HDFS架构设计
一、什么是HDFS?
HDFS是一个分布式文件系统,用于存储非常大的数据文件,运行在商用硬件集群上。它具有容错性、可伸缩性,而且扩展非常简单。
当数据超过单个物理机器上的存储容量时,就必须将其划分到多个独立的机器上进行存储。 跨计算机网络管理特定于存储操作的文件系统称为分布式文件系统。HDFS就是这样一种分布式文件系统软件。
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),源自于Google于2003年10月发表的GFS论文,是GFS的开源实现。 它具有如下特点:
- (1)易于扩展的分布式文件系统
- (2)运行在大量普通廉价机器上,提供容错机制
- (3)为大量用户提供性能不错的文件存取服务
二、HDFS的优缺点
HDFS的优点如下:
- (1)高容错性:数据自动保存多个副本,副本丢失后,会自动恢复。
- (2)适合批处理:移动计算而非数据、数据位置暴露给计算框架。
- (3)适合大数据处理:GB、TB、甚至PB级数据、百万规模以上的文件数量,1000以上节点规模。
- (4)流式文件访问:一次性写入,多次读取;保证数据一致性。
- (5)可构建在廉价机器上:通过多副本提高可靠性,提供了容错和恢复机制。
HDFS的缺点如下:
- (1)低延迟数据访问:比如毫秒级、低延迟与高吞吐率。
- (2)小文件存取:占用NameNode大量内存,寻道时间超过读取时间。
- (3)并发写入、文件随机修改:一个文件只能有一个写者,仅支持append。
三、HDFS的设计目标
HDFS在设计之初就定下要实现以下目标:
- 硬件故障是常态。因此存储需要冗余。
- 流式数据访问。即数据批量读取而非随机读写,Hadoop擅长做的是数据分析而不是事务处理。
- 大规模数据集
- 简单一致性模型。为了降低系统复杂度,对文件采用一次性写多次读的逻辑设计,即是文件一经写入,关闭,就再也不能修改。
- 采用“计算向数据靠拢”的原则,将计算代码分配到数据所在节点执行-移动计算而不移动数据。
HDFS特殊的设计,在实现上述优良特性的同时,也使得自身具有一些应用局限性,主要包括以下几个方面:
- 不适合低延迟数据访问。
- 无法高效存储大量小文件。
- 不支持多用户写入及任意修改文件。
四、HDFS架构
HDFS有一个主/从架构。HDFS集群主要由管理文件系统元数据的NameNode和存储实际数据的DataNodes组成。HDFS的架构如下图所示:
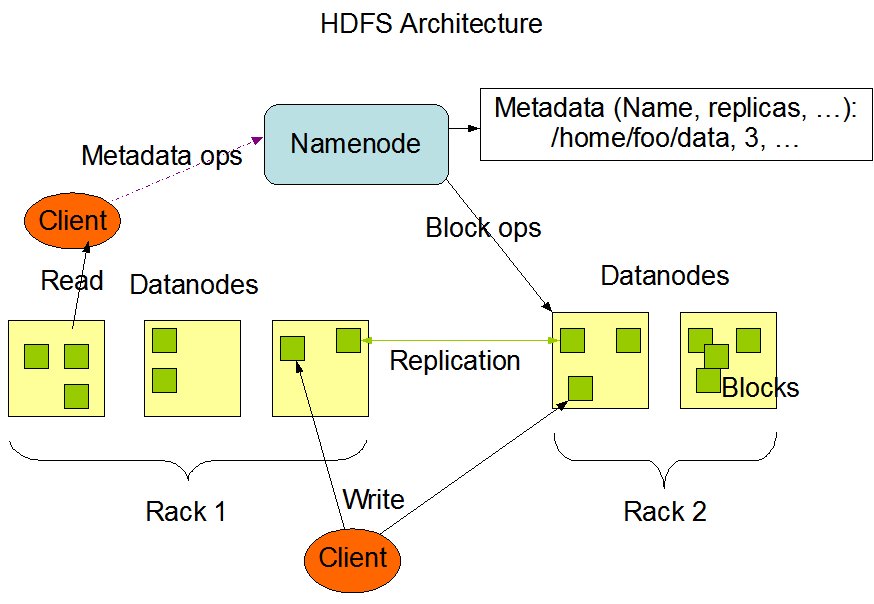
- NameNode: NameNode可以被认为是系统的master(主节点)。它维护文件系统树和系统中所有文件和目录的元数据。 两个文件“命名空间映像”和“编辑日志”用于存储元数据信息。 Namenode知道包含给定文件数据块的所有数据节点,但是,它不会持久化存储块位置。 当系统启动时,这些信息每次都从datanode中重建。
- DataNode: DataNode是驻留在集群中的每台机器上的slave(从节点),提供实际的存储。它负责为客户端提供服务和读写请求。
HDFS的读写操作是块级别的。HDFS中的数据文件被分割成块大小的block,这些块被存储为独立的单元。默认的块大小在Hadoop-2.x和Hadoop-3.x中是128M,在Hadoop-1.x中是64M。
HDFS会创建多个数据块的副本,并分布在整个集群的节点上,以便在节点故障时实现数据的高可用性。默认情况下每个block有三个副本,这个副本数量也是可以调整的。
