关于reduceByKey
Pair RDD的 reduceByKey函数使用reduce函数合并每个key的值,它是一个transformation操作,这意味着它是延迟计算的。我们需要传递一个相关函数作为参数,该函数将被应用到源Pair RDD上,并创建一个新的Pair RDD。这个操作是一个宽依赖的操作,因为有可能发生跨分区数据shuffling。
假设,现在有这么一组数据:
data = [("a", 1), ("b", 1), ("a", 1), ("a", 1), ("b", 1),
("b", 1), ("a", 1), ("b", 1), ("a", 1), ("b", 1)]
将其构造为具有3个分区的一个RDD:
x = spark.sparkContext.parallelize(data, 3)
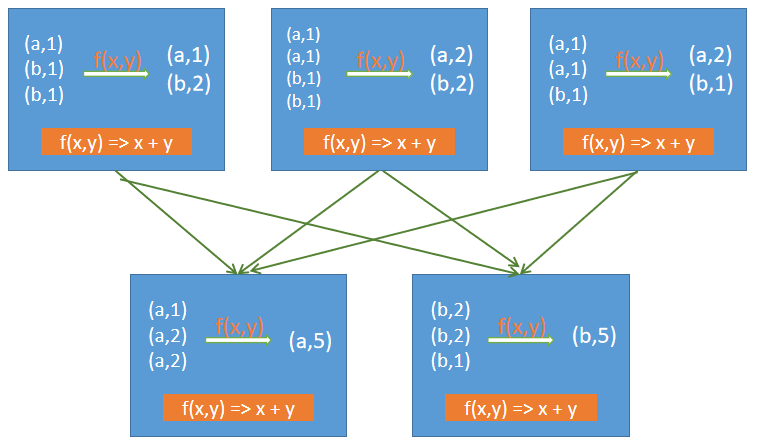
当reduceByKey函数重复地应用于具有多个分区的同一组RDD数据时,它首先使用reduce函数在本地执行合并,然后跨分区发送记录以准备最终结果。也就是说,在跨分区发送数据之前,它还使用相同的reduce函数在本地合并数据,以优化数据转换。如下图所示:
这个reduceByKey函数有三个变体:
- reduceByKey(function):将使用现有的分区器生成散列分区输出。
- reduceByKey(function, [numPartition]):将使用现有的分区器生成散列分区输出。
- reduceByKey(partitioner, function):使用指定的Partitioner对象生成输出。
【示例】使用reduceByKey函数对Pair RDD进行分组求和。
# 假设,现在有这么一组数据:
data = [("a", 1), ("b", 1), ("a", 1), ("a", 1), ("b", 1),
("b", 1), ("a", 1), ("b", 1), ("a", 1), ("b", 1)]
# 创建PairRDD x
x = spark.sparkContext.parallelize(data, 3)
# 在x上应用reduceByKey操作
y = x.reduceByKey(lambda accum, n: accum + n)
print(y.collect()) # [('b', 5), ('a', 3)]
# 单独定义关联函数
def sumFunc(accum, n):
return accum + n
y = x.reduceByKey(sumFunc)
print(y.collect()) # [('b', 5), ('a', 3)]
执行以上代码,输出结果如下:
[('b', 5), ('a', 5)]
[('b', 5), ('a', 5)]
注意:由于数据集可以有非常多的键(key),所以reduceByKey()不是作为一个返回值给用户程序的action实现的。相反,它返回一个新的RDD,由每个键(key)和该键的reduce值组成。
