MapReduce表连接_半连接
假设一个场景,需要连接两个很大的数据集, 两个数据集都不是足够小到可以缓存在map作业的内存中。 那么,有没有办法来优化map端连接呢?
可以思考以下问题:如果其中一个数据集可以“瘦身”到足够小(小到可以放入内存时),那么是不是就可以执行map端join连接了呢?
这就是可能存在的第二种情况:有一个数据集经过过滤后可以放入内存缓存中;(在两个数据集中都存在join key)。
案例描述
有两个数据集logs.txt和users.txt(假设两个数据集都很大,大到都无法直接加载到内存中)。其中 logs.txt为基于用户的一些活动(可从应用程序或web服务器日志中抽取出来),包括用户名、活动、源IP地址; users.txt中为用户数据,包括用户名、年龄和所在地区。
文件logs.txt:
anne 22 NY joe 39 CO alison 35 NY mike 69 VA marie 27 OR jim 21 OR bob 71 CA mary 53 NY dave 36 VA dude 50 CA
文件users.txt:
213.59.105.58 CA 166.36.182.90 UK 221.220.8.0 US 229.48.154.221 UK
希望经过MapReduce连接这两个都“很大”的数据集,同时避免经过shuffle和sort阶段。
解决方案
在这个例子中,在用户日志logs.txt中的用户仅仅是OLTP用户数据users.txt中的用户中的很小的一部分。 那么就可以从OLTP用户数据中只取出存在于用户日志中的那部分用户的用户数据。 然后就可以得到足够小到可以放在内存中的数据集。这种的解决方案就叫做“半连接”。
在这个技术中,将会用到三个MapReduce作业来连接两个数据集,以此来减少reduce端连接的消耗。
这个技术在这种场景下非常有用:连接两个很大的数据集,但是可以通过过滤与另一个数据集不匹配的记录来减少数据的大小,使得可以放入task的内存中。
一、创建Java Maven项目
Maven依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>HadoopDemo</groupId>
<artifactId>com.xueai8</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!--hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<!--hdfs文件系统依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
</dependency>
<!--MapReduce相关的依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.1</version>
</dependency>
<!--junit依赖-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!--编译器插件用于编译拓扑-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<!--指定maven编译的jdk版本和字符集,如果不指定,maven3默认用jdk 1.5 maven2默认用jdk1.3-->
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source> <!-- 源代码使用的JDK版本 -->
<target>1.8</target> <!-- 需要生成的目标class文件的编译版本 -->
<encoding>UTF-8</encoding><!-- 字符集编码 -->
</configuration>
</plugin>
</plugins>
</build>
</project>
二、第一个MapReduce job
第一个MapReduce job的功能是从日志文件中提取出用户名,用这些用户名生成一个用户名唯一的集合(Set)。 这通过在map函数执行用户名的投影操作来实现,并反过来使用reducer来产生这些用户名。
为了减少在map阶段和reduce阶段之间传输的数据量,采用如下方法: 在map任务中采用哈希集HashSet来缓存所有的用户名,并在cleanup方法中输出该HashSet的值。
SemiJoinJob1.java:
package com.xueai8.semijoin;
import java.io.IOException;
import java.net.URI;
import java.util.HashSet;
import java.util.Set;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
*
* 第1个作业:对其中可以优化的数据集进行预处理,减少数据量(到可放入内存中)
*/
// 从logs.txt表中抽取用户名(考虑主-外键引用关系,这里相当于先在从表中找出被引用的外键列唯一值)
public class SemiJoinJob1 extends Configured implements Tool {
// 使用KeyValueTextInputFormat类
// 输入的是logs.txt表中的每条记录
public static class Map extends Mapper<Text, Text, Text, NullWritable> {
// 用来缓存用户名(过滤后的 小数据集)
private Set<String> keys = new HashSet<>();
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
keys.add(key.toString()); // 将用户名加入缓存,重复的用户名只会保留一个
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
Text outputKey = new Text();
for (String key : keys) {
outputKey.set(key);
// 从mapper输出缓存的用户名
context.write(outputKey, NullWritable.get());
}
}
}
// 输出结果就是瘦身以后的数据集
// 作业1的结果就是来自于日志文件中的所有用户的集合。集合中的用户名是唯一的。
public static class Reduce extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
// 从reducer输出每个用户名一次
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
int returnCode = ToolRunner.run(new SemiJoinJob1(), args);
System.exit(returnCode);
}
public int run(String[] args) throws Exception {
if (args.length < 2) {
System.err.println("用法: SemiJoinJob1 <logspath> <outpath>");
System.exit(-1);
}
Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]); // 唯一用户名表结果输出路径:/output/semijoin1/
Job job1 = Job.getInstance(getConf(), "SemiJoinJob1");
job1.setJarByClass(getClass());
job1.setMapperClass(Map.class);
job1.setReducerClass(Reduce.class);
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(NullWritable.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(NullWritable.class);
job1.setInputFormatClass(KeyValueTextInputFormat.class); // 注意这里
job1.setOutputFormatClass(TextOutputFormat.class);
// 如果输出目录存在,则先删除
FileSystem fs = FileSystem.get(outputPath.toUri(), getConf());
if(fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
FileInputFormat.setInputPaths(job1, inputPath);
FileOutputFormat.setOutputPath(job1, outputPath);
boolean flag = job1.waitForCompletion(true);
return flag? 0 : 1;
}
}
作业1的结果就是来自于日志文件中的所有用户的集合。集合中的用户名是唯一的。
三、第二个MapReduce job
第二步是一个复杂的过滤MapReduce job,目标是从全体用户的用户数据集中移除不存在于日志文件中的用户。
这是一个map-only job,它使用一个复制连接来缓存出现在日志文件中的用户名,并把他们和用户数据集进行连接。
由于job 1输出的唯一用户的数据集实际上要远远小于整个用户数据集,所以很自然地就把来自job 1的唯一用户集放到缓存中了。
SemiJoinJob2.java:
package com.xueai8.semijoin;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashSet;
import java.util.Set;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
*
* 注意,要先上传job1的输出文件part-r-00000到分布式缓存
*/
public class SemiJoinJob2 extends Configured implements Tool {
public static class Map extends Mapper<Object, Text, Text, NullWritable> {
public static final String CATCH_USERNAME_FILENAME = "part-r-00000";
private Set<String> userSet = new HashSet<>();
private Text outputKey = new Text();
// 先从分布式缓存中读取被缓存到本地的文件
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] patternsURIs = context.getCacheFiles(); // 获取缓存文件的uri
Path patternsPath = new Path(patternsURIs[0].getPath()); // 这里我们只缓存了一个文件
String patternsFileName = patternsPath.getName(); // 获得缓存文件的文件名
System.out.println("===patternsFileName: " + patternsFileName);
// 从分布式缓存中读取job 1的输出,并存入到HashMap中
if (CATCH_USERNAME_FILENAME.equals(patternsFileName)) {
BufferedReader br = new BufferedReader(new FileReader("output/semijoin1/" + patternsFileName));
String line;
while ((line=br.readLine()) != null) { // line就是缓存的用户名
userSet.add(line); // 放入HashSet中
}
br.close();
}
if (userSet.isEmpty()) {
throw new IOException("无法加载唯一的用户表");
}
}
// 输入的是users.txt中的每条记录
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String row = value.toString();
String[] tokens = row.split("\t");
String username = tokens[0]; // 取每条用户记录中的用户名字段
if (userSet.contains(username)) { // 过滤
outputKey.set(row);
context.write(outputKey, NullWritable.get()); // 输出整行用户记录
}
}
}
// 这是个map端处理,不需要reducer
// main方法
public static void main(String[] args) throws Exception {
int returnCode = ToolRunner.run(new SemiJoinJob2(), args);
System.exit(returnCode);
}
@Override
public int run(String[] args) throws Exception {
if (args.length < 3) {
System.err.println("用法: SemiJoinJob2 <userpath> <outpath> <catchpath>");
System.exit(-1);
}
Path inputPath = new Path(args[0]); // 需要瘦身的用户表users.txt
Path outputPath = new Path(args[1]);// 瘦身以后的用户表的输出路径:/output/semijoin2/
Path cachePath = new Path(args[2]); // 应为job 1唯一用户名表的缓存路径:/output/semijoin1/part-r-00000
Job job2 = Job.getInstance(getConf(), "SemiJoinJob2");
// 将part-r-00000文件放入分布式缓存中
// "output/semijoin1/part-r-00000"
job2.addCacheFile(cachePath.toUri());
job2.setJarByClass(getClass());
job2.setMapperClass(Map.class);
job2.setNumReduceTasks(0); // 不需要reduce
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(NullWritable.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(NullWritable.class);
job2.setInputFormatClass(TextInputFormat.class);
job2.setOutputFormatClass(TextOutputFormat.class);
// 如果输出目录存在,则先删除
FileSystem fs = FileSystem.get(outputPath.toUri(), getConf());
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
FileInputFormat.setInputPaths(job2, inputPath);
FileOutputFormat.setOutputPath(job2, outputPath);
boolean flag = job2.waitForCompletion(true);
return flag? 0 : 1;
}
}
作业2的输出就是已被用户日志数据集的用户名过滤过的用户集了。
四、第三个MapReduce job
在这最后一步中,我们将合并从job 2输出的过滤后的用户和原始的用户日志。 现在被过滤后的用户已经小到可以驻留在内存中了,这样就可以将它们放入分布式缓存中。
SemiJoinJob3.java:
package com.xueai8.semijoin;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class SemiJoinJob3 extends Configured implements Tool {
public static class JoinMap extends Mapper<Object, Text, Text, Text> {
public static final String CATCH_USERS_FILENAME = "part-m-00000";
private Map<String, String> usersMap = new HashMap<>();
private Text outputKey = new Text();
private Text outputValue = new Text();
// 先从分布式缓存中读取被缓存到本地的文件
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] patternsURIs = context.getCacheFiles(); // 获取缓存文件的uri
Path patternsPath = new Path(patternsURIs[0].getPath()); // 这里我们只缓存了一个文件
String patternsFileName = patternsPath.getName(); // 获得缓存文件的文件名
System.out.println("===patternsFileName: " + patternsFileName);
// 从分布式缓存中读取job 2的输出,并存入到HashMap中
if (CATCH_USERS_FILENAME.equals(patternsFileName)) {
patternsFileName = "output/semijoin2/" + patternsFileName;
BufferedReader br = new BufferedReader(new FileReader(patternsFileName));
String line;
while ((line=br.readLine()) != null) {
String username = line.split("\t")[0];
usersMap.put(username, line); // 整行内容放入HashMap中
}
br.close();
}
if (usersMap.isEmpty()) {
throw new IOException("无法加载瘦身用户表");
}
}
// 输入的是logs.txt中的日志信息,需要和缓存中的用户信息连接
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String row = value.toString();
String username = row.split("\t")[0]; // 取每条日志记录的用户名字段
String user = usersMap.get(username); // 根据username,找到对应的(缓存的)用户记录
outputKey.set(row);
outputValue.set(user);
context.write(outputKey, outputValue);
}
}
// 没有Reducer:执行map端连接,不需要Reducer
// main方法
public static void main(String[] args) throws Exception {
int returnCode = ToolRunner.run(new SemiJoinJob3(), args);
System.exit(returnCode);
}
public int run(String[] args) throws Exception {
if (args.length < 3) {
System.err.println("用法: SemiJoinJob3 <logspath> <outpath> <catchpath>");
System.exit(-1);
}
Path inputPath = new Path(args[0]); // 应是日志表的输入路径
Path outputPath = new Path(args[1]);// 最终连接结果的输出路径
Path cachePath = new Path(args[2]); // 瘦身以后的用户表(job 2的输出)的缓存路径:output/semijoin2/part-m-00000
Job job3 = Job.getInstance(getConf(), "SemiJoinJob3");
// 将part-m-00000文件放入分布式缓存中
// "output/semijoin2/part-m-00000"
job3.addCacheFile(cachePath.toUri());
job3.setJarByClass(getClass());
job3.setMapperClass(JoinMap.class);
job3.setNumReduceTasks(0); // 不需要reduce
job3.setMapOutputKeyClass(Text.class);
job3.setMapOutputValueClass(Text.class);
job3.setOutputKeyClass(Text.class);
job3.setOutputValueClass(Text.class);
job3.setInputFormatClass(TextInputFormat.class);
job3.setOutputFormatClass(TextOutputFormat.class);
// 如果输出目录存在,则先删除
FileSystem fs = FileSystem.get(outputPath.toUri(), getConf());
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
FileInputFormat.setInputPaths(job3, inputPath);
FileOutputFormat.setOutputPath(job3, outputPath);
boolean flag = job3.waitForCompletion(true);
return flag? 0 : 1;
}
}
二、配置log4j
在src/main/resources目录下新增log4j的配置文件log4j.properties,内容如下:
log4j.rootLogger = info,stdout
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
三、项目打包
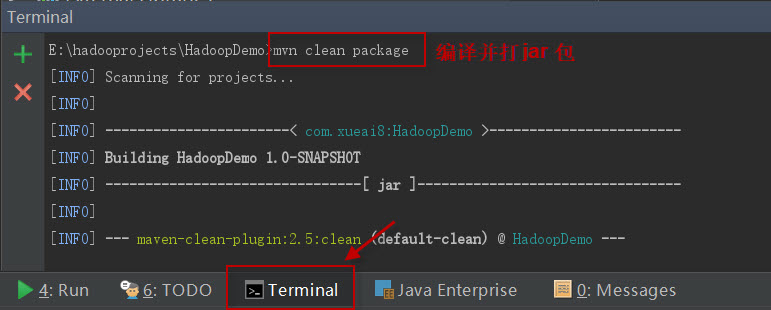
打开IDEA下方的终端窗口terminal,执行"mvn clean package"打包命令,如下图所示:
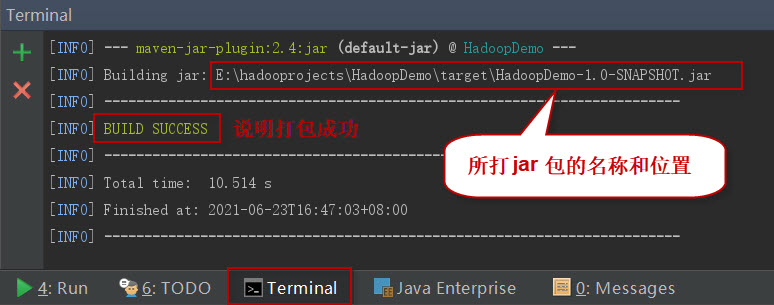
如果一切正常,会提示打jar包成功。如下图所示:
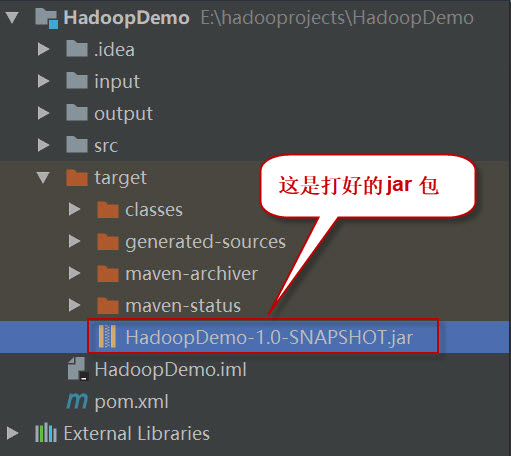
这时查看项目结构,会看到多了一个target目录,打好的jar包就位于此目录下。如下图所示:
四、项目部署
请按以下步骤执行。
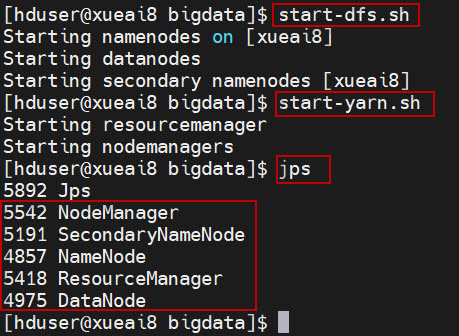
1、启动HDFS集群和YARN集群。在Linux终端窗口中,执行如下的脚本:
$ start-dfs.sh $ start-yarn.sh
查看进程是否启动,集群运行是否正常。在Linux终端窗口中,执行如下的命令:
$ jps
这时应该能看到有如下5个进程正在运行,说明集群运行正常:
5542 NodeManager
5191 SecondaryNameNode
4857 NameNode
5418 ResourceManager
4975 DataNode
2、分别将日志数据文件logs.txt和用户数据文件users.txt上传到HDFS的/input/semijoin/目录下。
$ hdfs dfs -mkdir -p /input/semijoin $ hdfs dfs -put logs.txt /input/semijoin/ $ hdfs dfs -put users.txt /input/semijoin/ $ hdfs dfs -ls /input/semijoin/
3、提交第一个作业到Hadoop集群上运行。(如果jar包在Windows下,请先拷贝到Linux中。)
在终端窗口中,执行如下的作业提交命令:
$ hadoop jar com.xueai8-1.0-SNAPSHOT.jar com.xueai8.semijoin.SemiJoinJob1 /input/semijoin /output/semijoin1
然后查看输出结果。在终端窗口中,执行如下的HDFS命令:
$ hdfs dfs -ls /output/semijoin1/part-r-00000
可以看到如下的输出结果(有日志记录的唯一用户名):
bob jim marie mike
4、接下来提交第二个作业到Hadoop集群上运行。(如果jar包在Windows下,请先拷贝到Linux中。)
在终端窗口中,执行如下的作业提交命令:
$ hadoop jar com.xueai8-1.0-SNAPSHOT.jar com.xueai8.semijoin.SemiJoinJob2 /input/semijoin/users.txt /output/semijoin2/ /output/semijoin1/part-r-00000
然后查看输出结果。在终端窗口中,执行如下的HDFS命令:
$ hdfs dfs -ls /output/semijoin2/part-m-00000
可以看到如下的输出结果(有日志记录的唯一用户名):
mike 69 VA marie 27 OR jim 21 OR bob 71 CA
5、最后提交第三个作业到Hadoop集群上运行。(如果jar包在Windows下,请先拷贝到Linux中。)
在终端窗口中,执行如下的作业提交命令:
$ hadoop jar com.xueai8-1.0-SNAPSHOT.jar com.xueai8.semijoin.SemiJoinJob3 /input/semijoin/logs.txt /output/semijoin3/ /output/semijoin2/part-m-00000
然后查看输出结果。在终端窗口中,执行如下的HDFS命令:
$ hdfs dfs -ls /output/semijoin3/part-m-00000
可以看到如下的输出结果(有日志记录的唯一用户名):
jim logout 93.24.237.12 jim 21 OR mike new_tweet 87.124.79.252 mike 69 VA bob new_tweet 58.133.120.100 bob 71 CA mike logout 55.237.104.36 mike 69 VA jim new_tweet 93.24.237.12 jim 21 OR marie view_user 122.158.130.90 marie 27 OR jim login 198.184.237.49 jim 21 OR marie login 58.133.120.100 marie 27 OR
