使用IntelliJ IDEA开发Spark SBT应用程序
要开发Spark应用程序,业界普遍采用IntelliJ IDEA这样的集成开发环境。在使用集成开发环境工具开发Spark应用程序时,需要依赖很多Hadoop和Sparkt等的依赖库,目前企业中普遍采用一些项目管理和构建工具(如Maven、SBT等)来管理依赖,以及项目的编译和打包等。Spark官方推荐的是使用SBT(Scala Build Tool,Scala构建工具)来构建Spark项目、管理依赖、编译和打包项目。
本节主要内容包括:
- 安装IntelliJ IDEA
- 配置IntelliJ IDEA Scala环境
- 创建IntelliJ SBT项目
- 配置SBT构建文件
- 准备数据文件
- 创建Spark应用程序
- 部署分布式Spark应用程序
- 远程调试Spark程序
IntelliJ IDEA,一般简称IDEA,是Java语言开发的集成环境。IntelliJ在业界被公认为最好的Java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
下载地址:https://www.jetbrains.com/idea/download/#section=windows
IDEA每个版本提供Community和Ultimate两个版本,如下图所示,其中Community是完全免费的,而Ultimate版本可以使用30天,过这段时间后需要收费。开发Spark应用程序,下载一个最新的Community版本即可。
一、安装IntelliJ IDEA
1.首先在官网下载IDEA https://www.jetbrains.com/idea/download/#section=windows。
双击exe文件,安装。

2.傻瓜式安装,一路Next
接着Next,选择安装路径。路径要记牢哦,后面会用到。
3.耐心等待安装
OK,到这里就安装完成了。
安装完成后,我们就可以启动IntelliJ IDEA了。可以通过两种方式启动:
- 到IntelliJ IDEA安装所在目录下,进入bin目录双击idea.sh启动IntelliJ IDEA;
- 在命令行终端中,进入$IDEA_HOME/bin目录,输入./idea.sh进行启动。
二、配置IntelliJ IDEA Scala环境
在IDEA中开发scala程序(以及spark程序)需要安装scala插件。IDEA默认情况下并没有安装Scala插件,需要手动进行安装。安装过程并不复杂,下面将演示如何进行安装。
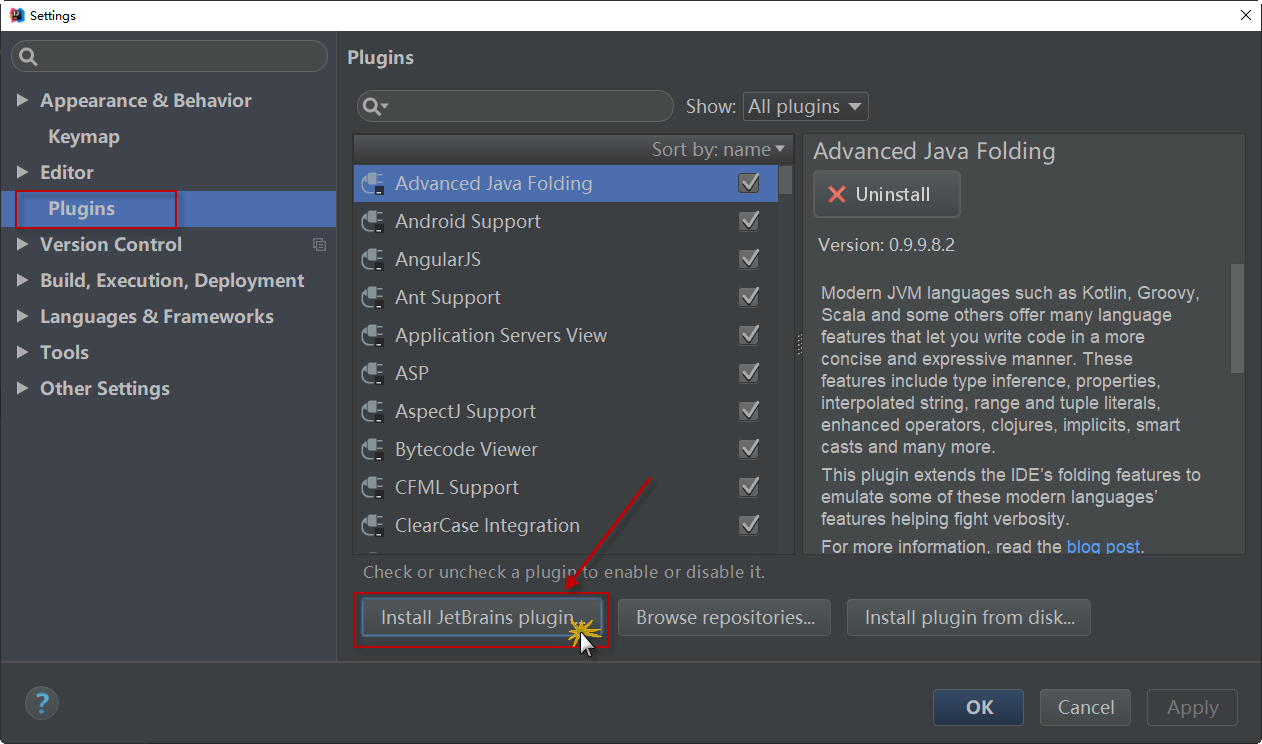
1)在IDEA启动界面上选择“Configure-->Plugins”选项(或者在项目界面,选择“File > Settings... > Plugins”),然后弹出插件管理界面,在该界面上列出了所有安装好的插件。由于Scala插件没有安装,需要点击“Install JetBrains plugins”进行安装,如下图所示:
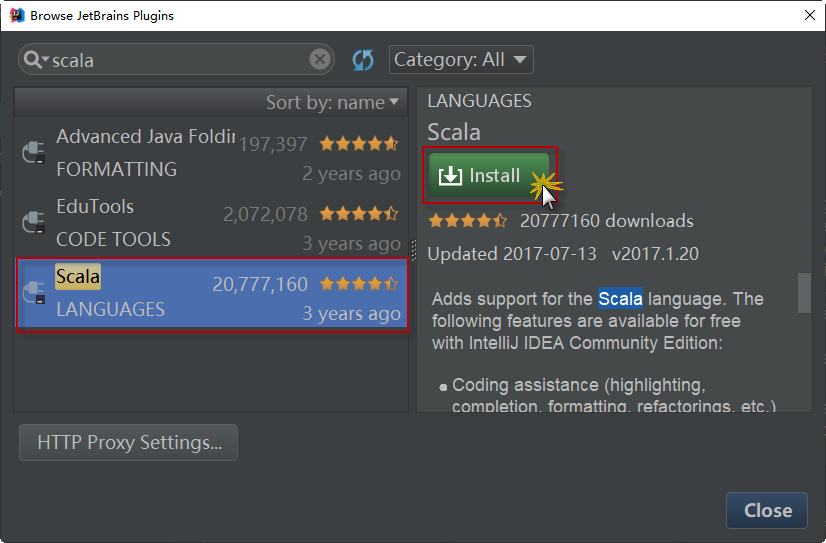
2)待安装的插件很多,可以通过查询或者字母顺序找到Scala插件,选择插件后在界面的右侧出现该插件的详细信息,点击绿色按钮“Install plugin”安装插件,如下图所示:
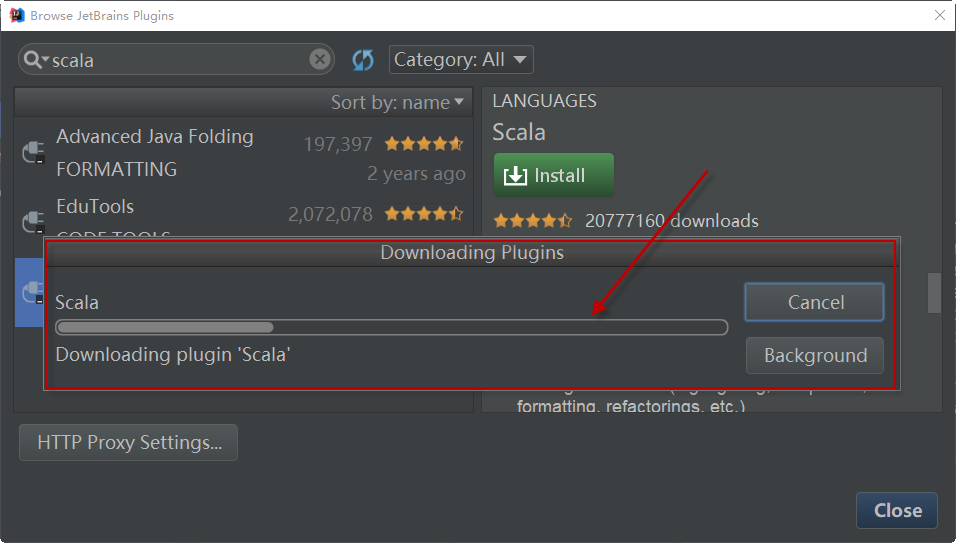
3)安装过程将出现安装进度界面,通过该界面了解插件安装进度,如下图所示:
4)安装完成后,将看到一个按钮,用于重新启动IntelliJ IDE。继续并点击它来重启我们的IntelliJ:
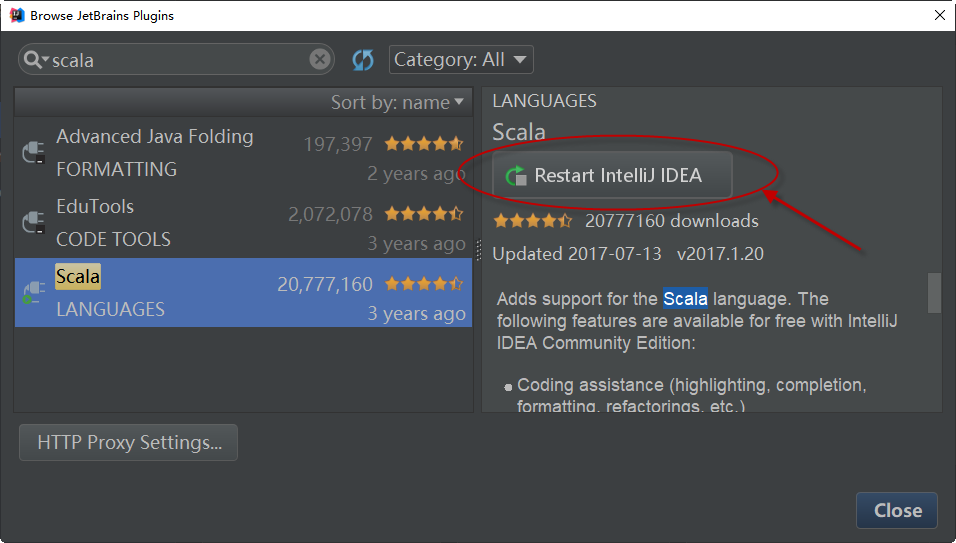
5)最后,重启IntelliJ,让插件生效。
现在我们已经安装了IntelliJ IDEA、Scala插件和SBT,可以开始构建Spark程序了。
三、创建IntelliJ SBT项目
SBT 之于 Scala 就像 Maven 之于 Java,用于管理项目依赖,构建项目。使用IntelliJ IDEA开发Spark应用程序,使用SBT作为构建管理器,这是也官方推荐的开发方式(安装Scala插件时,该Scala插件自带SBT工具)。
请按以下步骤,使用IntelliJ IDEA创建一个新的Spark SBT项目。
1)启动IntelliJ IDEA,在开始界面中,选择【create new project】,创建一个新项目。如下图所示:

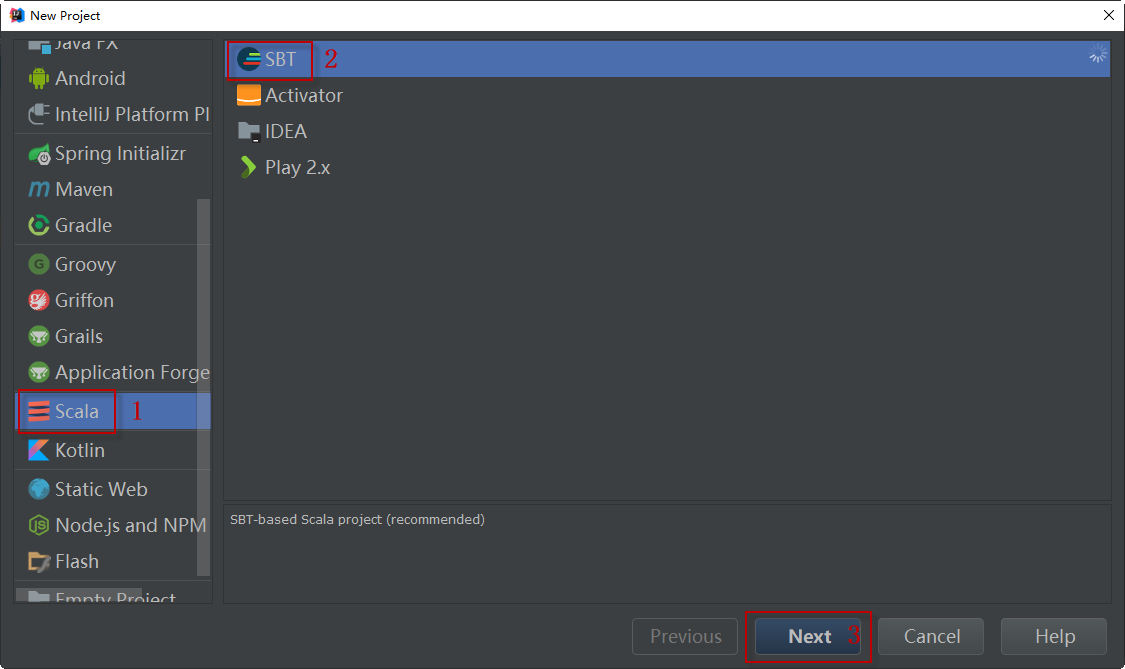
2)接下来,依次选择【Scala】|【sbt】,然后单击【Next】按钮。如下图所示:
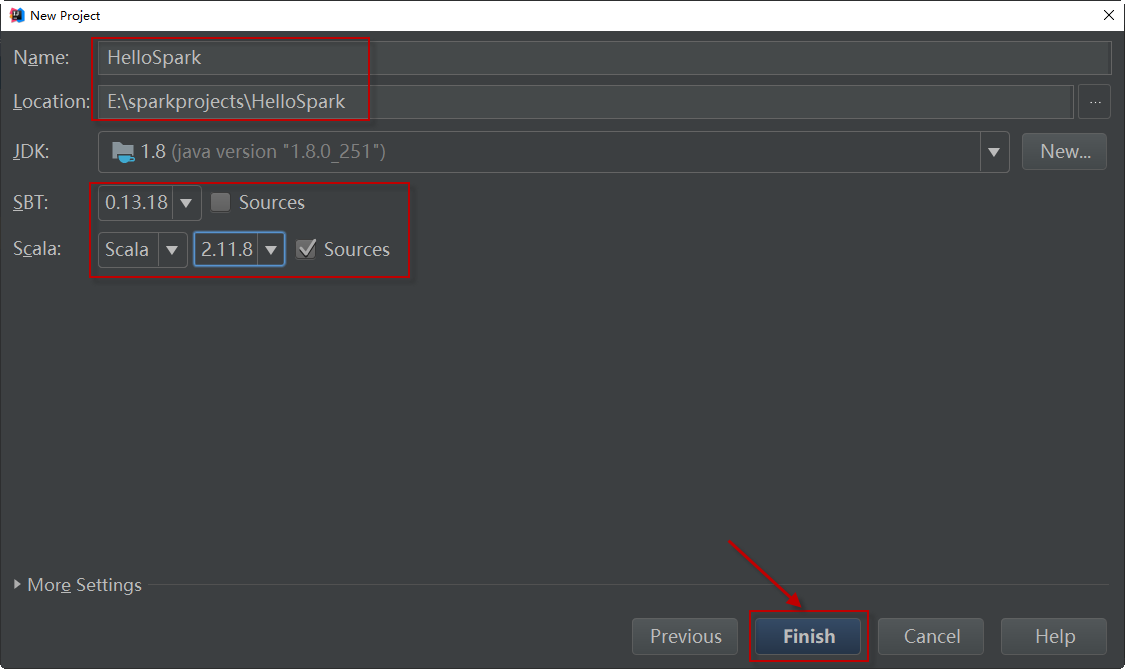
3)在接下来的向导窗口中,将项目命名为“HelloSpark”,指定项目存放的位置,并选择合适的sbt和Scala版本。如下图所示:
4)单击【Finish】按钮继续。IntelliJ应该创建一个具有默认目录结构的新项目。生成所需的所有文件夹可能需要一到两分钟,最终的文件夹结构应该是这样的:
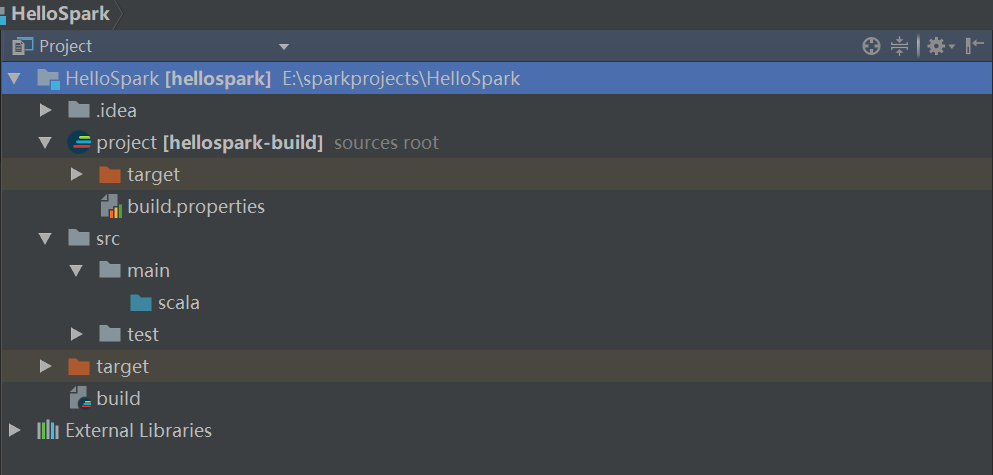
让我们了解一下生成的项目结构,说明如下:
- .idea:这些是IntelliJ配置文件。
- project:编译期间使用的文件。例如,在build.properties中指定编译项目时使用的SBT版本。
- src:源代码。大多数代码应该放在main/scala目录下。测试脚本放在test/scala文件夹下。
- target:当编译项目时,会生成这个文件夹。
- build.sbt:sbt配置文件。使用该文件导入第三方库和文档。
四、配置SBT构建文件
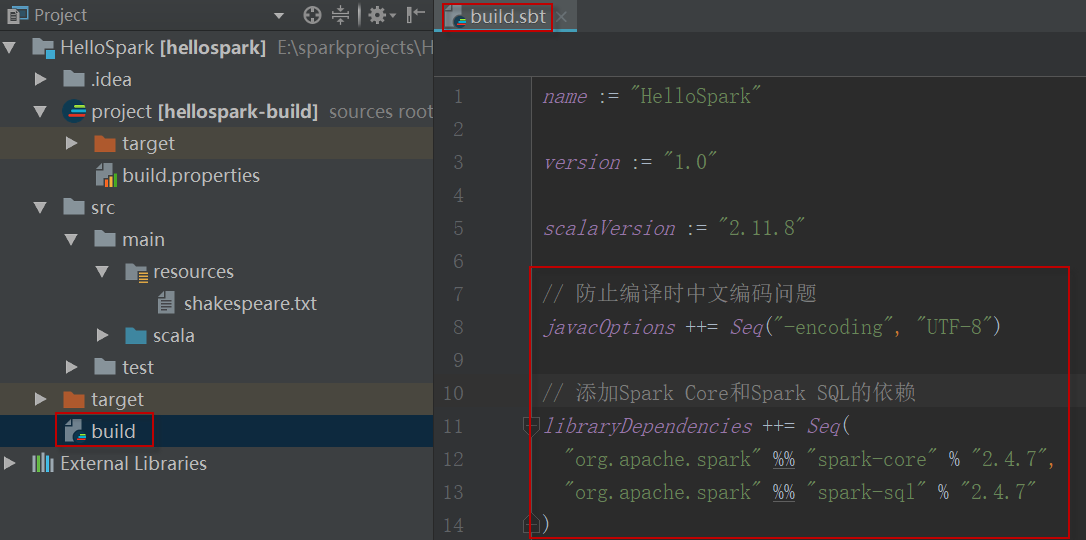
在开始编写Spark应用程序之前,我们需要将Spark库和文档导入IntelliJ,这需要在build.sbt文件中进行配置。编辑build.sbt文件,创建工程时生成的初始内容如下:
name := "HelloSpark" version := "1.0" scalaVersion := "2.12.14"
向其中添加Spark Core和Spark SQL依赖,内容如下:
libraryDependencies ++= Seq( "org.apache.spark" %% "spark-core" % "3.1.2", "org.apache.spark" %% "spark-sql" % "3.1.2" )
说明:SBT依赖库的内容和格式,可以到mvn repository查询。
保存文件后,IntelliJ将自动导入运行Spark所需的库和文档,因此要确保你的电脑是可以连网的。结果如下所示:
五、准备数据文件
接下来,我们将构建一个简单的Spark应用程序,用来对莎士比亚文集(shakespeare.txt)执行单词计数任务。
我们需要在两个地方保存shakespeare.txt数据集。一个在项目中用于本地系统测试,另一个在HDFS (Hadoop分布式文件系统)中用于集群测试。
将PBDP大数据平台中的/home/hduser/data/spark/shakespeare.txt文件上传到HDFS:
1)确保已经启动了HDFS;
2)在终端窗口中,执行以下命令,上传文件到HDFS上:
$ cd /home/hduser/data/spark $ hdfs dfs -put shakespeare.txt /data/spark/
六、创建Spark应用程序
现在,我们准备开始编写Spark应用程序。
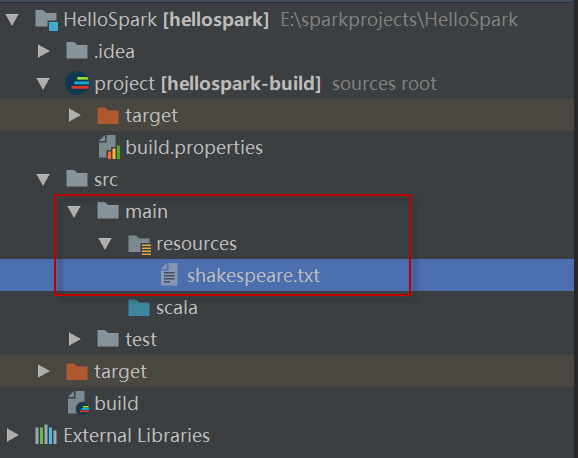
1)回到项目中,在src/main下创建一个名为resources的文件夹(如果它不存在的话),并将shakespear .txt拷贝到该文件夹下。
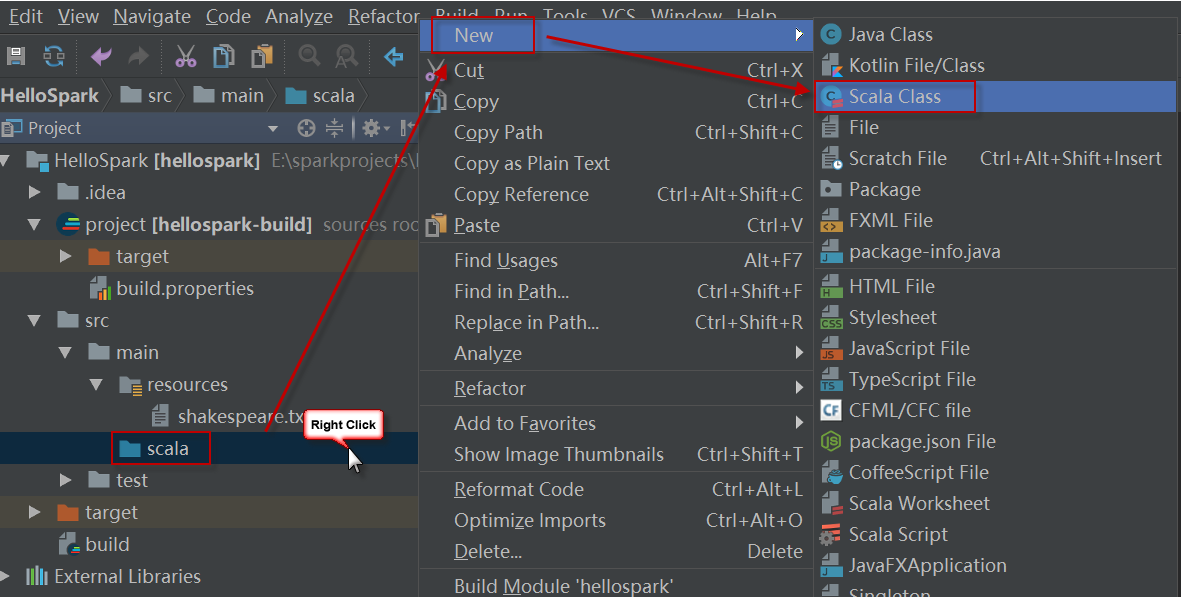
2)接下来,在src/main/scala下创建一个新类。右击“scala > New > Scala Class”,如下图所示:
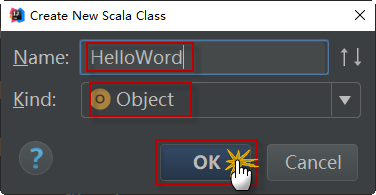
3)接下来,IDE会询问是创建一个class、object还是trait。选择object,将该文件命名为“HelloWord”,如下图所示:
4)编辑该源文件,代码如下:
object HelloWord {
def main(args: Array[String]): Unit ={
println("Hello World!")
}
}
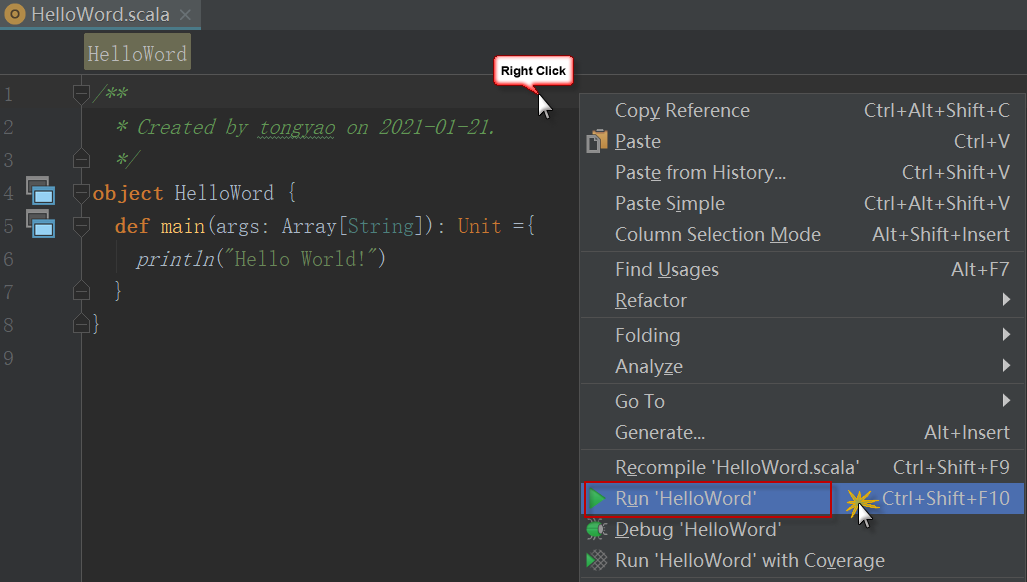
