事件时间和窗口聚合
基于数据创建时间处理传入的实时数据的能力是一个优秀的流处理引擎的必备功能。这一点很重要,因为要真正理解并准确地从流数据中提取见解或模式,需要能够根据数据或事件发生的时间来处理它们。
配套视频:
Spark结构化流_事件时间与窗口聚合
固定窗口聚合
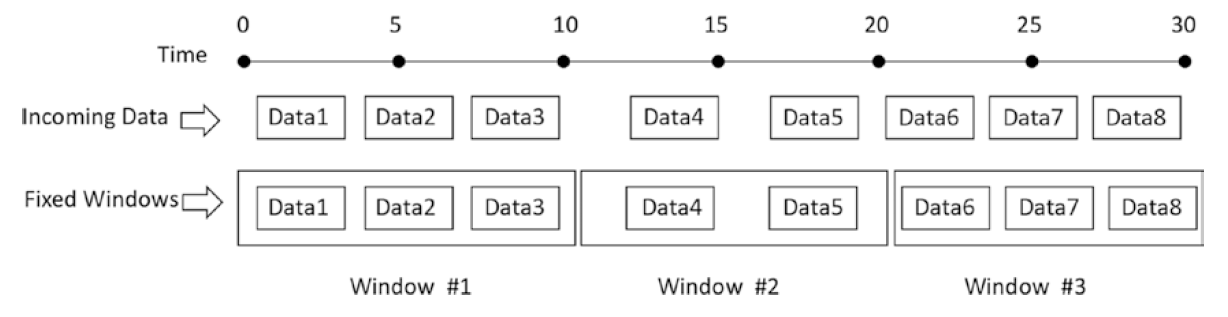
一个固定的窗口(也就是一个滚动的窗口)操作本质上是根据一个固定的窗口长度将一个流入的数据流离散到非重叠的桶中。对于每一片输入的数据,根据它的事件时间(event time)将它放置到其中一个桶中。执行聚合仅仅是遍历每个桶并在每个桶上应用聚合逻辑(例如计数或求和)。下图说明了固定窗口聚合逻辑。
下面我们通过一个示例程序来演示如何使用结构化流读取文件数据源。
【示例】移动电话的开关机等事件会保存在json格式的文件中。现要求编写Spark结构化流处理程序来读取并分析这些移动电话数据,统计每10分钟内不同电话操作(如open或close)发生的数量。
这实际上是在一个10分钟长的固定窗口上对移动电话操作事件的数量进行count聚合。请按以下步骤操作。
1)准备数据
在本示例中,我们使用文件数据源,该数据源以json文件的格式记录了一小组移动电话动作事件。每个事件由三个字段组成:
- id:表示手机的唯一ID。在样例数据集中,电话ID将类似于phone1、phone2、phone3等。
- action:表示用户所采取的操作。该操作的可能值是"open"或"close"。
- ts:表示用户action发生时的时间戳。这是事件时间(event time)。
我们准备了四个存储移动电话事件数据的JSON文件,这四个文件均位于PBLP平台如下位置:~/data/spark/mobile/
为了模拟数据流的行为,我们将把这四个JSON文件复制到项目的“src/main/resources/mobile”目录下。
2)编辑源代码,内容如下。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
......
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("fixed window")
.getOrCreate()
// 定义schema
val mobileDataSchema = new StructType()
.add("id", StringType, nullable = false)
.add("action", StringType, nullable = false)
.add("ts", TimestampType, nullable = false)
// 读取流数据,使用文件数据源
val dataPath = "src/main/resources/mobile"
val mobileSSDF = spark.readStream
.option("maxFilesPerTrigger", 1)
.schema(mobileDataSchema)
.json(dataPath)
import spark.implicits._
// 在一个10分钟的窗口上执行聚合操作
val windowCountDF = mobileSSDF.groupBy(window($"ts", "10 minutes")).count()
windowCountDF.printSchema()
// 执行流查询,将结果输出到控制台
windowCountDF
.select("window.start","window.end","count")
.orderBy("start")
.writeStream
.format("console")
.option("truncate", "false")
.outputMode("complete")
.start()
.awaitTermination()
}
3)执行流处理程序,输出结果如下所示。
root |-- window: struct (nullable = false) | |-- start: timestamp (nullable = true) | |-- end: timestamp (nullable = true) |-- count: long (nullable = false) +-------------------+-------------------+-----+ |start |end |count| +-------------------+-------------------+-----+ |2018-03-02 10:00:00|2018-03-02 10:10:00|7 | |2018-03-02 10:10:00|2018-03-02 10:20:00|1 | |2018-03-02 11:00:00|2018-03-02 11:10:00|1 | |2018-03-02 11:10:00|2018-03-02 11:20:00|1 | +-------------------+-------------------+-----+
可以看出,当用窗口执行聚合时,输出窗口实际上是一个struct类型,它包含开始和结束时间。在上面的代码中,我们分别取window的start和end列,并按start窗口开始时间排序。可以看,每10分钟做为一个窗口进行统计。
3)除了在groupBy转换中指定一个窗口之外,还可以从事件本身指定额外的列。对上面的例子稍做修改,使用一个窗口并在action列上执行聚合,实现对每个窗口和该窗口中action类型的count计数。代码如下所示:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
......
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("fixed window")
.getOrCreate()
// 定义schema
val mobileDataSchema = new StructType()
.add("id", StringType, nullable = false)
.add("action", StringType, nullable = false)
.add("ts", TimestampType, nullable = false)
// 读取流数据,使用文件数据源
val dataPath = "src/main/resources/mobile"
val mobileSSDF = spark.readStream.schema(mobileDataSchema).json(dataPath)
import spark.implicits._
// 在一个10分钟的窗口上执行聚合操作
val windowCountDF = mobileSSDF
.groupBy(window($"ts", "10 minutes"), $"action") // 修改1
.count()
windowCountDF.printSchema()
// 执行流查询,将结果输出到控制台
windowCountDF
.select("window.start", "window.end", "action", "count") // 修改2
.orderBy("start")
.writeStream
.format("console")
.option("truncate", "false")
.outputMode("complete")
.start()
.awaitTermination()
}
输出结果如下所示:
root |-- window: struct (nullable = false) | |-- start: timestamp (nullable = true) | |-- end: timestamp (nullable = true) |-- action: string (nullable = false) |-- count: long (nullable = false) ------------------------------------------- Batch: 0 ------------------------------------------- +-------------------+-------------------+------+-----+ |start |end |action|count| +-------------------+-------------------+------+-----+ |2018-03-02 10:00:00|2018-03-02 10:10:00|close |3 | |2018-03-02 10:00:00|2018-03-02 10:10:00|open |4 | |2018-03-02 10:10:00|2018-03-02 10:20:00|open |1 | |2018-03-02 11:00:00|2018-03-02 11:10:00|crash |1 | |2018-03-02 11:10:00|2018-03-02 11:20:00|swipe |1 | +-------------------+-------------------+------+-----+
滑动窗口聚合
除了固定窗口类型之外,还有另一种称为滑动窗口(sliding window)的窗口类型。
定义一个滑动窗口需要两个信息,窗口长度和一个滑动间隔,滑动间隔通常比窗口的长度要小。由于聚合计算在传入的数据流上滑动,因此结果通常比固定窗口类型的结果更平滑。因此,这种窗口类型通常用于计算移动平均。关于滑动窗口,需要注意的一点是,由于重叠的原因,一块数据可能会落入多个窗口,如下图所示。
下面通过一个示例程序使用和理解滑动窗口。
【示例】应用滑动窗口聚合解决一个IOT流数据分析需求:在一个数据中心中,按一定的时间间隔周期性地检测每个服务器机架的温度,并生成一个报告,显示每一个机架在窗口长度10分钟、滑动间隔5分钟的平均温度。
请按以下步骤操作。
1)准备数据
在本示例中,我们使用文件数据源,该数据源以json文件的格式记录了某数据中心两个机架的温度数据。每个事件由三个字段组成:
- rack:表示机器的唯一ID,字符串类型。
- temperature:表示采集到的温度值,double类型。
- ts:表示该事件发生时的时间戳。这是事件时间(event time)。
注:数据源文件file1.json和file2.json,位于PBLP平台的如下位置:~/data/spark/iotd/。
为了模拟数据流的行为,我们将把这两个JSON文件复制到项目的“src/main/resources/iotd”目录下。
2)代码编写。
实现的流查询代码如下:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
......
