MapReduce案例-写入数据库表
读写数据库是构建Hadoop ETL工具的基础。
Hadoop确实提供了各种数据类型,如IntWritable、FloatWritable、DoubleWritable等, 但是要访问数据库的话,我们需要实现自定义OutputWritable,这将使我们能够将数据行写入数据库表。
为了实现自定义输出可写,我们必须实现DBWritable接口。
问题描述
考虑这样一个情况,我们在HDFS中有csv文本文件,其中包含一个在线零售商店的产品细节,文件包含数百万行,所以现在我们有兴趣将这些记录加载到数据库中。
我们的HDFS csv文件包含我们想要加载到RDBMS的产品的唯一记录。 csv文本文件包含以下格式的记录:StockCode,Description,Quantity。
其中:
- StockCode是产品的唯一股票代码。
- Description是产品的名称/描述。
- Quantity是特定产品的库存数量。
products.csv
85123A,WHITE HANGING HEART T-LIGHT HOLDER,100 71053,WHITE METAL LANTERN,116 84406B,CREAM CUPID HEARTS COAT HANGER,80 84029G,KNITTED UNION FLAG HOT WATER BOTTLE,6123 84029E,RED WOOLLY HOTTIE WHITE HEART.,612 22752,SET 7 BABUSHKA NESTING BOXES,2345 21730,GLASS STAR FROSTED T-LIGHT HOLDER,786 22633,HAND WARMER UNION JACK,216 22632,HAND WARMER RED POLKA DOT,12656 84879,ASSORTED COLOUR BIRD ORNAMENT,322 22745,POPPY'S PLAYHOUSE BEDROOM ,986 22748,POPPY'S PLAYHOUSE KITCHEN,8716 22749,FELTCRAFT PRINCESS CHARLOTTE DOLL,1248 22310,IVORY KNITTED MUG COSY ,5326 84969,BOX OF 6 ASSORTED COLOUR TEASPOONS,2126 22623,BOX OF VINTAGE JIGSAW BLOCKS ,4213 22622,BOX OF VINTAGE ALPHABET BLOCKS,721 21754,HOME BUILDING BLOCK WORD,9823 21755,LOVE BUILDING BLOCK WORD,2653 21777,RECIPE BOX WITH METAL HEART,4635 48187,DOORMAT NEW ENGLAND,7864 22960,JAM MAKING SET WITH JARS,9876 22913,RED COAT RACK PARIS FASHION,2389 22912,YELLOW COAT RACK PARIS FASHION,7342 22914,BLUE COAT RACK PARIS FASHION,6423 21756,BATH BUILDING BLOCK WORD,435 22728,ALARM CLOCK BAKELIKE PINK,23674 22727,ALARM CLOCK BAKELIKE RED ,12234 22726,ALARM CLOCK BAKELIKE GREEN,5132
准备工作
1)在MySQL中创建数据表:
-- 创建数据库 xueai8
create database xueai8;
-- 打开数据库 xueai8
use xueai8;
-- 在当前数据库中创建产品表products
CREATE TABLE products (
stockcode VARCHAR(45) NOT NULL,
description VARCHAR(45) NOT NULL,
quantity INT,
PRIMARY KEY (stockcode)
);
-- 查询,目前为空
select * from products;
2)读取RDBMS需要从Hadoop到MySql的数据库连接,所以我们需要将相关的驱动程序jar文件放到Hadoop的lib文件夹中, 所以在我们的例子中,我们已经将mysql-connector-java-5.1.38-bin.jar文件复制到HADOOP common的lib文件夹中。 另外,我们必须将该jar文件复制到启动作业的机器上。
一、创建Java Maven项目
Maven依赖:注意,需要增加mysql驱动依赖。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>HadoopDemo</groupId>
<artifactId>com.xueai8</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!--hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<!--hdfs文件系统依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<!--MapReduce相关的依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.1</version>
</dependency>
<!--mysql驱动程序-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<!--junit依赖-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!--编译器插件用于编译拓扑-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<!--指定maven编译的jdk版本和字符集,如果不指定,maven3默认用jdk 1.5 maven2默认用jdk1.3-->
