HDFS读写操作
一、HDFS中的读操作
数据读请求由HDFS、NameNode和DataNode提供服务。下图描述了Hadoop中的文件读取操作。
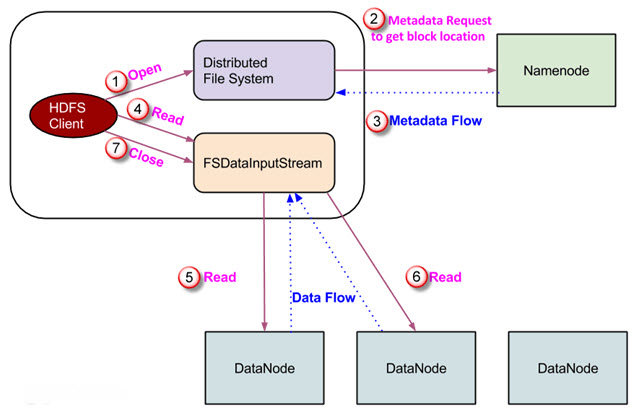
- 客户端通过调用FileSystem对象的open()方法发起读请求。FileSystem是DistributedFileSystem类型的对象。
- 该对象使用RPC连接到NameNode,并获取元数据信息,如文件块的位置。请注意,这些地址是一个文件的前几个块。
- 为了响应这个元数据请求,NameNode返回拥有该块副本的DataNode的地址。
- 一旦接收到DataNode的地址,一个类型为FSDataInputStream的对象将返回给客户端。 FSDataInputStream包含DFSInputStream, DFSInputStream负责与DataNode和NameNode的交互。 在上图所示的步骤4中,客户端调用read()方法,该方法导致DFSInputStream与拥有文件的第一个块的第一个DataNode建立连接。
- 数据以流的形式读取,其中客户端重复调用read()方法。read()操作的这个过程继续进行,直到到达块的末尾。
- 一旦到达一个块的末尾,DFSInputStream关闭连接,并继续为下一个块查找下一个DataNode。
- 一旦客户端完成读取,它就调用close()方法。
二、HDFS中的写操作
在本节中,我们将了解数据是如何通过文件写入HDFS的。

- 客户端通过调用DistributedFileSystem对象的create()方法来发起写操作,该方法会创建一个新文件。如上图中的步骤1所示。
- DistributedFileSystem对象使用RPC调用连接到NameNode,并启动新的文件创建。 但是,此文件创建操作不将任何块与该文件关联。 NameNode负责验证文件(正在创建的文件)事先并不存在,并且客户端拥有创建新文件的正确权限。 如果文件已经存在,或者客户端没有足够的权限创建新文件,那么IOException将被抛出给客户端。 否则操作成功,NameNode将为该文件创建一条新的记录。
- 一旦NameNode中创建了一条新记录,一个FSDataOutputStream类型的对象将返回给客户端。客户端使用它向HDFS写入数据。调用数据写入方法(图中的第3步)。
- FSDataOutputStream包含DFSOutputStream对象,它负责与DataNode和NameNode的通信。 当客户端继续写数据时,DFSOutputStream继续用该数据创建数据包。这些包被放入一个称为DataQueue的队列中。
- 有一个称为DataStreamer的组件使用/消费这个DataQueue。DataStreamer还要求NameNode分配新块,从而选择需要用于复制的DataNode。
- 现在,复制的过程从使用DataNode创建管道开始。在我们的示例中,我们选择了3个备份的复制,因此在管道中有3个DataNode。
- DataStreamer将数据包注入管道中的第一个DataNode。
- 管道中的每个DataNode存储它收到的数据包,并将其转发给管道中的第二个DataNode。
- 另一个确认队列(Ack队列)由DFSOutputStream负责维护,用来存储等待DataNode确认的数据包。
- 一旦从管道中的所有DataNode接收到队列中的一个包的确认,它将从Ack队列中删除。在任何DataNode失败的情况下,将使用来自该队列的数据包重新启动操作。
- 客户端写完数据后,它调用close()方法(图中的第9步)。调用close(),结果是将剩余的数据包刷新到管道,然后等待确认。
- 一旦收到最终的确认信息,就会联系NameNode,告诉它文件写入操作已经完成。
