构造DataFrame-从RDD创建
在PySpark中有两种方法可以将RDD转换为DataFrame:toDF()和createDataFrame(rdd, schema)。
方法一:使用toDF()
下面的示例中,调用RDD的toDF()函数,将RDD转换到DataFrame,并使用指定的列名。列的类型是从RDD中的数据推断出来的。
# list
persons = [("张三",23),("李四",18),("王老五",35)]
# RDD
personRDD = spark.sparkContext.parallelize(persons)
# from RDD to DataFrame
personsDF = personRDD.toDF(["name", "age"])
# 查看模式和数据
personsDF.printSchema()
personsDF.show()
print(personsDF.dtypes) # 注意其中的隐式类型推断
执行过程和结果如下:

我们在这里创建了一个RDD,它包含元组元素,然后调用它的toDF()方法。请注意,toDF采用的是元组列表,而不是标量元素。每个元组类似于一行。我们可以选择列名,否则,Spark会自行创建一些模糊的名称,比如_1、_2。列的类型推断是隐式的。例如:
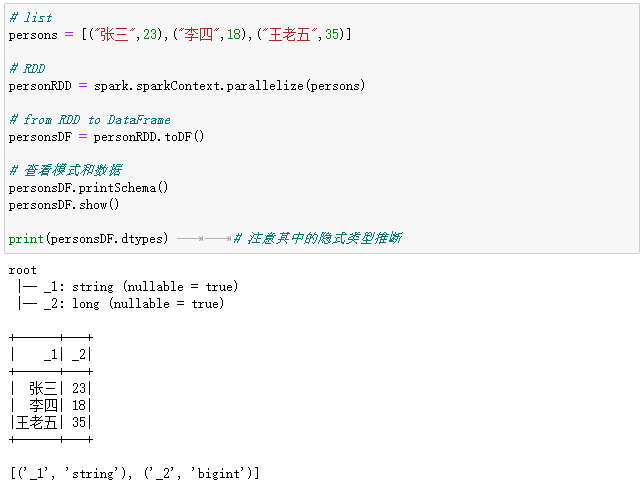
# list
persons = [("张三",23),("李四",18),("王老五",35)]
# RDD
personRDD = spark.sparkContext.parallelize(persons)
# from RDD to DataFrame
personsDF = personRDD.toDF()
# 查看模式和数据
personsDF.printSchema()
personsDF.show()
print(personsDF.dtypes) # 注意其中的隐式类型推断
执行过程和结果如下:
也可以使用反射来推断包含特定对象类型的RDD的模式。PySpark SQL可以将包含Row对象的RDD转换为DataFrame,从而推断数据类型。Row是通过将一组key/value对作为kwargs传递给Row类来构造的。这个列表的key定义表的列名,类型通过对整个数据集进行采样来推断,类似于对JSON文件执行的推断。例如:
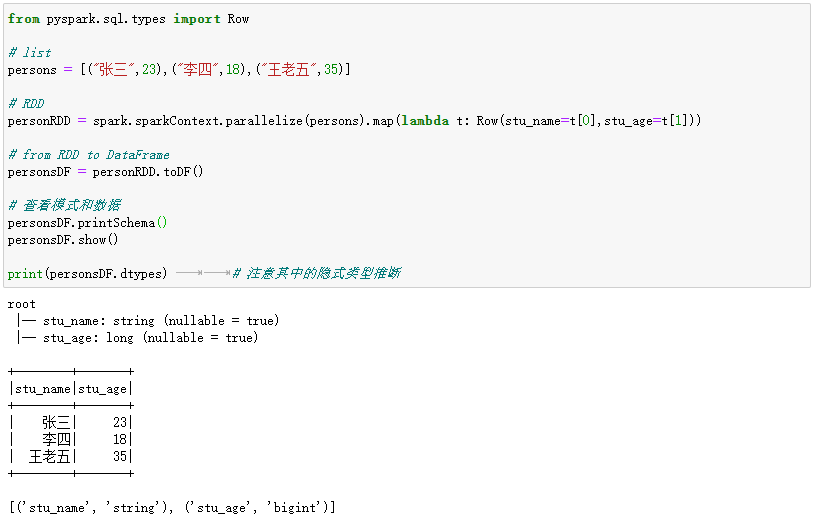
from pyspark.sql.types import Row
# list
persons = [("张三",23),("李四",18),("王老五",35)]
# RDD[Row]
personRDD = spark.sparkContext.parallelize(persons).map(lambda t: Row(stu_name=t[0],stu_age=t[1]))
# from RDD to DataFrame
personsDF = personRDD.toDF()
# 查看模式和数据
personsDF.printSchema()
personsDF.show()
print(personsDF.dtypes) # 注意其中的隐式类型推断
执行过程和结果如下:
这种基于反射的方法使代码更简洁,当在编写PySpark应用程序时已经了解模式时,这种方法可以很好地工作。
方法二:使用createDataFrame(rdd, schema)
第二种方法是通过一个编程接口,先构造出一个模式(schema),然后将其应用到现有的RDD中创建一个DataFrame。这需要使用SparkSession的方法createDataFrame来创建。虽然这种方法比较冗长,但是在事先不知道列类型的情况下,可以通过这种方法自行构造DataFrame。
可以通过以下三个步骤以编程方式创建DataFrame。
- 从原始的RDD创建一个元组或列表的RDD;
- 创建由StructType表示的模式,该模式与在步骤1中创建的RDD中的元组或列表结构相匹配。
- 通过SparkSession提供的createDataFrame方法将模式应用到RDD。
请看下面的示例:
// 定义一个case class
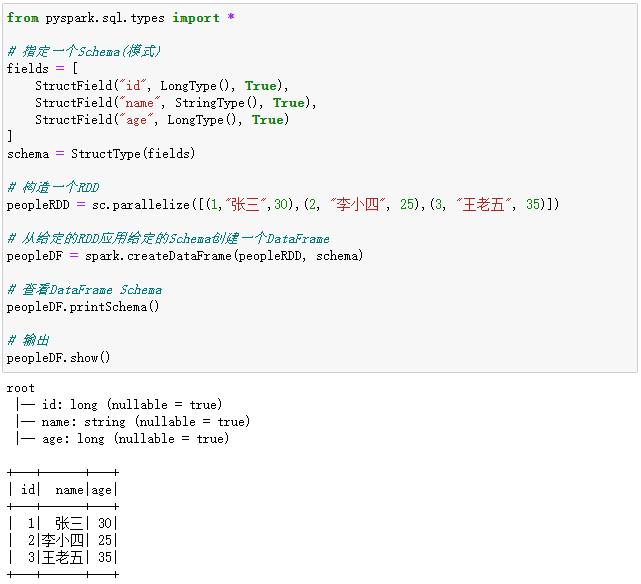
from pyspark.sql.types import *
# 指定一个Schema(模式)
fields = [
StructField("id", LongType(), True),
StructField("name", StringType(), True),
StructField("age", LongType(), True)
]
schema = StructType(fields)
# 构造一个RDD
peopleRDD = sc.parallelize([(1,"张三",30),(2, "李小四", 25),(3, "王老五", 35)])
# 从给定的RDD应用给定的Schema创建一个DataFrame
peopleDF = spark.createDataFrame(peopleRDD, schema)
# 查看DataFrame Schema
peopleDF.printSchema()
# 输出
peopleDF.show()
执行过程和结果如下:
将Pandas转换为PySpark DataFrame
对于大数据集,Python Pandas DataFrame无法执行复杂的转换操作,因此,我们需要将Pandas韩国的为PySpark的DataFrame,在Spark集群上应用复杂的转换,然后再将结果转换回Pandas DataFrame。
在下面这个示例中,我们首先创建了Pandas DataFrame,它包含一些测试数据。
import pandas as pd # 测试数据 data = [['张三', 50], ['李四', 45], ['王老五', 54],['赵小六',34]] # 创建pandas DataFrame pandasDF = pd.DataFrame(data, columns = ['Name', 'Age']) # 输出 print(pandasDF)
执行过程和结果如下:

PySpark提供了一个createDataFrame(pandas_dataframe)方法,用来将Pandas DataFrame转换为一个PySpark DataFrame,在默认情况下,PySpark会根据Pandas数据类型将模式推断为PySpark数据类型。
from pyspark.sql import SparkSession
# 构建SparkSession和SparkContext实例
spark = SparkSession.builder \
.master("spark://xueai8:7077") \
.appName("pyspark pandas demo") \
.getOrCreate()
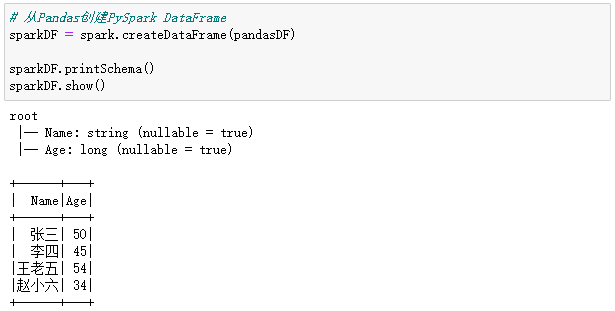
# 从Pandas创建PySpark DataFrame
sparkDF = spark.createDataFrame(pandasDF)
sparkDF.printSchema()
sparkDF.show()
执行过程和结果如下:
如果希望所有数据类型都是字符串,则:
sparkDF2 = spark.createDataFrame(pandasDF.astype(str)) sparkDF2.printSchema() sparkDF2.show()
执行过程和结果如下:
在将Pandas DataFrame转换为PySpark DataFrame时,也可以指定一个schema来修改列名和列数据类型。请看下面的示例。
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
# 使用StructType创建用户自定义模式
mySchema = StructType([
StructField("姓名", StringType(), True),
StructField("年龄", IntegerType(), True)
])
# 创建DataFrame时指定模式
sparkDF2 = spark.createDataFrame(pandasDF, schema=mySchema)
sparkDF2.printSchema()
sparkDF2.show()
执行过程和结果如下:

