关于aggregateByKey
Apache Spark aggregateByKey函数聚合每个key的值,使用给定的combine函数和一个中性的“零值”,并为该key返回不同类型的值。
这个aggregateByKey函数总共接受3个参数:
- zeroValue:它是累加值或累加器的初值。如果聚合类型是对所有的值求和,那么它可以是0。如果聚合目标是找出最小值,这个值可以是Double.MaxValue。如果聚合目标是找出最大值,这个值可以使用Double.MinValue。或者,如果我们只是想要一个各自的集合作为每个key的输出的话,也可以使用一个空的List或Map对象。
- seqOp:是聚合单个分区的所有值的操作。它将一种类型[V]的数据转换/合并为另一种类型[U]的序列操作函数。
- combOp:类似于seqOp,进一步聚合来自不同分区的所有聚合值。它将多个转换后的类型[U]合并为一个单一类型[U]的组合操作函数。
例如,我们有这样的RDD:PairRDD[String, (String, Double)]。其中,key是学生姓名,数据类型为String,值是课程名称和成绩,数据类型为(String,Double)。现在我们要找出每个学生的最好成绩,过程如下:
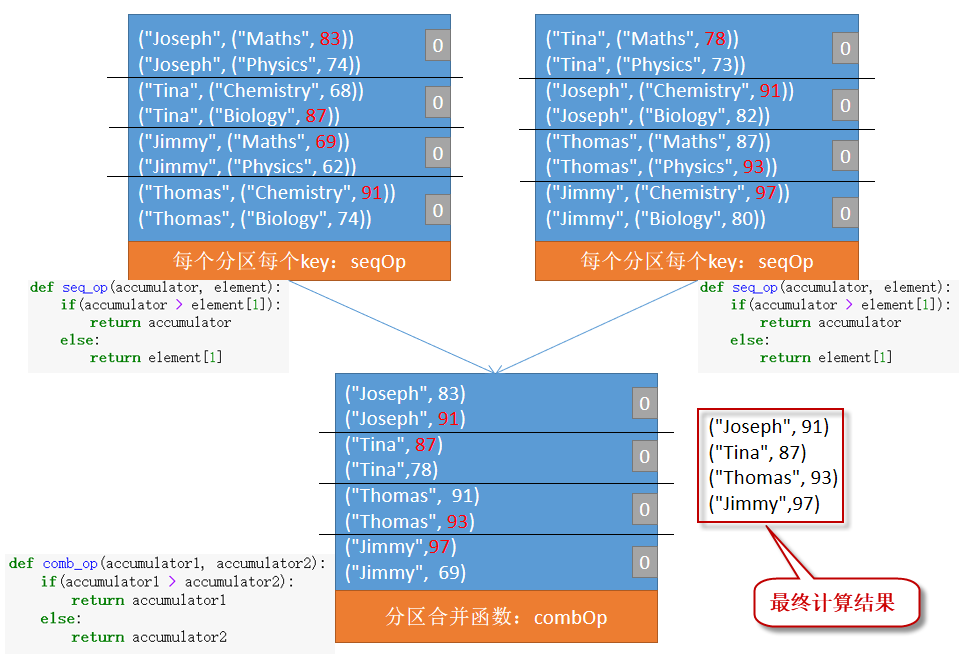
【示例】给出每个学生每门功课的分数,请使用aggregateByKey函数计算每个学生的最好成绩。
# 使用key-value对创建PairRDD studentRDD
student_rdd = spark.sparkContext.parallelize([
("Joseph", "Maths", 83), ("Joseph", "Physics", 74), ("Joseph", "Chemistry", 91),
("Joseph", "Biology", 82), ("Jimmy", "Maths", 69), ("Jimmy", "Physics", 62),
("Jimmy", "Chemistry", 97), ("Jimmy", "Biology", 80), ("Tina", "Maths", 78),
("Tina", "Physics", 73), ("Tina", "Chemistry", 68), ("Tina", "Biology", 87),
("Thomas", "Maths", 87), ("Thomas", "Physics", 93), ("Thomas", "Chemistry", 91),
("Thomas", "Biology", 74), ("Cory", "Maths", 56), ("Cory", "Physics", 65),
("Cory", "Chemistry", 71), ("Cory", "Biology", 68), ("Jackeline", "Maths", 86),
("Jackeline", "Physics", 62), ("Jackeline", "Chemistry", 75), ("Jackeline", "Biology", 83),
("Juan", "Maths", 63), ("Juan", "Physics", 69), ("Juan", "Chemistry", 64),
("Juan", "Biology", 60)], 2)
# 定义Seqencial Operation and Combiner Operations
# Sequence operation : 从单个分区查找最大成绩
def seq_op(accumulator, element):
if(accumulator > element[1]):
return accumulator
else:
return element[1]
# Combiner Operation : 从所有分区累加器中找出最大成绩
def comb_op(accumulator1, accumulator2):
if(accumulator1 > accumulator2):
return accumulator1
else:
return accumulator2
# 在我们的情况下,零值将是零,因为我们正在寻找最大的成绩
zero_val = 0
aggr_rdd = student_rdd.map(lambda t: (t[0], (t[1], t[2]))).aggregateByKey(zero_val, seq_op, comb_op)
# 查看输出
for tpl in aggr_rdd.collect():
print(tpl)
执行以上代码,输出结果如下:
('Jimmy', 97)
('Tina', 87)
('Thomas', 93)
('Joseph', 91)
('Cory', 71)
('Jackeline', 86)
('Juan', 69)
【示例】在上例的基础上,请修改代码,要求要同时输出每个学生最高成绩及该成绩所属的课程。
# 定义Seqencial Operation 和Combiner Operations
def seq_op(accumulator, element):
if(accumulator[1] > element[1]):
return accumulator
else:
return element
# Combiner Operation : 从所有分区累加器中找出最大成绩
def comb_op(accumulator1, accumulator2):
if(accumulator1[1] > accumulator2[1]):
return accumulator1
else:
return accumulator2
# 在我们的情况下,零值将是零,因为我们正在寻找最大的成绩
zero_val = ('', 0)
aggr_rdd = student_rdd.map(lambda t: (t[0], (t[1], t[2]))).aggregateByKey(zero_val, seq_op, comb_op)
# 查看输出
for tpl in aggr_rdd.collect():
print(tpl)
执行以上代码,输出结果如下:
('Jimmy', 77.0)
('Tina', 76.5)
('Thomas', 86.25)
('Joseph', 82.5)
('Cory', 65.0)
('Jackeline', 76.5)
('Juan', 64.0)
aggregateByKey函数的特点总结如下:
- 性能方面的aggregateByKey是一个优化的transformation操作;
- aggregateByKey是一个宽依赖的转换;
- 当聚合需求加上输入和输出RDD类型不同时,我们应该使用aggregateByKey;
- 当聚合需求加上输入和输出RDD类型相同时,我们应该使用reduceByKey。
