设置Spark on YARN
本教程介绍如何在Hadoop上使用Yarn集群管理器设置Apache Spark并运行Spark应用程序,其中Yarn集群管理器用于将Spark示例作为client部署模式并将master作为Yarn运行。
Spark安装与设置
通过访问Spark下载页面下载Apache Spark,默认为最新版本的Spark。 如果想使用不同版本的Spark和Hadoop,请从下拉框中选择自己想要的版本。随着您的选择,列表项3上的链接也随之更改为所选版本,并提供更新后的下载链接。 点击列表项3对应的下载链接下载,如下图所示:
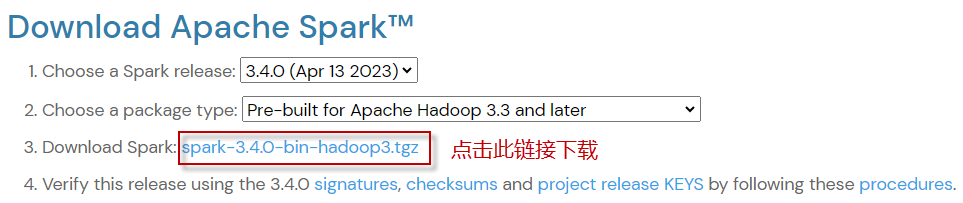
下载完成后,使用文件归档工具tar解压文件内容,并将文件夹重命名为spark。命令如下:
tar -xzf spark-3.4.0-bin-hadoop3.tgz mv spark-3.4.0-bin-hadoop3 spark
在.bashrc或.profile文件中添加spark环境变量。在任意文本编辑器(例如,vi编辑器)中打开文件并添加以下变量。
vi ~/.bashrc
编辑内容如下:
抱歉,只有登录会员才可浏览!会员登录
