Spark SQL编程案例2_MovieLens数据集分析
本节使用Spark SQL实现对电影数据集进行分析。在这里我们使用推荐领域一个著名的开放测试数据集movielens。MovieLens数据集包括电影元数据信息和用户属性信息。我们将使用其中的users.dat和ratings.dat两个数据集。
【例】使用Spark Dataset API统计看过“Lord of the Rings,The(1978)”的用户的年龄和性别分布(提示该影片的id是“2116”)。
实现过程和代码如下。
1)定义两个类型 case class类,分别定义用户和评分的schema。
case class User(userID:Long, gender:String, age:Integer, occupation:String, zipcode:String) case class Rating(userID:Long, movieID:Long, rating:Integer, timestamp:Long)
2)读取用户数据集users.dat,并注册为临时表users。
import org.apache.spark.sql.functions._
// 创建SparkSession的实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Spark Basic Example")
.getOrCreate()
val sc = spark.sparkContext
// 定义文件路径
val usersFile = "src/main/resources/ml-1m/users.dat"
// 获得RDD
val rawUserRDD = sc.textFile(usersFile)
// 支持RDD到DataFrame的隐式转换
import spark.implicits._
// 对RDD进行转换操作,最后转为DataFrame
val userDF = rawUserRDD
.map(_.split("::"))
.map(x=>User(x(0).toLong, x(1), x(2).toInt, x(3), x(4)))
.toDF()
// 查看用户数据
userDF.printSchema()
userDF.show(5)
输出结果如下所示:
root |-- userID: long (nullable = false) |-- gender: string (nullable = true) |-- age: integer (nullable = true) |-- occupation: string (nullable = true) |-- zipcode: string (nullable = true) +------+------+---+----------+-------+ |userID|gender|age|occupation|zipcode| +------+------+---+----------+-------+ | 1| F| 1| 10| 48067| | 2| M| 56| 16| 70072| | 3| M| 25| 15| 55117| | 4| M| 45| 7| 02460| | 5| M| 25| 20| 55455| +------+------+---+----------+-------+ only showing top 5 rows
3)读取评分数据集ratings.dat,并注册成临时表ratings。
// 定义文件路径
val ratingsFile = "src/main/resources/ml-1m/ratings.dat"
// 生成RDD
val rawRatinngRDD = sc.textFile(ratingsFile)
// 对RDD进行转换,最后转为DataFrame
val ratingDF = rawRatinngRDD
.map(_.split("::"))
.map(x=>Rating(x(0).toLong, x(1).toLong,x(2).toInt,x(3).toLong))
.toDF
// 查看
ratingDF.printSchema()
ratingDF.show(5)
输出结果如下所示:
root |-- userID: long (nullable = false) |-- movieID: long (nullable = false) |-- rating: integer (nullable = true) |-- timestamp: long (nullable = false) +------+-------+------+---------+ |userID|movieID|rating|timestamp| +------+-------+------+---------+ | 1| 1193| 5|978300760| | 1| 661| 3|978302109| | 1| 914| 3|978301968| | 1| 3408| 4|978300275| | 1| 2355| 5|978824291| +------+-------+------+---------+ only showing top 5 rows
4)将两个DataFrame注册为临时表,对应的表名分别为“users”和“ratings”。
userDF.createOrReplaceTempView("users")
ratingDF.createOrReplaceTempView("ratings")
5)通过SQL处理临时表users和ratings中的数据,并输出最终结果。为了简单起见,避免三表连接操作,这里直接使用了movieID。
val MOVIE_ID = "2116"
val sqlStr = s"""select age,gender,count(*) as total_peoples
from users as u join ratings as r on u.userid=r.userid
where movieid=${MOVIE_ID} group by gender,age"""
val resultDF = spark.sql(sqlStr)
// 显示resultDF的内容
resultDF.show()
输出结果如下所示:
+---+------+-------------+ |age|gender|total_peoples| +---+------+-------------+ | 18| M| 72| | 18| F| 9| | 56| M| 8| | 45| M| 26| | 45| F| 3| | 25| M| 169| | 56| F| 2| | 1| M| 13| | 1| F| 4| | 50| F| 3| | 50| M| 22| | 25| F| 28| | 35| F| 13| | 35| M| 66| +---+------+-------------+
6)以交叉表的形式统计不同年龄不同性别用户数。
import org.apache.spark.sql.functions._
resultDF
.groupBy("age")
.pivot("gender")
.agg(sum("total_peoples").as("cnt"))
.show()
输出结果如下所示:
+---+---+---+ |age| F| M| +---+---+---+ | 1| 4| 13| | 35| 13| 66| | 50| 3| 22| | 45| 3| 26| | 25| 28|169| | 56| 2| 8| | 18| 9| 72| +---+---+---+
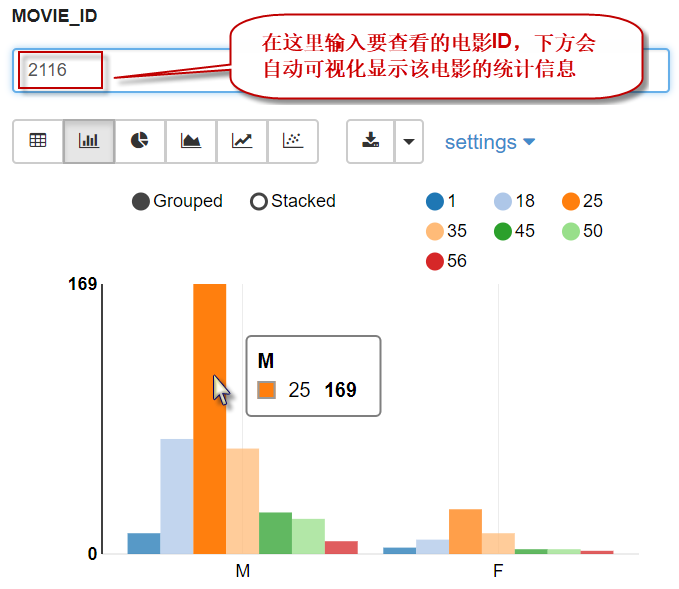
7)在zeppelin中,支持查询结果的可视化显示。在 zeppelin的单元格中,执行以下语句,可视化显示数据(注:第一行必须输入%sql)。
%sql
select age,gender,count(*) as total_peoples
from users as u join ratings as r
on u.userid=r.userid
where movieid=${MOVIE_ID=2116}
group by gender,age
输出结果如下所示: