实验:安装和配置Spark
为了学习Spark,最好在我们自己的计算机上本地安装Spark。通过这种方式,我们可以轻松地尝试Spark特性或使用小型数据集测试数据处理逻辑。
Spark是用Scala编程语言编写的,在安装Spark之前,确保已经在自己的计算机上安装了Java(JDK 8)。
安装Spark
要在自己的计算机上本地安装Spark,请按以下步骤操作。
1)下载预先打包的二进制文件到"~/software"目录下,它包含运行Spark所需的JAR文件。下载
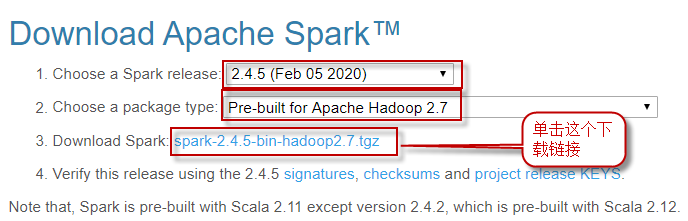
2)将其解压缩到"~/bigdata/"目录下,并改名为spark-2.4.5。执行命令如下:
$ cd ~/bigdata
$ tar -zxvf ~/software/spark-2.4.5-bin-hadoop2.7.tgz
$ mv spark-2.4.5-bin-hadoop2.7 spark-2.4.5
3)配置环境变量。打开"/etc/profile"文件:
$ cd
$ sudo nano /etc/profile
在文件最后,添加如下内容:
export SPARK_HOME=/home/hduser/bigdata/spark-2.4.5
export PATH=$SPARK_HOME/bin:$PATH
保存文件并关闭。
4)执行/etc/profile文件使得配置生效:
$ source /etc/profile
查看解压缩后的Spark安装目录,会发现其中包含多个目录:
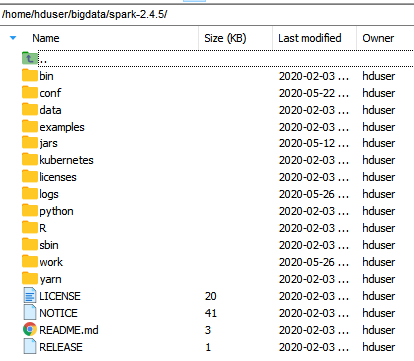
其中几个主要目录作用如下表所示:

配置Spark
Spark的配置文件位于conf目录下。接下来,我们对Spark进行配置,包括其运行环境和集群配置参数。
(1)从模板文件复制一份spark-env.sh。执行以下命令:
$ cd ~/spark-2.4.5/conf $ cp spark-env.sh.template spark-env.sh
(2)编辑spark-env.sh。执行以下命令:
$ nano spark-env.sh
在打开的"spark-env.sh"文件末尾,添加以下内容,并保存:
export JAVA_HOME=/usr/local/jdk1.8.0_251 export SPARK_DIST_CLASSPATH=$(/home/hduser/dt/hadoop-2.7.3/bin/hadoop classpath)
测试Spark
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
通过运行Spark自带的示例,验证Spark是否安装成功。
本地模式下:
$ ./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[*] \
./examples/jars/spark-examples_2.11-2.4.5.jar
执行过程如下所示:

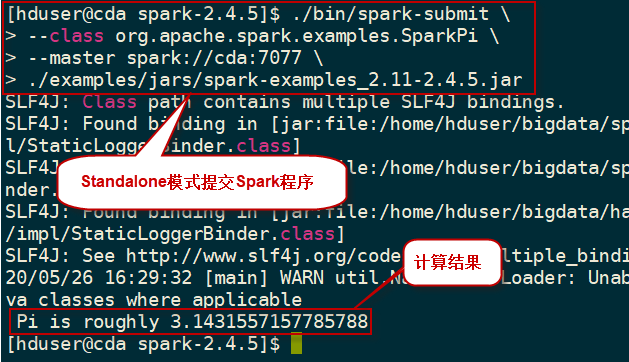
或者,也可以standalone模式(需要先执行./sbin/start-all.sh启动Spark集群):
$ cd ~/bigdata/spark-2.4.5
$ ./sbin/start-all.sh
$ ./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://cda:7077 \
./examples/jars/spark-examples_2.11-2.4.5.jar
执行过程如下所示: