RDD上的Transformation和Action
RDD支持两种类型的操作:transformations和actions。
Transformation是定义如何构建RDD的延迟操作。大多数转换都接受单个函数参数。所有这些方法都将一个数据源转换为另一个数据源。每当在任何RDD上执行转换时,都会生成一个新的RDD,如下图所示:
RDD是不可变的(只读的)数据结构,因此任何转换都会产生新的RDD。转换操作被延迟计算,我们称为“惰性转换”,这意味着Spark将延迟对被调用的操作的执行,直到采取action。当调用action操作将触发对它之前的所有转换的求值,它将向驱动程序返回一些结果,或者将数据写入存储系统,如HDFS或本地文件系统。
简而言之,RDD是不可变的,RDD转换是延迟计算的,RDD action是即时计算的,并触发数据处理逻辑的计算。而在RDD的内部实现机制中,底层接口则是基于迭代器的,从而使得数据访问变得更高效,也避免了大量中间结果对内存的消耗。
通过应用程序操作RDD与操作数据的本地集合类似。请看下面这个简单的代码:
val lines = sc.textFile("hdfs://path/to/the/file")
val filteredLines = lines.filter(line => line.contains("spark")).cache()
val result = filteredLines.count()
上面这段代码的意思是,从HDFS上加载指定的日志文件,找出包含单词"spark"的行数。其在内存中的计算和转换过程可用如下的图来表示:
(1)一个300MB的日志文件,分布式存储在HDFS上,如下图所示:
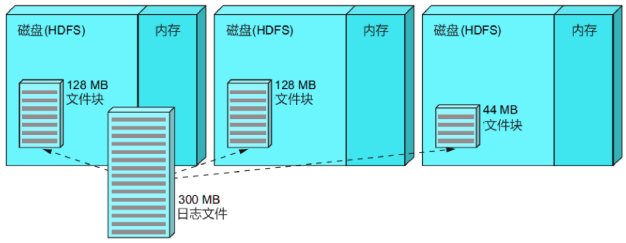
(2)调用这行代码,将其加载到分布式的内存中:
val lines = sc.textFile("hdfs://path/to/the/file")
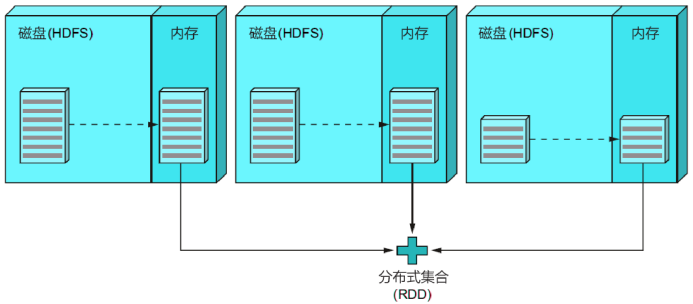
(3)执行下面这行代码,过滤满足条件的行(即只包含单词"spark"的行),这是原始数据集的一个子集,并将这个中间结果缓存到内存中:
val filteredLines = lines.filter(line => line.contains("spark")).cache()
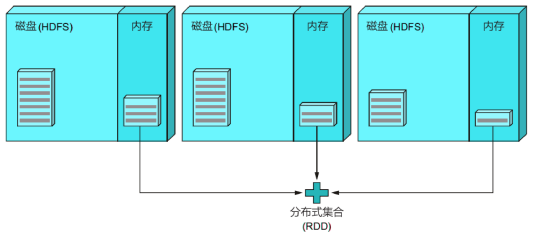
(4)执行最后一行代码,统计过滤后的行数,返回给驱动程序Driver:
val result = filteredLines.count()
