Hadoop-3.2.1环境搭建(3)_完全分布模式
说明:平台基于CentOS 7.x操作系统。用户名及软件安装目录如下:
| 环境 | 设置或路径 |
|---|---|
| 用户名 | hduser |
| 用户主目录 | /home/hduser |
| 软件安装包位于 | /home/hduser/software |
| 软件安装位置 | /home/hduser/bigdata/ |
Hadoop集群由三台节点组成。其中maste机器既充当主节点,也充当其中一个从节点。
集群节点IP分布如下(一个主节点,三个从节点):
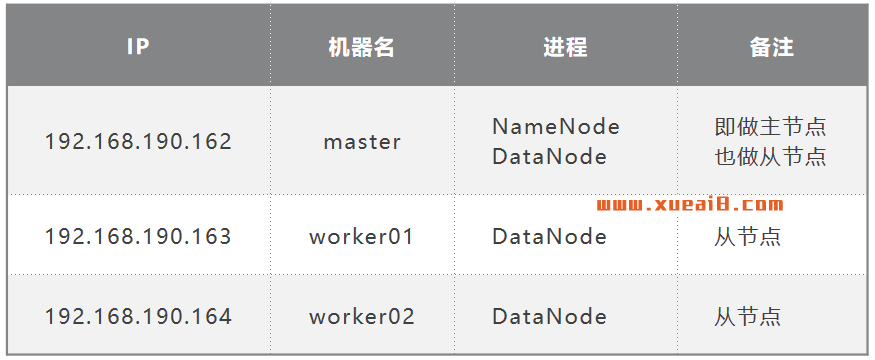
集群结构设计如下图:
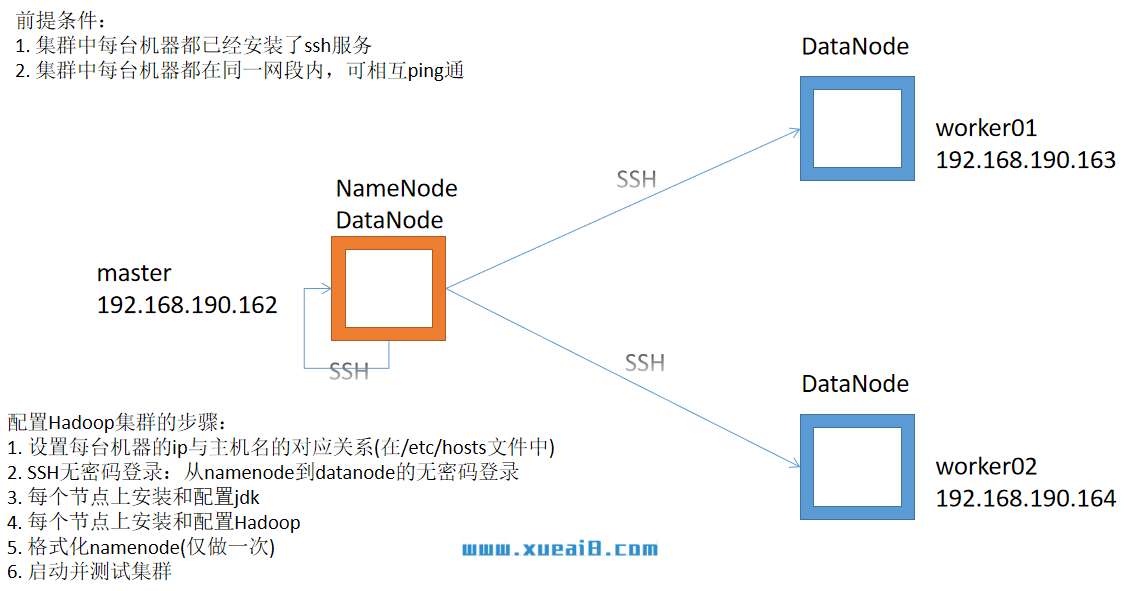
一、前期准备:
1、将集群中每台机器的IP修改为唯一。例如,我这里分别为:(根据自己的情况设置自己机器的IP)
192.168.190.162 192.168.190.163 192.168.190.164
2、每台机器的主机名(hostname)改为唯一,分别为:
master worker01 worker02
修改主机名的方法说明:
2.1 在master机器的终端窗口中,执行以下命令修改机器名为master:
$ sudo hostnamectl set-hostname master
2.2 在worker01机器的终端窗口中,执行以下命令修改机器名为worker01:
$ sudo hostnamectl set-hostname worker01
2.3 在worker02机器的终端窗口中,执行以下命令修改机器名为worker02:
$ sudo hostnamectl set-hostname worker02
3、设置每台机器的ip与主机名的对应关系:
编辑"/etc/hosts"文件:
$ sudo nano /etc/hosts
添加如下内容(IP和机器名的映射):
192.168.136.162 master 192.168.136.163 worker01 192.168.136.164 worker02
注:请将原文件最上面的第二行127.0.1.1 删除掉,每台机器都要做。
6、集群中每台机器均要关闭防火墙。
二、安装和配置SSH无密码登录
SSH无密登录原理:
namenode作为客户端,要实现无密码公钥认证,连接到服务端datanode上时,需要在namenode上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到datanode上。当namenode通过ssh连接datanode时,datanode就会生成一个随机数并用namenode的公钥对随机数进行加密,并发送给namenode。namenode 收到加密数之后再用私钥进行解密,并将解密数回传给datanode,datanode确认解密数无误之后就允许namenode进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将namenode公钥复制到datanode上。
1、在每台机器上,执行如下命令:
$ cd ~ $ ssh localhost $ ssh exit # 记得最后通过这个命令退出ssh连接
2、在namenode(master主机)上,使用如下命令生成公私钥:
$ cd .ssh $ ssh-keygen -t rsa
然后一路回车,在.ssh目录下生成公私钥。
3、将namenode(master主机)上的公钥分别加入master、worker01和worker02机器的授权文件中。 在namenode(master主机)上,执行如下命令:
$ ssh-copy-id hduser@master $ ssh-copy-id hduser@worker01 $ ssh-copy-id hduser@worker02
4、测试。在master节点机器上,使用ssh分别连接master、worker01和worker02:
$ ssh master $ exit $ ssh worker01 $ exit $ ssh worker02 $ exit
这时会发现不需要输入密码,直接就ssh连接上了这两台机器。
三、安装和配置JDK(三个节点都要做)
将提前下载的"jdk-8u181-linux-x64.tar.gz"安装包,拷贝到CentOS中的"~/software"目录下 ;
1、使用如下命令,进入到"/usr/local"目录下:
$ cd /usr/local
2、在"/usr/local"目录下,将刚才的jdk拷贝到当前目录下:
$ sudo cp ~/software/jdk-8u181-linux-x64.tar.gz ./
3、解压缩"jdk-8u181-linux-x64.tar.gz"安装包到"/usr/local/"目录下:
$ sudo tar -zxvf jdk-8u181-linux-x64.tar.gz
4、配置环境变量
首先,打开配置文件(如果未安装nano编辑器,可以使用vim编辑器打开):
$ sudo nano/etc/profile
在打开的”/etc/profile”文件中,最后一行的后面一行,添加如下内容(注意,标点符号全都要是英文半角):
export JAVA_HOME=/usr/local/jdk1.8.0_181 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$PATH
然后保存。
5、执行”/etc/profile”文件,让配置生效:
$ source /etc/profile
6、验证JDK环境变量是否配置正确:
$ javac -version $ java -version
四、在master节点上安装Hadoop
1、将hadoop安装包"hadoop-3.2.1.tar.gz",拷贝到CentOS中的"~/software/"目录下 。
2、将Hadoop压缩包,解压缩到"/home/hduser/bigdata"目录(用户主目录/bigdata)下 :
$ cd ~ $ mkdir bigdata $ cd bigdata $ tar -zxvf ~/software/hadoop-3.2.1.tar.gz
3、打开"/etc/profile"配置文件,配置hadoop环境变量(注意,标点符号全都要是英文半角):
export HADOOP_HOME=/home/hduser/bigdata/hadoop-3.2.1 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
然后保存。
4、执行"/etc/profile",让配置生效:
$ source /etc/profile
5、测试hadoop安装:
$ hadoop version
五、在master节点上配置Hadoop
配置Hadoop,共需要配置6个文件,均位于Hadoop安装目录下的"etc/hadoop/"子目录下。首先进入到该目录下:
$ cd ~/bigdata/hadoop-3.2.1/etc/hadoop
1、配置hadoop-env.sh文件:
$ nano hadoop-evn.sh
然后找到并修改JAVA_HOME属性的值:
export JAVA_HOME=/usr/local/jdk1.8.0_181
2、配置core-site.xml文件:
$ nano core-site.xml
找到其中的"<configuration></configuration>"标签,在其中指定各个配置参数,如下所示:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020/</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hduser/bigdata/hadoop-3.2.1/dfs/tmp</value> </property> <property> <name>hadoop.proxyuser.hduser.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hduser.groups</name> <value>*</value> </property> </configuration>
3、配置hdfs-site.xml文件:
$ nano hdfs-site.xml
找到其中的"<configuration></configuration>"标签,在其中指定各个配置参数,如下所示:
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hduser/bigdata/hadoop-3.2.1/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser/bigdata/hadoop-3.2.1/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.datanode.max.transfer.threads</name> <value>4096</value> </property> </configuration>
4、配置mapred-site.xml文件
$ nano mapred-site.xml
找到其中的"<configuration></configuration>"标签,在其中指定各个配置参数,如下所示:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration>
5、配置yarn-site.xml文件
$ nano yarn-site.xml
找到其中的"<configuration></configuration>"标签,在其中指定各个配置参数,如下所示:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> </configuration>
6、配置从节点workers:
使用如下命令打开workers文件,在该文件中指定集群的从节点机器名或IP地址。
$ nano workers
将里面的localhost删除,写入集群中各个从节点的机器名,每个一行,然后保存文件。
master worker01 worker02
7、将配置好的hadoop-3.2.1文件夹,分别拷贝到worker01和worker02的bigdata目录下:
$ scp -r ~/bigdata/hadoop-3.2.1 hduser@worker01:~/bigdata $ scp -r ~/bigdata/hadoop-3.2.1 hduser@worker02:~/bigdata
六、在master节点上格式化HDFS文件系统
格式化HDFS(仅需执行格式化一次)。在master节点的终端窗口中,执行下面的命令:
$ hdfs namenode -format
注:如果因为某些原因需要从头重新配置集群,那么在重新格式化HDFS之前,先把各节点Haoop下的dfs目录删除。 这个目录是在hdfs-site.xml文件中自己指定的,其下有两个子目录name和data,重新格式化之前必须删除它们。
七、在Hadoop上执行MR程序
1、首先启动HDFS集群:
$ start-dfs.sh
这个命令将首先启动一个master节点中的NameNode进程。 然后它将启动在workers文件中所提及到的所有机器中的DataNode服务。 最后,它将启动SecondaryNameNode。
2、使用jps命令查看当前节点上运行的服务:
$ jps
3、查看块状态报告:
$ hdfs dfsadmin -report
4、查看HDFS文件系统根目录:
$ hdfs dfs -ls /
5、成功启动后,可以通过Web界面查看NameNode 和 Datanode 信息和HDFS文件系统。
NameNode Web接口:http://master:9870。注意,其中的master是主节点的机器名。
6、启动yarn:
$ start-yarn.sh $ jps
7、启动historyserver历史服务器和timelineserver时间线服务器:
$ mapred --daemon start historyserver $ yarn --daemon start timelineserver
8、运行pi程序:
先进入到程序示例.jar包所在的目录,然后运行MR程序:
$ cd ~/bigdata/hadoop-3.2.1/share/hadoop/mapreduce $ hadoop jar hadoop-mapreduce-examples-3.2.1.jar pi 10 20
在输出内容中,可以找到计算出的PI值。
9、可以通过 Web 界面查看:
打开浏览器,在地址栏输入:http://master:8088
查看任务进度:http://master:8088/cluster ,在 Web 界面点击 “Tracking UI” 这一列的 History 连接,可以看到任务的运行信息。同样,URL中的cda是我的机器名,请替换为你自己的机器名。
10、关闭集群:
$ stop-yarn.sh $ stop-dfs.sh $ mapred --daemon stop historyserver $ yarn --daemon stop timelineserver
