Spark技术栈
Spark是一种通用的集群计算系统,它可以授权其他高级组件来利用其核心引擎。它可以与Apache Hadoop进行互操作,从/到HDFS读取和写入数据,还可以与Hadoop API支持的其他存储系统集成。
Spark栈结构
Spark提供了一个统一的数据处理引擎,称为Spark栈。Spark栈由以下五层组成:Storage、Resource management、Engine、Ecosystem、APIs,如下图所示:
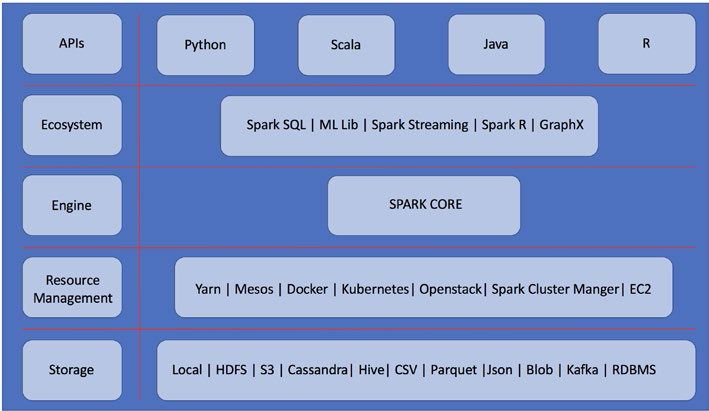
存储:Spark提供了多个选项来使用不同类别的数据源,以便能够大规模地处理它。Spark还可以使用传统的关系数据库和NoSQL,如Cassandra和MongoDB。
资源管理器:负责整个系统的资源管理和分配。Spark中两个最广泛使用的资源管理器是YARN和Mesos。
引擎和生态系统:Spark体系结构的基础是其Core,Spark栈是建立在Spark Core的强大基础引擎之上的。Spark Core提供了管理和运行分布式应用程序的所有必要功能,如调度、协调和容错。此外,它还为数据处理提供了强大的通用编程抽象,称为弹性分布式数据集(RDDs,resilient distributed datasets)。在Spark Core之上是一个组件集合,其中每个组件都是为特定的数据处理工作而设计的。
APIs:Spark提供了四种编程语言接口。因为Spark是用Scala构建的,所以它是首选语言。除了Scala,我们还可以使用Java、Python和R。由于Spark内置了对Scala、Java、R和Python的支持,因此更广泛的开发人员和数据工程师能够利用整个Spark栈来应用不同的应用场景。
Spark功能组件
下面我们分别了解Spark Core引擎和各个功能组件。
1、Spark core
Spark core由两个部分组成:分布式计算基础设施和RDD编程抽象。
分布式计算基础设施的职责:
- 负责集群中多节点上的计算任务的分发、协调和调度
- 处理计算任务失败
- 高效地跨节点传输数据(即数据传输shuffling)
Spark的高级用户需要对Spark分布式计算基础设施有深入的了解,从而能够有效地设计高性能的Spark应用程序。
Spark core在某种程度上类似于操作系统的内核。它是通用的执行引擎,它既快速又容错。整个Spark生态系统是建立在这个核心引擎之上的。它主要用于工作调度、任务分配和跨worker节点的作业监控。它还负责内存管理,与各种异构存储系统交互,以及各种其他操作。
Spark core的主要编程抽象是弹性分布式数据集(RDD),RDD是一个不可变的、容错的对象集合,它可以在一个集群中进行分区,因此可以并行操作。本质上,它为Spark应用程序开发人员提供了一组APIs,使他们能够轻松高效地执行大规模的数据处理,而不必担心数据驻留在集群上的什么位置或处理机器故障。
Spark可以从各种数据源创建RDDs,如HDFS、本地文件系统、Amazon S3、其他RDDs、诸如Cassandra之类的NoSQL数据存储,等等。RDD适应性很强,会在失败时自动重建。RDDs是通过惰性并行转换构建的,它们可能被缓存和分区,可能会也可能不会被具体化。
2、Spark SQL
Spark SQL是构建在Spark Core之上的组件,被设计用来在结构化数据上执行查询、分析操作。因为Spark SQL的灵活性、易用性和良好性能,使得它出现伊始就受到热烈欢迎。
Spark SQL提供了一种名为DataFrame的分布式编程抽象。DataFrame是被命名的列的分布式集合,类似于SQL表或Python的Pandas库中的DataFrames。可以用各种各样的数据源构造DataFrame,如Hive、Parquet、JSON、其他RDBMS源,以及Spark RDDs。这些数据源可以具有各种模式。
Spark SQL可以用于不同格式的ETL处理,然后进行即席查询分析。Spark SQL附带一个名为Catalyst的优化器框架,它可以转换SQL查询以提高效率。Spark SQL利用Catalyst优化器来执行许多分析数据库引擎中常见的优化类型。Spark SQL的座右铭是“write less code, read less data, and let the optimizer do the hard work”。
