示例_数据缺失值处理
下面是一个简单的数据清洗的示例,演示了使用Spark SQL DataFrame API对数据集进行缺失值填充和删除的方法。
首先构造一个带缺失值的Dataset:
// case class
case class Author (name: String, dynasty: String, dob: String)
// 构造一个带有缺失值的数据集
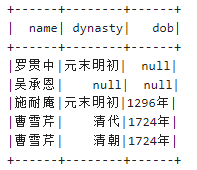
val authors = Seq(Author("曹雪芹","清代","1724年"),
Author("施耐庵","元末明初","1296年"),
Author("罗贯中","元末明初",null),
Author("吴承恩",null,null)
)
val ds1 = sc.parallelize(authors).toDS()
ds1.show()
输出结果如下所示:

删除带有缺失值的行:
ds1.na.drop().show()
输出结果如下所示:

删除带有至少两个缺失值的行:
ds1.na.drop(minNonNulls=2).show()
输出结果如下所示:

注意,没有直接删除至少n个缺失值的行的scala函数,不过可以删除包含低于指定的非null值的行,从而取得相同的结果:
ds1.na.drop(minNonNulls = ds1.columns.length - 1).show()
输出结果如下所示:
使用一个给定的字符串填充所有缺失的值:
ds1.na.fill("不详").show()
输出结果如下所示:

也可以在每一列使用一个给定的字符串填充缺失值:
ds1.na.fill(Map("dynasty"->"--", "dob"->"不详")).show()
输出结果如下所示:

删除重复的值:
// 重用Author case class
// 构造另一个Dataset
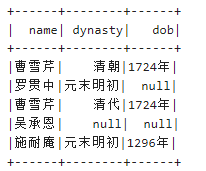
val authors = Seq(Author("曹雪芹","清代","1724年"),
Author("曹雪芹","清代","1724年"),
Author("施耐庵","元末明初","1296年"),
Author("曹雪芹","清朝","1724年"),
Author("罗贯中","元末明初",null),
Author("吴承恩",null,null)
)
val ds1 = sc.parallelize(authors).toDS()
ds1.show()
输出结果如下所示:

删除完全重复的行:
ds1.dropDuplicates().show()
输出结果如下所示:
删除指定的列重复的行(基于一个列的子集删除重复):
ds1.dropDuplicates("name").show()
输出结果如下所示:

删除指定的多个列重复的行(基于一个子集删除重复):
ds1.dropDuplicates(Array("dynasty","dob")).show()
输出结果如下所示: