构造DataFrame-加载外部数据源创建
Spark提供了一个接口,DataFrameReader,用来从众多的数据源读取数据到DataFrame,以各种格式,如JSON、CSV、Parquet、Text、Avro、ORC等。
在PySpark SQL中用于读写数据源数据的两个主要类分别是pyspark.sql.DataFrameReader和pyspark.sql.DataFrameWriter,它们的实例分别作为SparkSession类的read和write字段。
可通过DataFrameReader的load()方法,用来以各种格式(如JSON、CSV、Parquet、Text、Avro、ORC等)从众多的数据源读取数据到DataFrame。另外它还有五个快捷方法:text、csv、json、orc和parquet,相当于先调用format()方法再调用load()方法。
PySpark SQL提供的接口pyspark.sql.DataFrameWriter,用来将DataFrame以特定格式写回数据源。它的实例作为SparkSession类的write字段。
读取文本文件创建DataFrame
文本文件是最常见的数据存储文件。Spark DataFrame API允许开发者将文本文件的内容转换成DataFrame。
让我们仔细看看下面的例子,以便更好地理解(这里我们使用Spark自带的数据文件):
file = "file:///home/hduser/data/spark/resources/people.txt"
txtDF = spark.read.format("text").load(file) # 加载文本文件
# txtDF = spark.read.text(file) # 等价上一句,快捷方法
txtDF.printSchema() # 打印schema
txtDF.show() # 输出
执行过程和结果如下:

Spark会自动推断出模式,并相应地创建一个单列的DataFrame。因此,没有必要为文本数据定义模式。不过,当加载大数据文件时,定义一个schema要比让Spark来进行推断效率更高。
读取CSV文件创建DataFrame
在Spark 3.x中,加载CSV文件是非常简单的。请看下面的示例。
// 数据源文件 file = "file:///home/hduser/data/spark/resources/people.csv" people_df = spark.read.load(file, format="csv", sep=";", inferSchema="true", header="true") people_df.printSchema() people_df.show()
执行过程和结果如下:

或者,也可以使用快捷方法csv,如下所示:
file = "file:///home/hduser/data/spark/resources/people.csv" people_df = spark.read.options(sep=";",inferSchema="true",header="true").csv(file) people_df.printSchema() people_df.show()
执行过程和结果如下:

在上面的示例中,使用了模式推断。对于大型的数据源,指定一个schema要比让Spark来进行推断效率更高。
在下面的代码中,我们提供一个schema:
from pyspark.sql.types import *
file = "file:///home/hduser/data/spark/resources/people.csv"
# 指定一个Schema(模式)
fields = [
StructField("p_name", StringType(), True),
StructField("p_age", IntegerType(), True),
StructField("p_job", StringType(), True)
]
schema = StructType(fields)
# 加载CSV文件到DataFrame,并指定schema
people_df2 = spark.read.options(sep=";",header="true").schema(schema).csv(file)
people_df2.printSchema()
people_df2.show()
执行过程和结果如下:
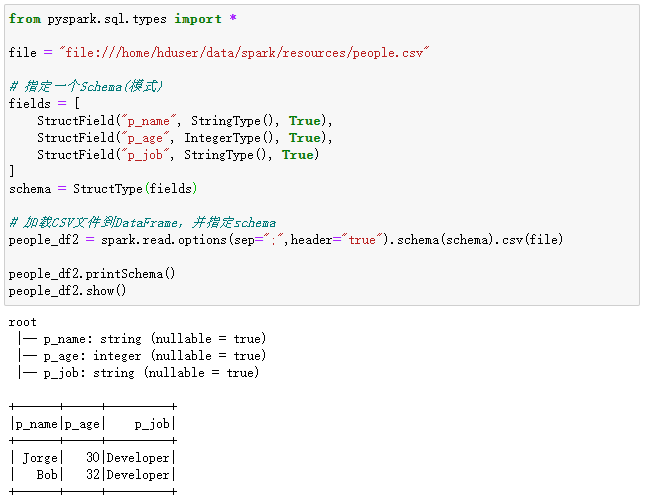
可以看出,它返回了由行和命名列组成的DataFrame,该DataFrame具有模式中指定的类型。
也可以使用csv格式读取tsv文件。所谓tsv文件,指的是以制表符(tab)作为字段分隔符的文件。在下面的示例中,加载tsv文件到DataFrame中:
file = "file:///home/hduser/data/spark/resources/people.tsv" people_df3 = spark.read.options(sep="\t",inferSchema="true",header="true").csv(file) people_df3.printSchema() people_df3.show()
执行过程和结果如下:
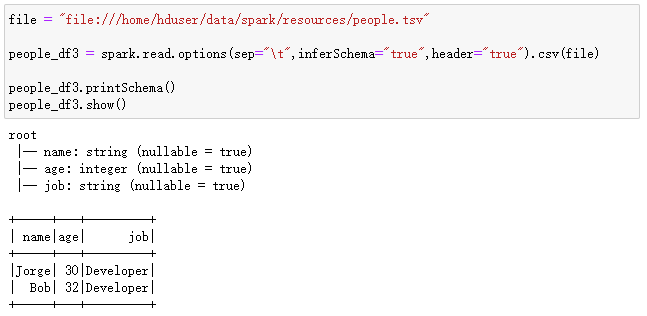
读取JSON文件创建DataFrame
Spark SQL可以自动推断JSON Dataset的模式,并将其加载为Dataset[Row]。这种转换可以在Dataset[String]或JSON文件上使用SparkSession.read.json()完成。
注意,作为json文件提供的文件实际上并不是典型的JSON文件。每一行必须包含一个单独的、自包含的有效JSON对象。对于常规的多行JSON文件,将multiLine选项设置为true。
读取JSON数据源文件时,Spark会自动从key中自动推断模式,并相应地创建一个DataFrame。因此,没有必要为JSON数据定义模式。此外,Spark极大地简化了访问复杂JSON数据结构中的字段所需的查询语法。
请看下面的示例。
// 数据源文件 file = "file:///home/hduser/data/spark/resources/people.json" # json解析;列名和数据类型隐式地推断 people_df4 = spark.read.load(file, format="json") # people_df4 = spark.read.json(file) # 简洁方法 people_df4.printSchema() people_df4.show()
执行过程和结果如下:
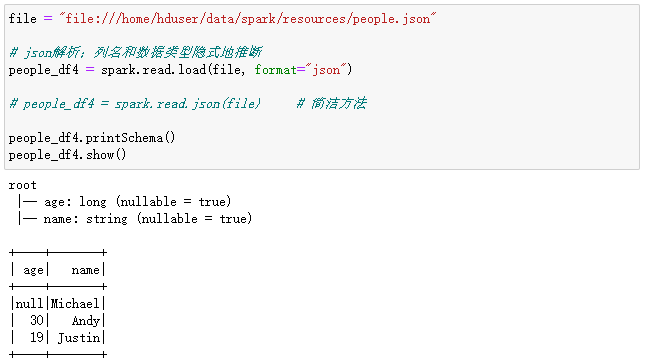
当然,也可以明确指定一个schema,覆盖Spark的推断schema。如下面的代码所示:
from pyspark.sql.types import *
file = "file:///home/hduser/data/spark/resources/people.json"
# 指定一个Schema(模式)
fields = [
StructField("name", StringType(), True),
StructField("age", IntegerType(), True)
]
schema = StructType(fields)
# 读取数据到DataFrame,并指定schema
people_df5 = spark.read.schema(schema).json(file)
people_df5.printSchema()
people_df5.show()
执行过程和结果如下:
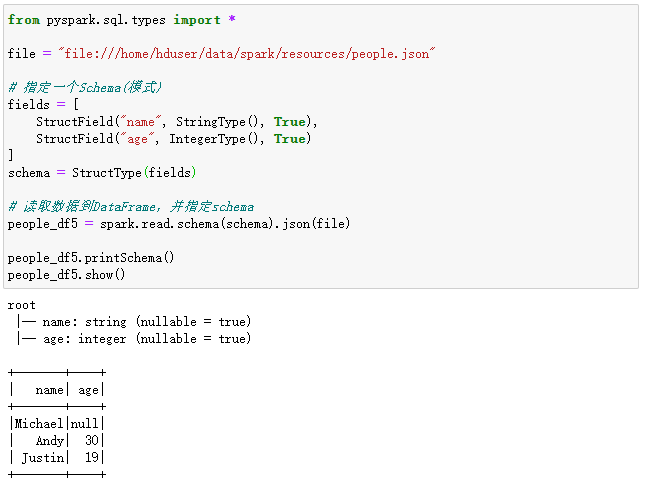
读取Parquet文件创建DataFrame
Apache Parquet文件是Spark SQL中直接支持的一种常见格式,它们非常节省空间,非常流行。Apache Parquet是一种高效的、压缩的、面向列的开源数据存储格式。它提供了多种存储优化,允许读取单独的列而非整个文件,这不仅节省了存储空间而且提升了读取效率。它是 Spark 默认的文件格式,支持非常有效的压缩和编码方案,也可用于Hadoop生态系统中的任何项目,可以大大提高这类应用程序的性能。
在下面的示例中,先读取Parquet文件内容到DataFrame中,然后打印其schema并输出数据:
file = "file:///home/hduser/data/spark/resources/users.parquet" # 读取parquet文件 # Parquet文件是自描述的,因此模式得以保留 # 加载Parquet文件的结果也是一个DataFrame parquet_df = spark.read.load(file,format="parquet") # parquet_df = spark.read.parquet(file) # 简洁写法 # 输出模式和内容 parquet_df.printSchema() parquet_df.show()