3、Spark streaming和Structured Streaming
为了解决企业的数据实时处理需求,Spark提供了流处理组件,它具有容错能力和可扩展性。Spark支持实时数据流的实时数据分析。因为有一个统一的Spark栈,所以在Spark中可以很容易地将批处理和交互式查询与流处理结合起来。
Spark Streaming和Spark Structured Streaming模块能够以高吞吐量和容错的方式处理来自各种数据源的实时流数据。数据可以从像Kafka、Flume、Kinesis、Twitter、HDFS或TCP套接字这样的资源中摄取。
在第一代Spark Streaming处理引擎中,主要的抽象被称为离散化流(DStream),它通过将输入数据分割成小批量(基于时间间隔)来实现增量流处理模型,该模型可以定期地组合当前的处理状态以产生新的结果。换句话说,一旦传入的数据被分成小批处理,每批处理都将被视为一个RDD,并将其复制到集群中,这样它们就可以被相应地作为基本的RDD操作处理。通过在DStreams上应用一些更高级别的操作,可以产生其他的DStreams。Spark流的最终结果可以被写回由Spark支持的各种数据存储,或者可以被推送到任何仪表盘进行可视化。
从Spark 2.1开始,引入了一个新的可扩展和容错的流处理引擎,称为结构化流(Structured Streaming)。结构化流是在Spark SQL引擎之上构建的,它进一步简化了流处理应用程序开发,处理流计算就像在静态数据上表示批计算一样。随着新的流数据的持续到来,结构化流引擎将自动地、增量地、持续地执行流处理逻辑。结构化流提供的一个新的重要特性是基于事件时间(Event Time)处理传入流数据的能力,这对于许多新的流处理用例来说是必需的。在结构化流引擎中还支持端到端的、精确一次性保证。
4、Spark MLlib
MLlib是Spark栈中内置的机器学习库,是从Spark 0.8引入的。它的目标是使机器学习变得可扩展并且更容易。MLlib提供了执行各种统计分析的必要功能,如相关性、抽样、假设检验等等。该组件还开箱即用的提供了常用的机器学习算法实现,如分类、回归、聚类和协同过滤。
从Spark 2.0开始,MLlib APIs基于DataFrames以及Spark SQL引擎中的Catalyst和Tungsten组件,以及这些组件所提供的许多优化。
机器学习工作流程包括收集和预处理数据、构建和部署模型、评估结果和改进模型。在现实世界中,预处理步骤需要付出很大的努力。这些都是典型的多阶段工作流,涉及昂贵的中间读/写操作。通常,这些处理步骤可以在一段时间内多次执行。Spark机器学习库引入了一个名为ML管道的新概念,以简化这些预处理步骤。管道是一个转换序列,其中一个阶段的输出是另一个阶段的输入,形成工作流链。
除了提供超过50种常见的机器学习算法之外,Spark MLlib库提供了一些功能抽象,用于管理和简化许多机器学习模型构建任务,如特征化,用于构建、评估和调优模型的管道,以及模型的持久性(以帮助将模型从开发转移到生产环境)。
5、Spark GraphX
GraphX是Spark的统一图分析框架。它被设计成一个通用的分布式数据流框架,取代了专门的图处理框架。它具有容错特性,并且利用内存进行计算。
GraphX是一种嵌入式图处理API,用于操纵图(例如,社交网络)和执行图并行计算(例如,Google的Pregel)。它结合了Spark栈上的图并行和数据并行系统的优点,以统一探索性数据分析、迭代图计算和ETL处理。它扩展了RDD抽象来引入弹性分布式图(Resilient Distributed Graph - RDG),这是一个有向图,具有与每个顶点和边相关联的属性。
GraphX组件包括一组通用图处理算法,包括PageRank、K-Core、三角计数、LDA、连接组件、最短路径,等等。
6、SparkR
SparkR项目开始将R的统计分析和机器学习能力与Spark的可扩展性集成在一起。它解决了R的局限性,即它处理单个机器内存中所需要的大量数据的能力。R程序现在可以通过SparkR在分布式环境中进行扩展。
SparkR实际上是一个R包,它提供了一个R shell来利用Spark的分布式计算引擎。有了R丰富的用于数据分析的内置包,数据科学家可以交互式地分析大型数据集。
