使用分区表进行查询优化
为了便于管理和提高性能,可以将Hive表拆分成更多的逻辑块。
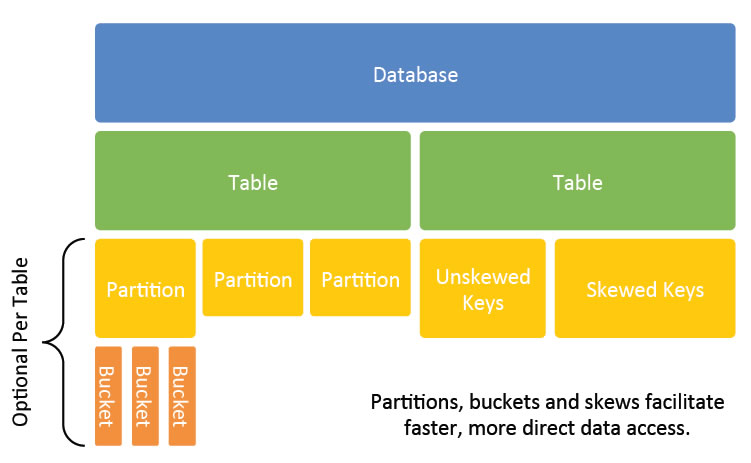
Hive数据模型
在Hive中,数据库和表按照逻辑顺序排列为目录,便于操作和维护。即,Hive逻辑上将数据库和数据表存储为目录。
为什么要使用分区表?
默认情况下,Hive中的查询会扫描整个表来获取结果。
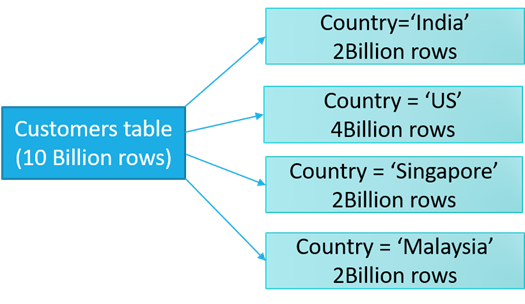
现在,考虑一个Hive表,它有数百万行。当一个简单的查询扫描该表时,它会消耗系统资源。而查询将花费大量时间来获取结果,这最终会影响hive应用程序的性能。
因此,在分析如此大的表时,我们需要一种技术来优化查询的性能,其中一种技术就是Hive中的Partitioning - 表分区。
分区表的意义在于优化查询。查询时尽量利用分区字段。如果不使用分区字段,就会全部扫描。
Hive中如何对表进行分区?
分区是Hive中的一种性能调优技术。它在Hive中使用一列或多列作为分区键在表中创建子目录。
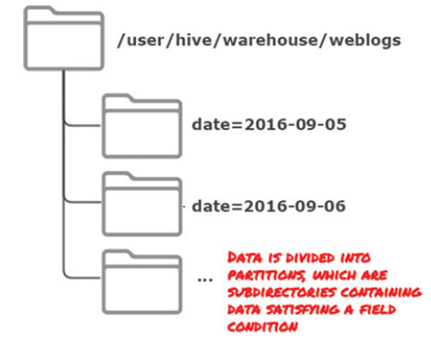
例如,存储交易记录(或其它带有时间戳的数据集,如web日志)按日期分区,一天是一个分区。查询时候,我们可以查询某一天或一段时间的数据,只读取属性该时间的数据,Hive只扫描指定分区的数据分区表,以实现高效查询。
分区表实际就是对应HDFS文件系统上的的独立的文件夹,该文件是夹下是该分区所有数据文件。普通表和分区表的区别在于:一个Hive表在HDFS上是有一个对应的目录来存储数据,普通表的数据直接存储在这个目录下,而分区表数据存储时,是再划分子目录来存储的。一个分区一个子目录。主要作用是来优化查询性能。
例如:
如何创建分区表?
在下面的代码中,我们创建了名为emp的分区表,使用关键字partitioned by:
create table emp(
name string,
age int
) partitioned by (provice string,city string);
在这里,用partitioned by指定创建的分区,多个分区意味着多级目录。在Hive中,可以使用多个列对表进行分区。注意,这里的provice字段和city字段并不在表结构中定义,它们属于表的隐式字段,用来创建对应的物理文件夹。
在Hive中,既可以分区托管表,也可以分区外部表。
插入的数据指定了不同的分区之后,会生成不同的文件夹。
hive> insert into emp partition(provice = "hebei", city = "baoding") values("tom",22);
hive> dfs -ls -R /user/hive/warehouse/;
往表中插入数据之后,会发现在表名对应的目录下,会多出两级目录。
/user/hive/warehouse/mydb.db/emp/provice=hebei /user/hive/warehouse/mydb.db/emp/provice=hebei/city=baoding /user/hive/warehouse/mydb.db/emp/provice=hebei/city=baoding/000000_0
如何加载数据到Hive分区表?
在Hive中有两种分区方式:
- 1) 静态分区:在静态分区中,需要手工将数据插入到表的不同分区。
- 2) 动态分区:在数据插入到表中时会自动进行分区存放。
例如,对于静态分区,批量load数据到不同的分区上:
hive>load data local inpath '/home/user1/emp.txt' overwrite into table t1 partition(provice = "hebei",city = "baoding"); hive>load data local inpath '/home/user1/emp.txt' overwrite into table t1 partition(provice = "hebei",city = "handan");
对于动态分区,可以在往表中插入数据的时候,动态的根据值来选择数据进入的分区。
hive>load data local inpath '/home/user1/emp.txt' overwrite into table t1 partition(provice,city); hive>load data local inpath '/home/user1/emp.txt' overwrite into table t1 partition(provice,city);
动态分区默认是没有开启。可以通过执行以下命令开启动态分区。
hive> set hive.exec.dynamic.partition.mode=nonstrict // 分区模式,默认strict hive> set hive.exec.dynamic.partition=true // 开启动态分区,默认false hive> set hive.exec.max.dynamic.partitions=1000 //最大动态分区数, 设为1000
Hive动态分区模式有两种:strice(严格模式)和nostrice(非严格模式)。
开启后默认是以严格模式执行的,在这种模式下需要至少一个分区字段是静态的。这有助于阻止因设计错误导致查询产生大量的分区。例如:用户可能错误使用时间戳作为分区表字段。然后导致每秒都对应一个分区!
我们可以关闭严格分区模式。
不管是静态分区还是动态分区,创建分区表的语法是一样的(区别在于插入数据时是否需要手工指定分区)。
查看表的分区信息
在插入两个分区的数据之后,查看表的分区信息,就会将这个表的所有分区都显示出来。
hive> show partitions mydb.table;
使用分区对数据进行过滤
分区表使用的分区字段不是在数据中存在的(比如创建了一个国家分区,但是数据中并没有这个字段),分区字段只是为了在HDFS上产生了对应的子目录。
在使用hive查询的时候,完全可以使用where对分区进行过滤。
hive> select * from t3 where city='changchun';
修改分区
修改分区意味着对原有的分区进行增减,即重构分区。
添加分区:不改变分区的级数,而是改变分区字段的值。
hive> alter table emp add partition(provice = "hebei", city = "shijiazhuang"); hive> show partitions emp;
分区对应的是HDFS上的目录,分区的删除涉及到对应的数据是否会被删除的问题。如果此表是内部表的话,那么分区的删除意味着对应目录下的数据会被删除;如果是外部表的话,分区的删除就不会删除对应的数据文件。
hive> alter table emp drop partition(provice = "hebei", city = "shijiazhuang"); hive> show partitions emp;