5)运行程序。在文件上任何位置单击右键,在弹出的环境菜单中,选择【Run 'HelloWord'】。
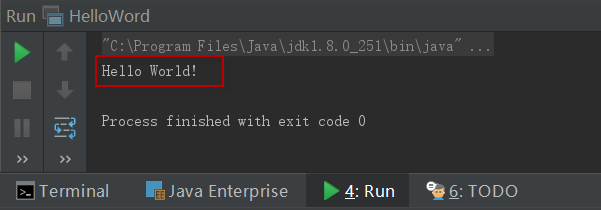
6)如果一切正确,该IDE应该在下方的控制台窗口输出“HelloWorld!”。如下图所示:
7)现在我们知道环境已经正确设置,接下来用以下代码替换文件中原来的内容:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object HelloWord {
def main(args: Array[String]) {
// 在windows下开发时设置
System.setProperty("HADOOP_USER_NAME", "hduser")
// 创建一个SparkContext来初始化Spark
// Spark 2.0以前的用法
// val conf = new SparkConf().setMaster("local").setAppName("Word Count")
// val sc = new SparkContext(conf)
// Spark 2.0以后的用法
val spark = SparkSession.builder().master("local[*]").appName("Word Count").getOrCreate()
val sc = spark.sparkContext
// 将文本加载到Spark RDD中,它是文本中每一行的分布式表示
val file = "src/main/resources/shakespeare.txt"
val textFile = sc.textFile(file)
// transformation转换
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.collect.foreach(println)
System.out.println("全部单词: " + counts.count());
// 将单词计数结果保存到指定文件中
val output = "tmp/shakespeareWordCount"
counts.saveAsTextFile(output)
}
}
8)和刚才一样,右键单击,并选择【Run ' HelloScala'】来运行程序。这将运行Spark作业并打印莎士比亚作品中出现的每个单词的频率,预期输出如下:
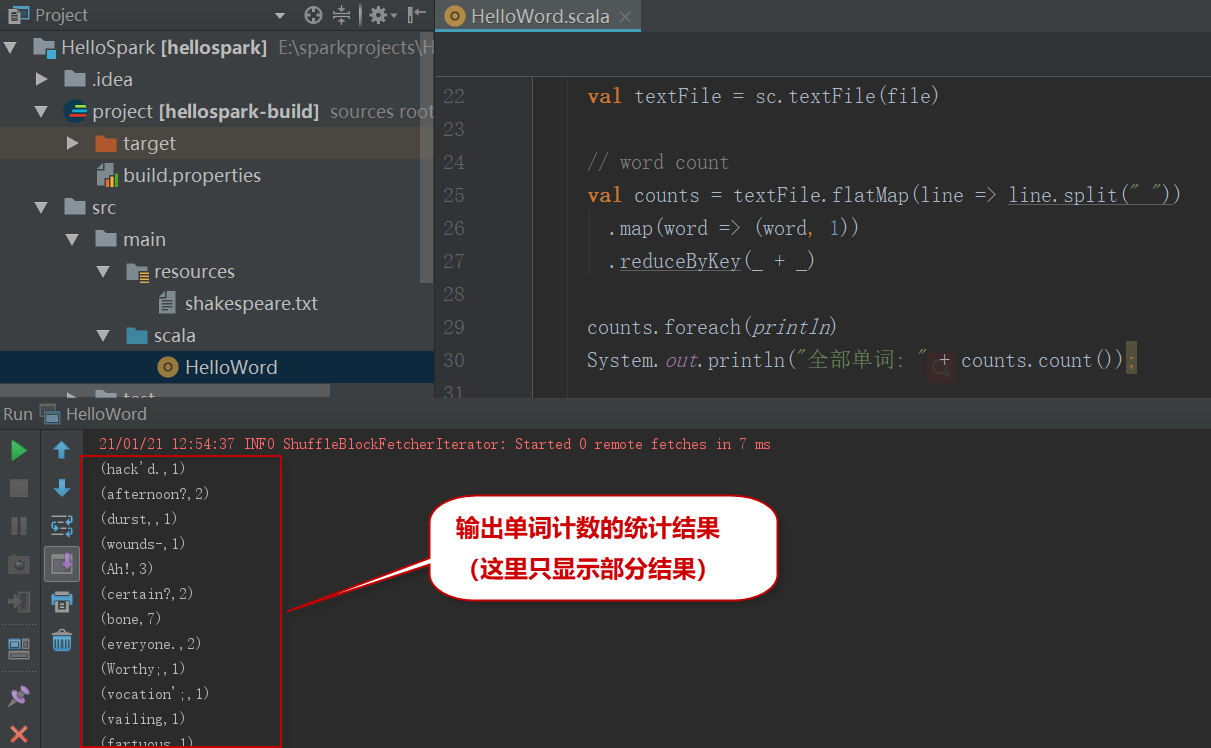
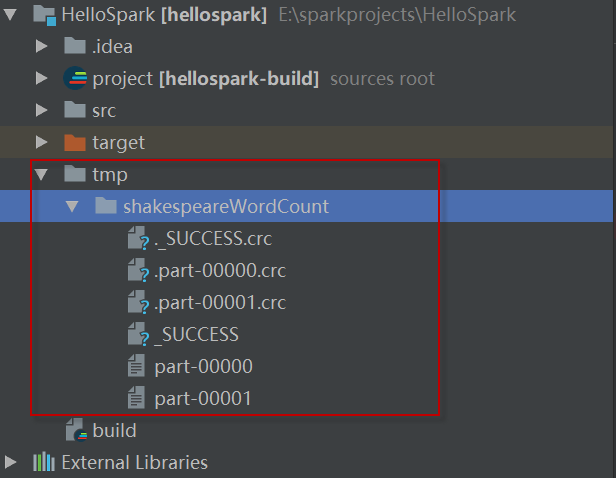
9)此外,如果浏览指定的目录:
counts.saveAsTextFile ("tmp/shakespeareWordCount");
将找到程序的输出:
注意我们在代码中设置了下面这一行代码:
.master("local[*]")
这告诉Spark使用这台计算机在本地运行,而不是在分布式模式下运行。要在多台机器上运行Spark,我们需要更改此值。(稍后我们将看到如何更改)
七、部署分布式Spark应用程序
现在我们已经了解了如何在IDE中直接部署应用程序。这是一种快速构建和测试应用程序的好方法。但是在生产环境中,Spark通常会处理存储在HDFS等分布式文件系统中的数据。Spark通常也以集群模式运行(即分布在许多机器上)。
接下来,我们修改代码,使其能部署到Spark分布式集群上运行。请按以下步骤操作。
1)修改源代码,如下面代码中粗体部分所示:
import org.apache.spark.{SparkConf, SparkContext}
object HelloScala {
def main(args: Array[String]) {
// 创建一个SparkContext来初始化Spark
val spark = SparkSession.builder().appName("Word Count").getOrCreate()
val sc = spark.sparkContext
// 将文本加载到Spark RDD中,它是文本中每一行的分布式表示
val file = "hdfs://localhost:8020/data/spark_demo/shakespeare.txt"
val textFile = sc.textFile(file)
// word count
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.collect.foreach(println)
System.out.println("全部单词: " + counts.count());
// 将单词计数结果保存到指定输出目录中
val output = "hdfs://localhost:8020/data/spark_demo/shakespeareWordCount"
counts.saveAsTextFile(output)
}
}
这告诉Spark读写HDFS,而不是本地。
2)创建JAR文件
我们将把这些代码打包到一个已编译的jar文件中,该文件可以部署在Spark集群上。
在IntelliJ IDEA菜单栏选择【Tools】|【Start SBT Shell】,在编辑窗口下方打开sbt shell交互窗口,然后就可以应用sbt的clean、compile、package等命令进行操作。这里我们执行打包命令:
> package
打包过程如下图所示:
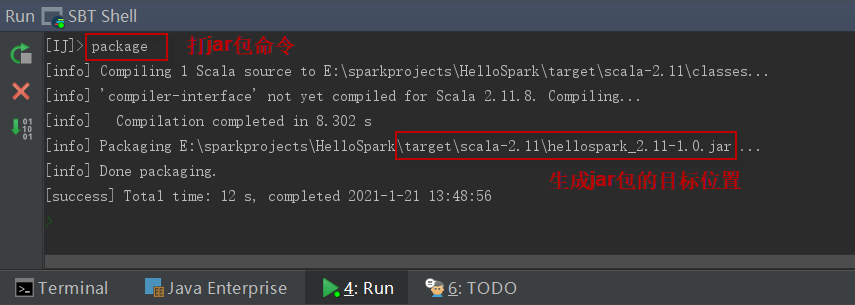
这将在项目的“target/scala-2.11”下创建一个名为“hellospark_2.11-1.0”的编译过的jar文件。
3)将该jar包提交到Spark集群上执行。使用spark-submit运行我们的代码。
$ cd ~/bigdata/spark-3.1.2 $ ./bin/spark-submit --class HelloWord --master local[*] ./hellospark_2.11-1.0.jar
提交任务时需要指定主类、要运行的jar包和运行模式(本地或集群):
4)控制台应该打印莎士比亚作品中出现的每个单词的频率,如下所示:
... (comutual,1) (ban-dogs,1) (rut-time,1) (ORLANDO],4) (Deceitful,1) (commits,3) (GENTLEWOMAN,4) (honors,10) (returnest,1) (topp'd?,1) (compass?,1) (toothache?,1) (miserably,1) (hen?,1) (luck?,2) (call'd,162) (lecherous,2) ...
5)此外,可通过HDFS或Web UI查看输出文件的内容:
$ hdfs dfs -cat /data/spark_demo/shakespeareWordCount/part-00000
八、远程调试Spark程序
在本节中,我们将学习如何将正在运行的Spark程序连接到调试器,调试器允许我们设置断点并逐行执行代码。在直接从IDE运行时,调试Spark和其他任何程序一样,但是调试远程集群需要一些配置。
1)在计划提交Spark作业的机器上,从终端运行以下代码:
$ export SPARK_SUBMIT_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005
2)提交Spark job作业,运行时会出现程序挂起,监听端口中。如下:
$ spark-submit --class HelloWord --master local[*] --driver-java-options bigdata/hellospark_2.11-1.0.jar

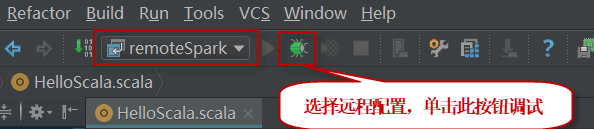
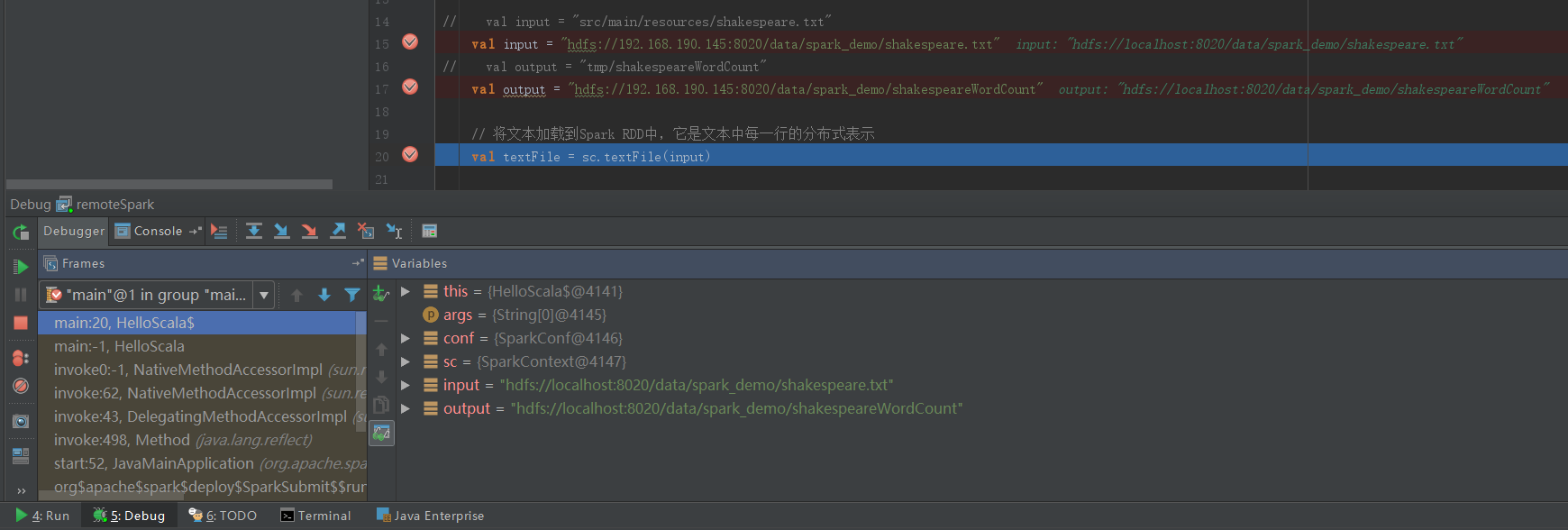
3)在IntelliJ IDEA中配置remote debug:在IntelliJ中选择菜单项【Run】|【Edit Configurations】,编辑运行配置信息。如下:
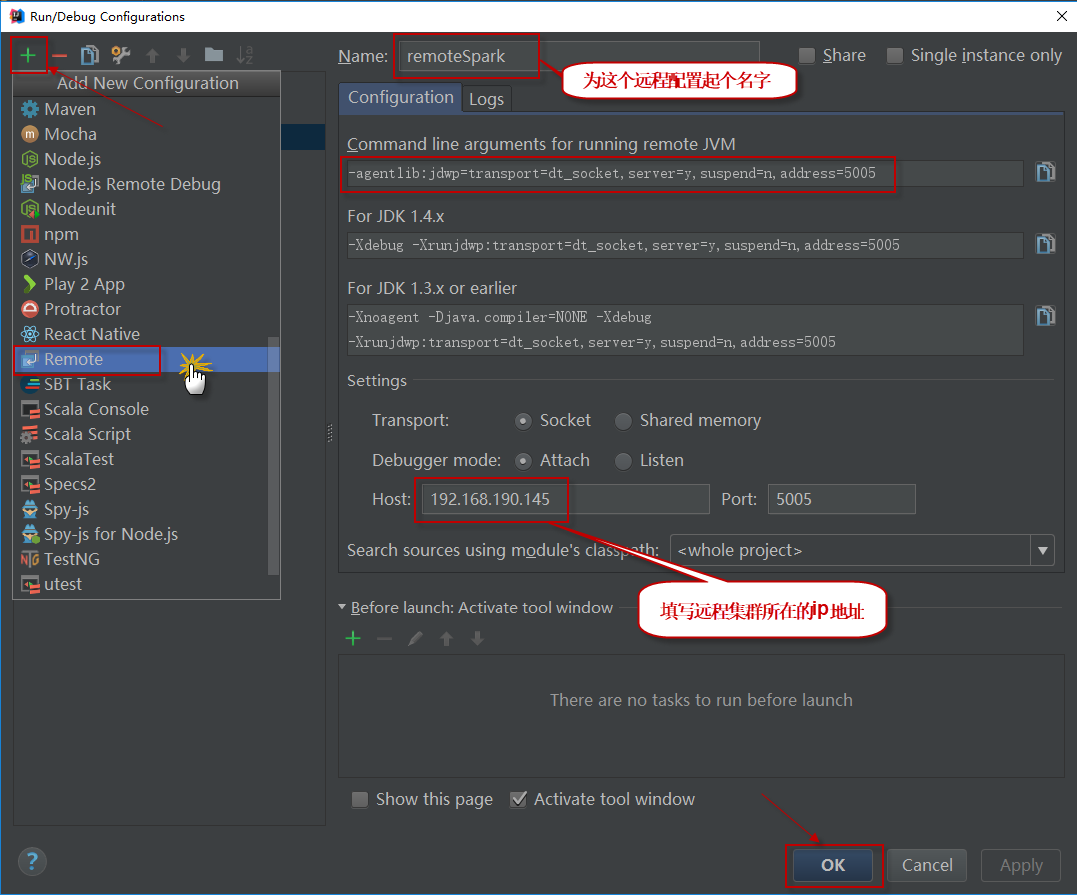
4)然后单击左上角的+按钮,选择面板左侧的Remote项,增加一个新的远程配置。在面板右侧,使用主机ip地址填写Host(Port字段默认为5005,不需要修改),这将允许在端口5005上关联调试器。需要确保端口5005能够接收入站连接。
5)从IDE中debug此调试配置,调试器将附加此调试配置,并且远程Spark程序将在断点处停止。还可以检查程序中活动变量的值。在试图确定代码中的bug时,这是非常宝贵的。