GraphFrames图处理库简介
图提供了一种强大的方法来分析数据集中的连接。对于面向图的数据,图为处理数据提供了易于理解和直观的模型。此外,还可以使用专门的图算法来处理面向图的数据。这些算法为不同的分析任务提供了有效的工具。
Apache Spark本身包含有一个位于Spark Core之上的分布式图处理框架GraphX,用于图并行和数据并行计算。它建立在一个称为“图论”的数学分支上,使在Spark中运行图算法成为可能。但是,GraphX API存在一些限制。首先,GraphX只支持Scala语言,所以无法使用Python进行大型的图计算。其次,GraphX只能在RDD上工作,因此不能从DataFrame和Catalyst查询优化器提供的性能改进中受益。
GraphFrames是一个开源的Spark包,创建它的目的是解决以上这两个问题。它具有以下特点:
- (1) 提供一组Python API。
- (2) 适用于DataFrame。
GraphFrames扩展了Spark GraphX以提供DataFrame API,使分析更容易使用、更有效,并简化了数据管道。GraphFrames集成了GraphX和DataFrame,使得用户可以在不将数据移动到专门的图数据库的情况下执行图模式查询。
GraphFrames和GraphX的比较见下表:

1. 图基本概念
图,作为链接对象的数学概念,由顶点(图中的对象)和连接顶点的边组成。
一旦表示为图,有些问题就变得更容易解决;它们自然地产生了图算法。例如,使用传统的数据组织方法(如关系数据库)呈现分层数据会是很复杂的,那么就可以用图来简化。除了使用它们来代表社交网络和网页之间的链接外,图算法还在生物学、计算机芯片设计、旅行、物理、化学等领域都有应用。
首先介绍一下本章中用到的基本图相关术语。
图是一种数学结构,用来建模对象之间的关系。图是由顶点和连接它们的边组成的。顶点是对象,而边是它们之间的关系。顶点是图中的一个节点。一条边连接图中的两个顶点。一般来说,顶点代表一个实体,边代表两个实体之间的关系。图在概念上等价于顶点和边的集合,如下图所示。
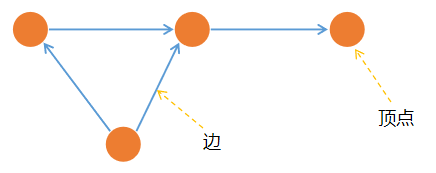
图可以有方向也可以无方向。
无向图是具有没有方向的边的图。无向图中的边没有源顶点或目标顶点。例如,用户张三和李四构成图的顶点,它们之间的关系构成边,如下图所示。

有向图就是边具有方向的图。有向图中的边具有源顶点和目标顶点。例如,Twitter follower就是一个有向图。用户张三可以关注用户李四,而不需要暗示用户李四也关注用户张三,如下图所示。

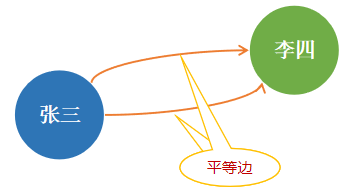
有向多图是一个有向图,它包含由两条或多条平行边连接的顶点对。有向多图中的平行边是具有相同起始和终止顶点的边。它们用于表示一对顶点之间的多个关系,如下图所示。
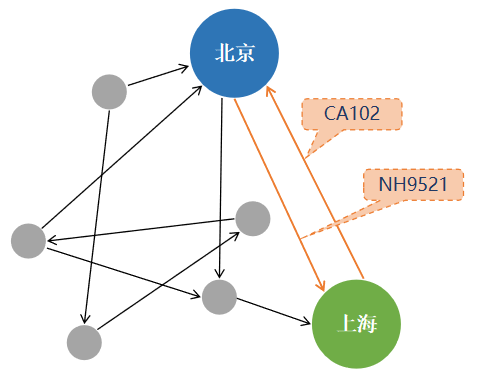
属性图是一个有向多图,它具有与顶点和边相关联的数据。属性图中的每个顶点都有一个或多个属性。类似地,每条边都有一个标签或属性。属性图如图9-5所示。
属性图为处理面向图的数据提供了丰富的抽象。它是用图建模数据的最流行的形式。例如,表示公司中的两个员工及其关系的属性图,如下图所示。

属性图的另一个例子是表示微博上的社交网络的图。用户具有姓名、年龄、性别和位置等属性。此外,用户可以关注其他用户,并可能有自己的粉丝。在表示微博上的社交网络的图中,顶点表示用户,边表示“关注”关系。例如,一个简单的社交网络图,如下图所示。

GraphFrames图处理库
Spark GraphFrames提供了一个声明性API,可用于大型图模型上的交互式查询和独立程序。由于GraphFrames是在Spark SQL上实现的,它支持在计算过程中进行并行处理和优化。GraphFrames与Spark和GraphX的关系如下图所示。

GraphFrames API中的主要编程抽象是一个GraphFrame。从概念上讲,它由两个DataFrame组成,分别表示图的顶点和边。顶点和边可以有多个属性,这些属性也可以用于查询。例如,在社交网络中,顶点可以包含名称、年龄、位置和其他属性,而边可以表示节点(社交网络中的个人)之间的关系。因为GraphFrame模型可以支持用户定义的每个顶点属性和边属性,因此它等价于属性图模型。此外,可以使用模式来定义视图,以匹配网络中各种形状的子图。
Spark GraphFrames支持分布式属性图的图计算。使用GraphFrames,顶点和边均表示为DataFrame,这可以充分利用Spark SQL查询的优点,并支持DataFrame数据源,如Parquet、JSON、CSV等等。
GraphFrames优化了计算的关系和图部分的执行。可以使用关系运算符、模式和对算法的调用指定这些计算。