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("fixed window")
.getOrCreate()
// 定义schema
val iotDataSchema = new StructType()
.add("rack", StringType, nullable = false)
.add("temperature", DoubleType, nullable = false)
.add("ts", TimestampType, nullable = false)
// 读取流数据,使用文件数据源
val dataPath = "src/main/resources/iotd"
val iotSSDF = spark.readStream
.schema(iotDataSchema)
.json(dataPath)
import spark.implicits._
// group by一个滑动窗口,并在temperature列上求平均值
val windowAvgDF = iotSSDF
.groupBy(window($"ts", "10 minutes", "5 minutes"))
.agg(avg("temperature") as "avg_temp")
windowAvgDF.printSchema()
windowAvgDF
.select("window.start", "window.end", "avg_temp")
.orderBy("start")
.writeStream
.format("console")
.option("truncate", "false")
.outputMode("complete")
.start()
.awaitTermination()
}
在上面的代码中,首先读取温度数据,然后在ts列上构造一个长10分钟、每5分钟进行滑动的滑动窗口,并在这个窗口上执行groupBy转换。对于每个滑动窗口,avg()函数被应用于temperature列。
3)执行以上代码,输出结果如下所示:
root |-- window: struct (nullable = true) | |-- start: timestamp (nullable = true) | |-- end: timestamp (nullable = true) |-- avg_temp: double (nullable = true) ------------------------------------------- Batch: 0 ------------------------------------------- +-------------------+-------------------+--------+ |start |end |avg_temp| +-------------------+-------------------+--------+ |2017-06-02 07:55:00|2017-06-02 08:05:00|99.5 | |2017-06-02 08:00:00|2017-06-02 08:10:00|101.25 | |2017-06-02 08:05:00|2017-06-02 08:15:00|102.75 | |2017-06-02 08:10:00|2017-06-02 08:20:00|103.75 | |2017-06-02 08:15:00|2017-06-02 08:25:00|105.0 | +-------------------+-------------------+--------+
上面的输出显示在合成数据集中有5个窗口。注意每个窗口的开始时间间隔为5分钟,这是因为在groupBy转换中指定的滑动间隔的长度。
在上面的分析结果中,可以看出avg_temp列所代表的机架平均温度在上升。那么大家思考一下,机架平均温度的上长,是因为其中某个机架的温度升高从而导致平均温度的升高?还是所有机架的温度都在升高?
4)为了弄清楚到底是哪些机架在不断升温,我们重构上面的代码,把rack列添加到groupBy转换中,代码如下所示(只显示不同的代码部分):
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
......
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("fixed window")
.getOrCreate()
// 定义schema
val iotDataSchema = new StructType()
.add("rack", StringType, nullable = false)
.add("temperature", DoubleType, nullable = false)
.add("ts", TimestampType, nullable = false)
// 读取流数据,使用文件数据源
val dataPath = "src/main/resources/iotd"
val iotSSDF = spark.readStream
.option("maxFilesPerTrigger", 1)
.schema(iotDataSchema)
.json(dataPath)
import spark.implicits._
// group by一个滑动窗口和rack列,并在temperature列上求平均值
val windowAvgDF = iotSSDF
.groupBy(window($"ts", "10 minutes", "5 minutes"), $"rack")
.agg(avg("temperature") as "avg_temp")
windowAvgDF.printSchema()
// 分别报告每个机架随时间而变化的温度
windowAvgDF
.select("rack","window.start", "window.end", "avg_temp")
.orderBy("rack","start")
.writeStream
.format("console")
.option("truncate", "false")
.outputMode("complete")
.start()
.awaitTermination()
}
执行以上代码,输出结果如下所示:
root |-- window: struct (nullable = true) | |-- start: timestamp (nullable = true) | |-- end: timestamp (nullable = true) |-- rack: string (nullable = false) |-- avg_temp: double (nullable = true) ------------------------------------------- Batch: 0 ------------------------------------------- +-----+-------------------+-------------------+--------+ |rack |start |end |avg_temp| +-----+-------------------+-------------------+--------+ |rack1|2017-06-02 07:55:00|2017-06-02 08:05:00|99.5 | |rack1|2017-06-02 08:00:00|2017-06-02 08:10:00|100.0 | |rack1|2017-06-02 08:05:00|2017-06-02 08:15:00|100.75 | |rack1|2017-06-02 08:10:00|2017-06-02 08:20:00|101.5 | |rack1|2017-06-02 08:15:00|2017-06-02 08:25:00|102.0 | |rack2|2017-06-02 07:55:00|2017-06-02 08:05:00|99.5 | |rack2|2017-06-02 08:00:00|2017-06-02 08:10:00|102.5 | |rack2|2017-06-02 08:05:00|2017-06-02 08:15:00|104.75 | |rack2|2017-06-02 08:10:00|2017-06-02 08:20:00|106.0 | |rack2|2017-06-02 08:15:00|2017-06-02 08:25:00|108.0 | +-----+-------------------+-------------------+--------+
从上面的输出结果表中,可以清楚地看出来,机架1的平均温度低于103,而机架2升温的速度要远快于机架1,所以应该关注的是机架2。