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source> <!-- 源代码使用的JDK版本 -->
<target>1.8</target> <!-- 需要生成的目标class文件的编译版本 -->
<encoding>UTF-8</encoding><!-- 字符集编码 -->
</configuration>
</plugin>
</plugins>
</build>
</project>
DBMapper.java:
Mapper类。处理读取的每条产品信息,提取stockCode为key。
package com.xueai8.tomysql;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class DBMapper extends Mapper <LongWritable, Text, Text, Text> {
private Text outKey = new Text();
// 71053,WHITE METAL LANTERN,116
@Override
protected void map(LongWritable id, Text value, Context context) {
try{
String[] productValues = value.toString().split(",");
outKey.set(productValues[0]); // stockCode为key
context.write(outKey,value); // 整条记录为value
} catch (Exception exception) {
exception.printStackTrace();
}
}
}
DBOutputWritable.java:
从数据库读取或写入的对象应该实现DBWritable。 DBWritable类似于Writable,但write方法参数采用PreparedStatement,而readFields方法参数采用ResultSet。 实现负责将对象的字段写入PreparedStatement,并从ResultSet读取对象的字段。
package com.xueai8.tomysql;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
public class DBOutputWritable implements Writable, DBWritable{
private int quantity;
private String stockCode;
private String description;
public DBOutputWritable(){}
public DBOutputWritable(String stockCode,String description,int quantity){
this.stockCode = stockCode;
this.description = description;
this.quantity = quantity;
}
// 写入到数据库的方法
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1, this.stockCode);
statement.setString(2, this.description);
statement.setInt(3, this.quantity);
}
// 从数据库中读取字段的方法
public void readFields(ResultSet resultSet) throws SQLException {
this.stockCode = resultSet.getString(1);
this.description = resultSet.getString(2);
this.quantity = resultSet.getInt(3);
}
// Writable接口中的方法
public void write(DataOutput out) throws IOException {
}
// Writable接口中的方法
public void readFields(DataInput in) throws IOException {
}
}
DBReducer.java:
Reducer类。在该类中组装 DBOutputWritable key。
package com.xueai8.tomysql;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class DBReducer extends Reducer <Text,Text,DBOutputWritable,NullWritable>{
// ("71053", ["71053,WHITE METAL LANTERN,116"])
@Override
protected void reduce(Text key, Iterable <Text> values, Context context)
throws IOException, InterruptedException {
// values只有一个值,因为key没有相同的
StringBuilder finalValue = new StringBuilder();
for(Text text : values){
finalValue.append(text);
}
// 分词
String[] productValues = finalValue.toString().split(",");
// 构建输出key
DBOutputWritable productRecord = new DBOutputWritable(productValues[0], productValues[1], Integer.parseInt(productValues[2]));
// 写出
context.write(productRecord, NullWritable.get());
}
}
DBDriver.java:
驱动程序。注意DBOutputKeyClass和DBOutputFormat的设置。
package com.xueai8.tomysql;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class DBDriver extends Configured implements Tool {
public static void main(String[] args) throws Exception {
// 数据输入路径和输出路径
int ec = ToolRunner.run(new DBDriver(), args);
System.exit(ec);
}
@Override
public int run(String[] args) throws Exception {
if(args.length != 1) {
System.out.println("用法: DBDriver <input>");
System.exit(1);
}
/*
* 配置数据库.主要包括以下几项:
* 1、数据库驱动的名称:com.mysql.jdbc.Driver
* 2、数据库URL:jdbc:mysql://localhost:3306/xueai8
* 3、用户名:root
* 4、密码:admin
*/
DBConfiguration.configureDB(getConf(),
"com.mysql.jdbc.Driver", // 驱动程序类
"jdbc:mysql://192.168.190.133:3306/xueai8", // db url
"root", // 账号
"admin"); // 密码
// 新建一个任务
Job job = Job.getInstance(getConf(), "DB Demo");
job.setJarByClass(DBDriver.class);
job.setMapperClass(DBMapper.class);
job.setReducerClass(DBReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// reducer输出格式
job.setOutputKeyClass(DBOutputWritable.class);
job.setOutputValueClass(NullWritable.class);
job.setInputFormatClass(TextInputFormat.class);
// 需要指定输出格式为DBOutputFormat(默认就是TextOutputFormat)
job.setOutputFormatClass(DBOutputFormat.class);
// 输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 输出到哪些表、字段: 第2个参数:表名,第3个参数开始:字段名
DBOutputFormat.setOutput(job,
"products", // 输出表名
"stockcode","description","quantity" // 表列
);
// 提交任务
return job.waitForCompletion(true) ? 0 : 1;
}
}
二、配置log4j
在src/main/resources目录下新增log4j的配置文件log4j.properties,内容如下:
log4j.rootLogger = info,stdout
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
三、项目打包
打开IDEA下方的终端窗口terminal,执行"mvn clean package"打包命令,如下图所示:
如果一切正常,会提示打jar包成功。如下图所示:
这时查看项目结构,会看到多了一个target目录,打好的jar包就位于此目录下。如下图所示:
四、项目部署
请按以下步骤执行。
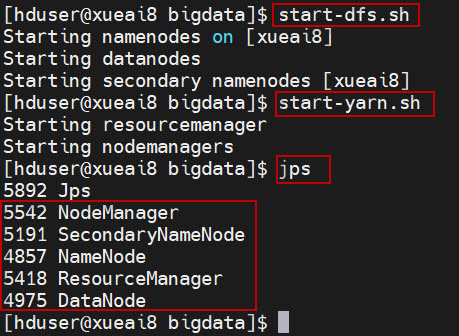
1、启动HDFS集群和YARN集群。在Linux终端窗口中,执行如下的脚本:
$ start-dfs.sh
$ start-yarn.sh
查看进程是否启动,集群运行是否正常。在Linux终端窗口中,执行如下的命令:
$ jps
这时应该能看到有如下5个进程正在运行,说明集群运行正常:
5542 NodeManager
5191 SecondaryNameNode
4857 NameNode
5418 ResourceManager
4975 DataNode
2、将数据文件products.csv上传到HDFS的/data/mr/目录下。
$ hdfs dfs -mkdir -p /data/mr $ hdfs dfs -put products.csv /data/mr/ $ hdfs dfs -ls /data/mr/
3、提交作业到Hadoop集群上运行。(如果jar包在Windows下,请先拷贝到Linux中。)
在终端窗口中,执行如下的作业提交命令(注意,只有一个命令行参数,为读取的csv文件的路径):
$ hadoop jar com.xueai8-1.0-SNAPSHOT.jar com.xueai8.tomysql.DBDriver /data/mr
4、查看输出结果。
在MySQL终端窗口中,执行如下的查询命令,查看表内容:
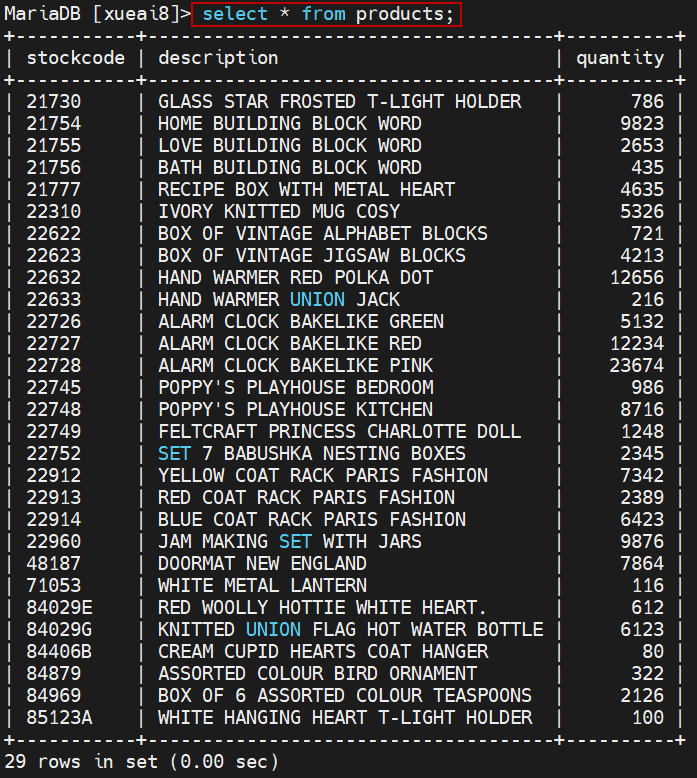
mysql> select * from products;
可以看到如下的输出结果: