使用数据源_1
PySpark结构化流提供了如下这些常用的内置数据源。
- Socket数据源
- Rate数据源
- File数据源
- Kafka数据源
接下来,我们将详细地介绍这些流数据源,并将提供使用它们的示例代码。
使用Socket数据源
套接字数据源很容易使用,只需要提供主机和端口号,但仅限于学习和测试使用,不在生产环境中使用。下面这个示例应用socket数据源。
1)在启动套接字数据源的流式查询之前,首先使用一个网络命令行实用工具,如Mac上的nc或Windows上的netcat,启动一个套接字服务器。打开一个终端窗口,执行下面的命令,启动带有端口号9999的套接字服务器,命令如下:
$ nc -lk 9999
2)另外打开第二个终端,启动pyspark shell:
$ pyspark --master spark://localhost:7077
3)在pyspark Shell中,执行以下结构化流处理代码,代码如下:
# 从Socket数据源读取流数据
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
# 设置shuffle后的分区数为10(测试环境下)
spark.conf.set("spark.sql.shuffle.partitions",10)
# 从Socket数据源读取流数据
lines = spark.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", "9999") \
.load()
# 将行拆分为单词
words = lines.select(
explode(split(lines.value, " ")).alias("word")
)
# 生成运行时单词计数
wordCounts = words.groupBy("word").count()
query = wordCounts.writeStream \
.format("console") \
.outputMode("complete") \
.start()
# 等待流程序执行结束(作为作业文件提交时启用)
# query.awaitTermination()
4)回到第一个终端窗口,任意输入一些单词,以空格分隔,并回车。多输入一些行,然后在第二个终端窗口观察流计算输出。

在第二个终端窗口观察到的输出结果:
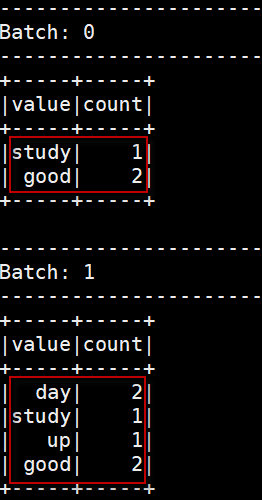
5)当完成测试Socket数据源时,可以通过调用stop()函数来停止流查询。在停止流查询之后,在第一个终端中输入任何东西都不会导致在pypark shell中显示任何东西。停止流查询的代码如下:
query.stop()
使用Rate数据源
与Socket数据源类似,Rate数据源是为测试和学习目的而设计的。它支持以下这些选项:
- rowsPerSecond:每秒应该生成多少行,例如,指定为100。默认是1。如果这个数字很高,那么就可以提供下一个可选配置rampUpTime。
- rampUpTime:在生成速度变为rowsPerSecond之前需要多长时间用来提升,例如,5s。默认是0s。使用比秒更细的粒度将被截断为整数秒。
- numPartitions:生成行的分区数。默认是Spark默认并行度。
Rate源将尽力达到rowsPerSecond,但是查询可能受到资源限制,可以调整numPartitions以帮助达到所需的速度。
Rate源产生的每一段数据只包含两列:时间戳和自动增加的值。下面的示例包含打印Rate数据源数据的代码。请启动pyspark Shell,执行以下代码:
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
# 设置shuffle后的分区数为10(测试环境下)
spark.conf.set("spark.sql.shuffle.partitions",10)
# 从Socket数据源读取流数据
lines = spark.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", "9999") \
.load()
# 从Rate数据源读取流数据,配置它每秒产生10行
rateSourceDF = spark.readStream \
.format("rate") \
.option("rowsPerSecond","10") \
.load()
# 以update模式将结果写出到控制台,并启动流计算
query = rateSourceDF.writeStream \
.outputMode("update") \
.format("console") \
.option("truncate", "false") \
.start()
# 等待流程序执行结束(作为作业文件提交时启用)
# query.awaitTermination()
观察到每秒输出10条数据。其中部分批次数据如下所示:
------------------------------------------- Batch: 1 ------------------------------------------- +-----------------------+-----+ |timestamp |value| +-----------------------+-----+ |2021-02-02 17:32:01.264|0 | |2021-02-02 17:32:01.664|4 | |2021-02-02 17:32:02.064|8 | |2021-02-02 17:32:01.364|1 | |2021-02-02 17:32:01.764|5 | |2021-02-02 17:32:02.164|9 | |2021-02-02 17:32:01.464|2 | |2021-02-02 17:32:01.864|6 | |2021-02-02 17:32:01.564|3 | |2021-02-02 17:32:01.964|7 | +-----------------------+-----+
值得注意的一件事是,value列中的数字保证在所有分区中都是连续的。例如,要查看三个分区的输出结果,代码如下:
from pyspark.sql.functions import *
# 从Rate数据源读取流数据,配置它每秒产生10行,分三个分区
rateSourceDF = spark.readStream \
.format("rate") \
.option("rowsPerSecond","10") \
.option("numPartitions",3) \
.load()
# 添加分区id列来检查
rateWithPartitionDF = rateSourceDF \
.withColumn("partition_id", spark_partition_id())
# 以update模式将结果写出到控制台,并启动流计算
query = rateWithPartitionDF.writeStream \
.outputMode("update") \
.format("console") \
.option("truncate", "false") \
.start()
# 等待流程序执行结束(作为作业文件提交时启用)
# query.awaitTermination()
执行以上代码,观察到输出结果如下所示:
------------------------------------------- Batch: 1 ------------------------------------------- +-----------------------+-----+------------+ |timestamp |value|partition_id| +-----------------------+-----+------------+ |2021-02-02 17:35:43.461|0 |0 | |2021-02-02 17:35:43.761|3 |0 | |2021-02-02 17:35:44.061|6 |0 | |2021-02-02 17:35:44.361|9 |0 | |2021-02-02 17:35:43.561|1 |1 | |2021-02-02 17:35:43.861|4 |1 | |2021-02-02 17:35:44.161|7 |1 | |2021-02-02 17:35:43.661|2 |2 | |2021-02-02 17:35:43.961|5 |2 | |2021-02-02 17:35:44.261|8 |2 | +-----------------------+-----+------------+
前面的输出显示了这10行分布在三个分区上,并且这些值是连续的,就好像它们是为单个分区生成的一样。
使用File数据源
文件数据源是最容易理解和使用的。PySpark Structured Streaming开箱即用地支持所有常用的文件格式,包括文本、CSV、JSON、ORC和Parquet。要获得支持的文件格式的完整列表,请参考DataStreamReader接口。
File数据源支持以下选项配置:
- path:输入目录的路径,对所有文件格式都通用。
- maxFilesPerTrigger:每个触发器中考虑处理的最大新文件数(默认:no max) 。
- latestFirst:是否先处理最新的文件,当有大量文件积压时很有用(默认:false)。
- fileNameOnly:是否仅根据文件名而不是根据完整路径检查新文件(默认:false)。 将此值设置为“true”后,以下文件将被认为是相同的文件,因为它们的文件名都是一样的,均为"dataset.txt”:
- "file:///dataset.txt"
- "s3://a/dataset.txt"
- "s3n://a/b/dataset.txt"
- "s3a://a/b/c/dataset.txt"
下面是使用File数据源的流程序模板代码:
# 使用File数据源,读取json文件
mobileSSDF = spark.readStream \
.schema(mobileDataSchema) \
.json("")
# 如果指定maxFilesPerTrigger为1,表示一个文件一个文件地处理
mobileSSDF = spark.readStream \
.schema(mobileDataSchema) \
.option("maxFilesPerTrigger",1) \
.json("")
# 如果指定latestFirst为true,则表示首先处理新产生的文件
mobileSSDF = spark.readStream \
.schema(mobileDataSchema) \
.option("latestFirst", "true") \
.json("<directory name>")
下面我们通过一个示例程序来演示如何使用结构化流读取文件数据源。
【示例】移动电话的开关机等事件会保存在json格式的文件中。现在编写Spark结构化流处理程序来读取这些事件并处理。请按以下步骤操作。
1)准备数据
在本示例中,我们使用文件数据源,该数据源以json文件的格式记录了一小组移动电话动作事件。每个事件由三个字段组成:
- id:表示手机的唯一ID。在样例数据集中,电话ID将类似于phone1、phone2、phone3等。
- action:表示用户所采取的操作。该操作的可能值是open或close。
- ts:表示用户action发生时的时间戳。这是事件时间(event time)。
我们准备了三个存储移动电话事件数据的JSON文件:file1.json,file2.json,file3.json。这三个JSON文件位于PBLP平台的~/data/spark/mobile目录下。
为了模拟数据流的行为,我们将把这三个JSON文件复制到项目的“src/main/data/mobile”目录下。
2)先导入相关的依赖包。
from pyspark.sql.types import * from pyspark.sql.functions import *
3)为手机事件数据创建模式(schema)
默认情况下,结构化流在从基于文件的数据源读取数据时需要一个模式(因为最初目录可能是空的,因此结构化的流无法推断模式)。但是,可以设置配置参数spark.sql.streaming.schemaInference的值为true来启用模式推断。在这个例子中,我们将显式地创建一个模式,代码如下所示:
# 为手机事件数据创建一个schema
fields = [
StructField("id", StringType(), nullable = False),
StructField("action", StringType(), nullable = False),
StructField("ts", TimestampType(), nullable = False)
]
mobileDataSchema = StructType(fields)
3)读取流文件数据源,创建DataFrame,并将action列值转换为大写。
# 指定监听的文件目录
dataPath = "/data/spark/stream/mobile"
# 读取指定目录下的源数据文件,一次一个
mobileDF = spark.readStream \
.option("maxFilesPerTrigger", 1) \
.option("mode","failFast") \
.schema(mobileDataSchema) \
.json(dataPath)
# mobileDF.printSchema()
# 将所有"action"列值转换为大写
upperDF = mobileDF.select("id",upper("action").alias("action"),"ts")
4)将结果DataFrame输出到控制台显示,代码如下:
# 结果输出到控制台
query = upperDF.writeStream \
.format("console") \
.option("truncate","false") \
.outputMode("append") \
.start()
# 等待流程序执行结束(作为作业文件提交时启用)
# query.awaitTermination()
5)执行流处理程序,输出结果如下所示。
------------------------------------------- Batch: 0 ------------------------------------------- +------+-------------+-------------------+ |id |upper(action)|ts | +------+-------------+-------------------+ |phone1|OPEN |2018-03-02 10:02:33| |phone2|OPEN |2018-03-02 10:03:35| |phone3|OPEN |2018-03-02 10:03:50| |phone1|CLOSE |2018-03-02 10:04:35| +------+-------------+-------------------+ ------------------------------------------- Batch: 1 ------------------------------------------- +------+-------------+-------------------+ |id |upper(action)|ts | +------+-------------+-------------------+ |phone3|CLOSE |2018-03-02 10:07:35| |phone4|OPEN |2018-03-02 10:07:50| +------+-------------+-------------------+ ------------------------------------------- Batch: 2 ------------------------------------------- +------+-------------+-------------------+ |id |upper(action)|ts | +------+-------------+-------------------+ |phone2|CLOSE |2018-03-02 10:04:50| |phone5|OPEN |2018-03-02 10:10:50| +------+-------------+-------------------+
完整的代码如下所示。
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import *
# 创建SparkSession实例
spark = SparkSession \
.builder \
.appName("file source") \
.getOrCreate()
# 为手机事件数据创建一个schema
fields = [
StructField("id", StringType(), nullable = False),
StructField("action", StringType(), nullable = False),
StructField("ts", TimestampType(), nullable = False)
]
mobileDataSchema = StructType(fields)
# 指定监听的文件目录
dataPath = "/data/spark/stream/mobile"
# 读取指定目录下的源数据文件,一次一个
mobileDF = spark.readStream \
.option("maxFilesPerTrigger", 1) \
.option("mode","failFast") \
.schema(mobileDataSchema) \
.json(dataPath)
# mobileDF.printSchema()
# 将所有"action"列值转换为大写
upperDF = mobileDF.select("id",upper("action").alias("action"),"ts")
# 结果输出到控制台
query = upperDF.writeStream \
.format("console") \
.option("truncate","false") \
.outputMode("append") \
.start()
# 等待流程序执行结束
query.awaitTermination()
