Sqoop数据迁移
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:MySQL、Oracle、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
Sqoop架构
Sqoop 本身是通过 MapReduce 机制来保证传输数据,从而提供并发特性和容错机制。其系统架构图如下图所示:
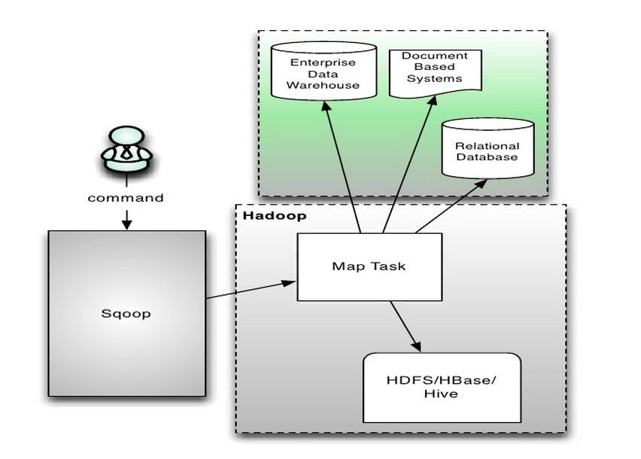
Sqoop 的架构较为简单:
- 通过整合 Hive,实现 SQL 方式的操作;
- 通过整合 HBase,可以向 HBase 写入数据;
- 通过整合 Oozie,拥有了任务流的概念;
- Sqoop 本身是通过 MapReduce 机制来保证传输数据,从而提供并发特性和容错机制。
安装Sqoop
小白学苑的PBLP平台中已经安装好了Sqoop-1.4.7,可以直接使用。如果需要自己安装,请按以下步骤操作。
1)下载Sqoop安装包sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
2)解压到用户主目录下,并重命名为sqoop-1.4.7。
3)配置环境变量。可以使用vi/vim/nano等文本编辑器,打开/etc/profile文件:
$ nano /etc/profile
然后在打开的文件末尾增加如下两行配置:
export SQOOP_HOME=/home/hduser/bigdata/sqoop-1.4.7 export PATH=$PATH:$SQOOP_HOME/bin
保存并关闭文件。然后执行如下命令让配置生效:
$ source /etc/profile
4)将需要连接的数据库驱动文件拷贝至lib目录下。此实例连接mysql数据库,驱动文件为:mysql-connector-java-5.1.34.jar。
注意,hadoop2貌似需要5.1.30以后的mysql驱动版本,否则很可能报错。
Sqoop工作原理
Sqoop是用于大块数据传输,内部它使用MapReduce来读写HDFS上的数据。当运行Sqoop命令时,要被传输的数据会被分解为各种块,并且每个数据赋予一个map job。这些数据切分是并行的,这也是为什么Sqoop能高效地传输bulk数据。
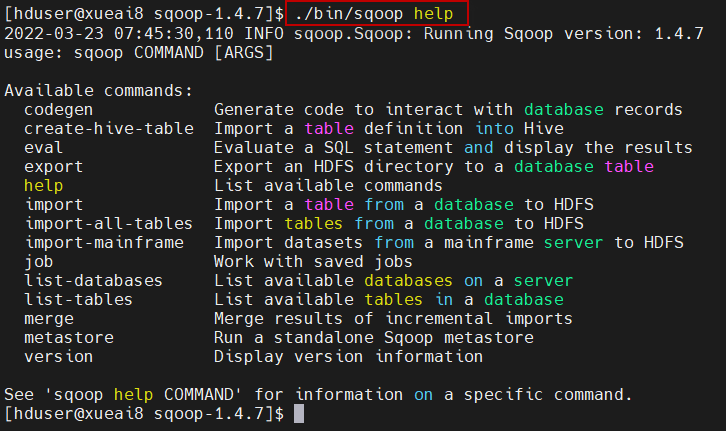
可以使用如下的命令查看Sqoop 命令说明:
$ sqoop help
会输出sqoop命令的帮助提示,如下所示:
如果想查看某个命令的具体用法,可以使用如下两种的方法:
# 查看export命令的用法 # 方法一 $ sqoop help export # 方法二 $ sqoop export --help
将数据从MySQL导入到Hive表中
如果是将数据从MySQL数据库表(db1.t1)中导出到HDFS的指定目录下(/tmp/sqoop_data/),以csv格式存储:
$ sqoop import \ --username root --password 123456 \ --connect jdbc:mysql://localhost:3316/db1 \ --table t1 \ --target-dir /tmp/sqoop_data/ \ --fields-terminated-by ',' \ -m 1
命令中-m的意思是启动多少个并发的mapper。对于伪分布集群来说,这里要指定值为1。
查看导入成功后的HDFS对应目录上的文件(此HDFS目录事先不需要自己建立,Sqoop会在导入的过程中自行建立)
如果是将一个查询结果从MySQL数据库表(db1.t1)中导出到HDFS的指定目录下(/tmp/sqoop_data/),以csv格式存储:
$ sqoop import \ --username root --password 123456 \ --connect jdbc:mysql://localhost:3316/db1 \ --query "select * from tb1 where age>20 and $CONDITIONS" \ --target-dir /tmp/sqoop_data/ \ --fields-terminated-by ',' \ -m 1
Sqoop在导入数据时,可以使用--query搭配sql来指定查询条件,并且还需在sql中添加$CONDITIONS,来实现并行运行mr的功能。
如果是将数据从MySQL数据库表中导入到Hive表中,则需要在导入命令中添加--hive-import参数。例如:
$ sqoop import \ --username root --password 123456 \ --connect jdbc:mysql://localhost:3316/db1 \ --table t1 \ --hive-import --target-dir /tmp/sqoop_data/ \ --delete-target-dir \ --fields-terminated-by ',' \ -m 1
命令执行成功后,在Hive当前数据库中会创建一个”t1”表,包含从MySQL数据库导入的数据
导入时需要注意:
- Hive默认使用\01字符作为列分隔符(字段分隔符),\n和\r作为行分隔符。因此,如果导入的字符型字段的数据中包含这些字符时,就会有问题。
- 可以使用--hive-drop-import-delims参数,将导入数据中的\n,\r,\01字符去掉。也可以使用--hive-delims-replacement替换\n,\r和\01。
将数据从HDFS导出到MySQL
使用hive执行查询,通常将查询结果保存到一张指定表中。保存结果的表,对应HDFS上的一个文件。从HDFS上将存储分析结果的文件导出到MySQL数据表中(先在MySQL中创建好表)。例如:
$ sqoop export --connect jdbc:mysql://localhost:3316/db1 --username root --password 123456 --table mytb --export-dir /user/hive/warehouse/mydb/mytb --input-fields-terminated-by ',' --lines-terminated-by '\n' --columns pv,ip,jumper
--columns参数可以不指定,则将所有字段导出。否则,导出--columns后指定的字段。
然后登录MySQL服务器,查看导入的数据:
mysql> select * from db1.mytb;
