Hadoop概述与环境搭建
Hadoop概述
Hadoop是一个用于大规模数据处理的开源框架。
现在,Hadoop已经被业界公认为是用于大数据的通用存储和分析平台。 许多大型企业软件供应商,开始对Hadoop提供商业支持,包括EMC、IBM、Microsoft、Oracle、华为、阿里、小米等。

Hadoop的发展和应用,需要感谢:
- Google,2003-2004年,发表了两个学术论文来描述Google的技术:Google File System(GFS)和MapReduce。其中GFS描述了分布式文件 系统的原理,MapReduce提出了大数据并行处理的模型。Hadoop正是基于这两篇论文开发的。
- Doug Cutting,Java工程师,正是他根据Google的两篇论文开发了Hadoop平台,提供MapReduce和GFS技术的实现,并贡献给了开源社区。
- Yahoo,在2006年雇佣了Doug Cutting,并很快成为Hadoop项目的坚定支持者,并向业界展示了Hadoop在企业级大数据存储和计算上的优异性能。
Hadoop的Logo是一头黄色的小象。
Hadoop的Logo源于Doug Cutting的儿子的玩具小象,它叫Hadoop,因此Doug Cutting将自己开发的大数据开源框架也取名为Hadoop。下图是Doug Cutting。

Hadoop发展历程
- 2004年10月,Google发表了MapReduce论文。
- 2005年2月,Mike Cafarella在Nutch中实现了MapReduce的最初版本。
- 2006年1月,Doug Cutting加入雅虎,Yahoo!提供一个专门的团队和资源将Hadoop发展成一个可在网络上运行的系统。
- 2006年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
- 2006年2月,Yahoo!的网格计算团队采用Hadoop。
- 2006年3月,Yahoo!建设了第一个Hadoop集群用于开发。
- 2006年4月,第一个Apache Hadoop发布。
- 2006年4月,在188个节点上(每个节点10GB)运行排序测试集需要47.9个小时。
- 2006年5月,Yahoo!建立了一个300个节点的Hadoop研究集群。
- 2006年5月,在500个节点上运行排序测试集需要42个小时(硬件配置比4月的更好)。
- 2006年11月,Google发表了Bigtable论文,这最终激发了HBase的创建。
- 2006年12月,排序测试集在20个节点上运行1.8个小时,100个节点上运行3.3小时,500个节点上运行5.2小时,900个节点上运行7.8个小时。
- 2007年,百度开始使用Hadoop做离线处理。
- 2007年,中国移动开始在“大云”研究中使用Hadoop技术。
- 2008年,淘宝开始投入研究基于Hadoop的系统——云梯,并将其用于处理电子商务相关数据。
- 2008年1月,Hadoop成为Apache顶级项目。
- 2008年2月,Yahoo!运行了世界上最大的Hadoop应用,宣布其搜索引擎产品部署在一个拥有1万个内核的Hadoop集群上。
- 2008年4月,在900个节点上运行1TB排序测试集仅需209秒,成为世界最快。
- 2008年6月,Hadoop的第一个SQL框架——Hive成为了Hadoop的子项目。
- 2008年7月,Hadoop打破1TB数据排序基准测试记录。Yahoo!的一个Hadoop集群用209秒完成1TB数据的排序 ,比上一年的纪录保持者保持的297秒快了将近90秒。
- 2009年4月,赢得每分钟排序,59秒内排序500GB(在1400个节点上)和173分钟内排序100TB数据(在3400个节点上)。
- 2009年5月,Yahoo的团队使用Hadoop对1 TB的数据进行排序只花了62秒时间。
- 2012年3月,企业必须的重要功能HDFS NameNode HA被加入Hadoop主版本。
- 2012年8月,另外一个重要的企业适用功能YARN成为Hadoop子项目。
- 2014年2月,Spark逐渐代替MapReduce成为Hadoop的缺省执行引擎,并成为Apache基金会顶级项目。
Hadoop组成架构
目前,Hadoop共演进了三个版本:
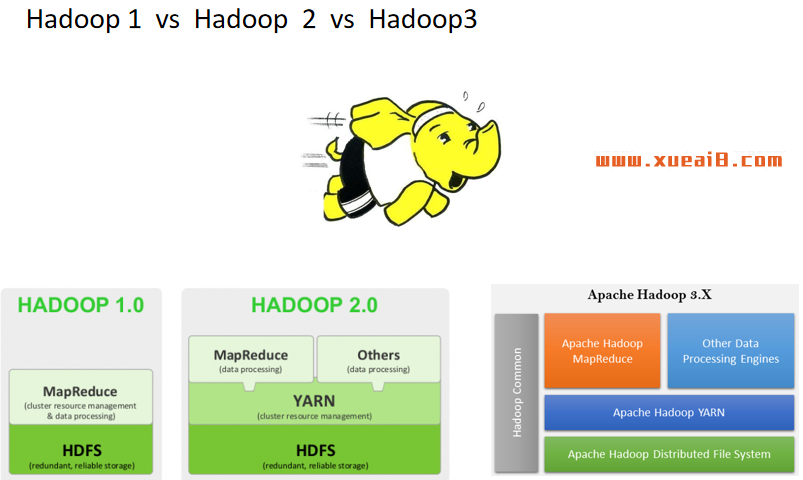
Hadoop v2是企业当前主要应用的版本。我们的课程基于Hadoop-2.7.3,这是兼容性最好、最稳定的版本之一。
Hadoop v2包含如下四个模块:
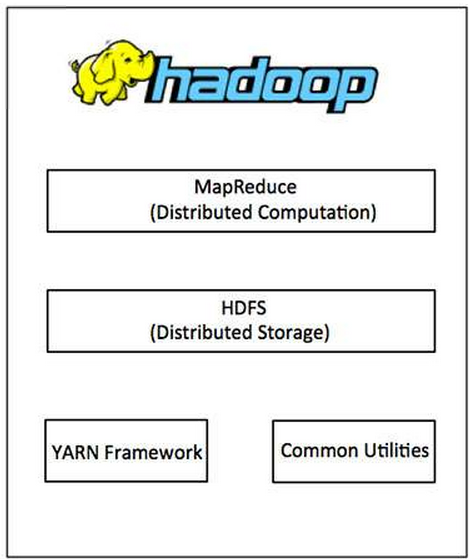
其中:
- Hadoop Common:这是 其它Hadoop模块所依赖的Java库和工具。这些库提供了文件系统和OS级的抽象,并包含用来启动Hadoop所需的Java文件和脚本。
- Hadoop Yarn:用于作业调度和集群资源管理的框架。
- HDFS:Hadoop分布式文件系统,提供对应用程序数据高吞吐量的访问。
- Hadoop MapReduce:这是基于YARN的并行计算框架,用于大数据集的并行处理。
Hadoop生态体系
从2012年开始,术语Hadoop不仅指的是Hadoop自身的四个模块,还包含安装在/和Hadoop之上的其它包,如Hive, HBase, Spark等。
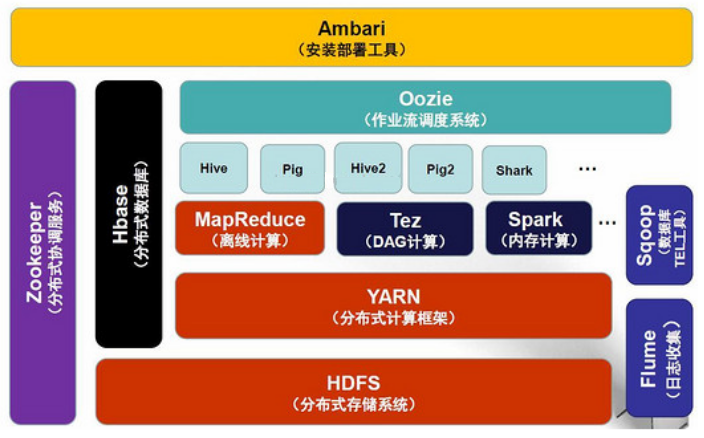
Hadoop官网
Hadoop官网地址:Hadoop官网
Hadoop API文档:Hadoop API
Hadoop安装包下载:下载Hadoop
