案例:亚马逊产品联购分析
本节通过一个案例,演示使用GraphFrame分析亚马逊产品2003年6月1日联购网络。本案例所使用的数据集由爬取亚马逊网站收集。它是基于亚马逊网站的“购买了该商品的顾客同时也购买了”功能。如果产品i经常与产品j共同购买,则图中包含从i到j的有向边。
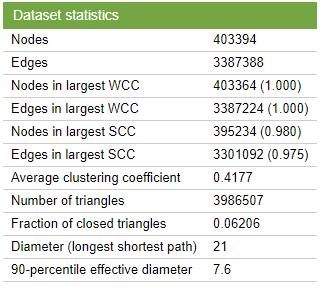
数据集统计如下图所示。
首先导入依赖包,代码如下:
import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.Row import org.graphframes._ import spark.implicits._
加载联购数据,先把文件中的注释过滤掉,然后创建边DataFrame,再从边DataFrame中找出所有的顶点,创建顶点DataFrame。最后,由顶点DataFrame和边DataFrame创建图模型,代码如下:
// 1) 构造GraphFrame
// 加载数据到RDD
val filePath = "/data/amazon/Amazon0601.txt"
val edgesRDDRow = spark.sparkContext.textFile(filePath)
// 这是个坑:一定要对数据过滤,把注释过滤掉
val edgesRDD = edgesRDDRow.filter(line => !line.startsWith("#"))
// schema ......
......
抱歉,只有登录会员才可浏览!会员登录
