEdges)
// 顶点的数量
val numVertices = socialGraph.numVertices
println("顶点的数量:" + numVertices)
// 顶点的入度
val inDegrees = socialGraph.inDegrees
println("顶点的入度:")
inDegrees.collect.foreach(println)
// 顶点的出度
val outDegrees = socialGraph.outDegrees
println("顶点的出度:")
outDegrees.collect.foreach(println)
// 顶点的出入度总和
val degrees = socialGraph.degrees
println("顶点的出入度总和:")
degrees.collect.foreach(println)
输出如下:
边的数量:15 顶点的数量:11 顶点的入度: (4,1) (11,1) (1,1) (6,1) (3,1) (9,2) (8,3) (10,1) (5,3) (2,1) 顶点的出度: (4,1) (1,2) (6,2) (3,3) (7,3) (9,1) (8,1) (10,1) (2,1) 顶点的出入度总和: (4,2) (11,1) (1,3) (6,3) (3,4) (7,3) (9,3) (8,4) (10,2) (5,3) (2,2)
获得属性图中顶点的集合视图,代码如下:
val vertices = socialGraph.vertices // 获得所有的顶点
println("属性图中顶点的集合视图:")
vertices.collect.foreach(println)
输出如下:
属性图中顶点的集合视图: (4,User(Dave,16)) (11,User(NA,0)) (1,User(Alex,26)) (6,User(Farell,30)) (3,User(Carol,18)) (7,User(Garry,32)) (9,User(Ivan,28)) (8,User(Harry,36)) (10,User(Jill,48)) (5,User(Eve,45)) (2,User(Bill,42))
获得属性图中边的集合视图,代码如下:
val edges = socialGraph.edges // 获得所有的边
println("属性图中边的集合视图:")
edges.collect.foreach(println)
输出如下:
属性图中边的集合视图: Edge(1,2,1) Edge(1,11,1) Edge(2,3,1) Edge(3,1,1) Edge(3,4,1) Edge(3,5,1) Edge(4,5,1) Edge(6,5,1) Edge(6,8,1) Edge(7,6,1) Edge(7,8,1) Edge(7,9,1) Edge(8,10,1) Edge(9,8,1) Edge(10,9,1)
在org.apache.spark.graphx包中有一个EdgeTriplet类,它的一个实例表示一条边和该边连接的两个顶点的组合,存储一条边的属性和它连接的两个顶点。EdgeTriplet类继承自Edge类,增加了分别包含源属性和目标属性的srcAttr和dstAttr成员。它还包含边的源顶点和目标顶点的惟一标识符。
// 获得属性图中triplet集合视图
val triplets = socialGraph.triplets
// triplets.take(3)
// 输出源顶点ID、源顶点属性name、目标顶点ID和目标顶点属性name
triplets.take(3).foreach{ t =>
println(t.srcId + "," + t.srcAttr.name + " ---> " + t.dstId + "," + t.dstAttr.name)
}
// triplets.collect.foreach(println)
输出如下:
1,Alex ---> 2,Bill 1,Alex ---> 11,NA 2,Bill ---> 3,Carol