执行过程和结果如下:

使用JDBC从数据库创建DataFrame
PySpark SQL还包括一个可以使用JDBC从其他关系型数据库读取数据的数据源。开发人员可以使用JDBC创建来自其他数据库的DataFrame,只要确保预定数据库的JDBC驱动程序是可访问的(需要在spark类路径中包含特定数据库的JDBC驱动程序)。
在下面的示例中,我们通过JDBC读取MySQL数据库中的一个peoples数据表,并创建DataFrame。首先,在MySQL中执行如下脚本,创建一外名为xueai8的数据和一个名为peoples的数据表,并向表中插入一些样本记录。
mysql> create database xueai8; mysql> use xueai8; mysql> create table peoples(id int not null primary key, name varchar(20), age int); mysql> insert into peoples values(1,"张三",23),(2,"李四",18),(3,"王老五",35); mysql> select * from peoples;
然后编写如下的代码,来读取peoples表中的数据到DataFrame中。
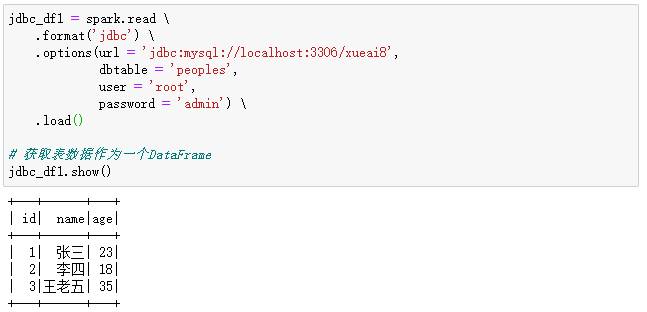
jdbc_df1 = spark.read \
.format('jdbc') \
.options(url = 'jdbc:mysql://localhost:3306/xueai8',
dbtable = 'peoples',
user = 'root',
password = 'admin') \
.load()
# 获取表数据作为一个DataFrame
jdbc_df1.show()
执行过程和结果如下:
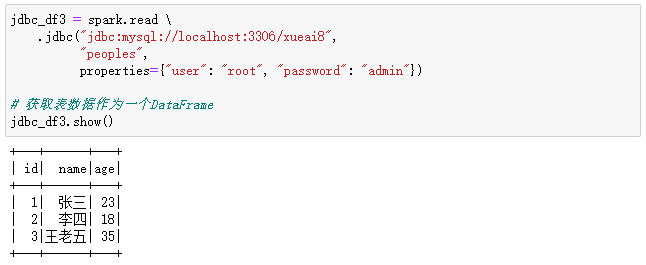
也可以使用快捷方法jdbc(url, table, properties={"user": "username", "password": "password"})从关系型数据库中加载数据。例如,上面的示例可以改写为如下的代码::
jdbc_df3 = spark.read \
.jdbc("jdbc:mysql://localhost:3306/xueai8",
"peoples",
properties={"user": "root", "password": "admin"})
# 获取表数据作为一个DataFrame
jdbc_df3.show()
执行过程和结果如下:
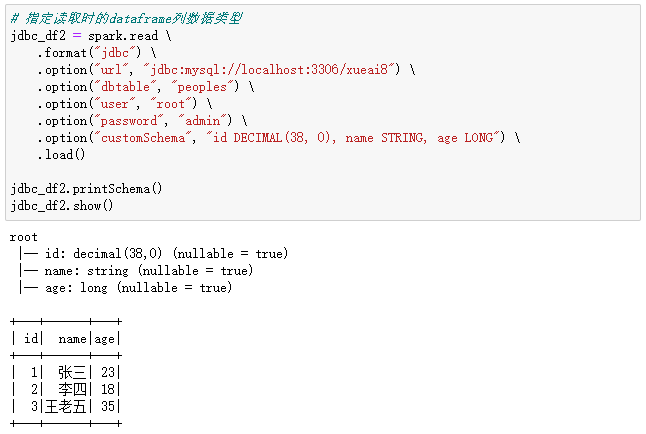
在读取JDBC关系型数据库中的表数据时,也可以指定相应的DataFrame的列数据类型。
# 指定读取时的dataframe列数据类型
jdbc_df2 = spark.read \
.format("jdbc") \
.option("url", "jdbc:mysql://localhost:3306/xueai8") \
.option("dbtable", "peoples") \
.option("user", "root") \
.option("password", "admin") \
.option("customSchema", "id DECIMAL(38, 0), name STRING, age LONG") \
.load()
jdbc_df2.printSchema()
jdbc_df2.show()
执行过程和结果如下:
还可以使用query选项指定用于将数据读入Spark的查询语句。指定的查询将被圆括号括起来,并在FROM子句中用作子查询。Spark还将为子查询子句分配一个别名。例如,Spark将向JDBC源发出如下形式的查询。
SELECTFROM ( ) spark_gen_alias
使用此选项时有一些限制。
- 不允许同时指定“dbtable”和“query”选项。
- 不允许同时指定“query”和“partitionColumn”选项。当需要指定“partitionColumn”选项时,可以使用“dbtable”选项指定子查询,分区列可以使用作为“dbtable”的一部分提供的子查询别名进行限定。
例如:
jdbc_df4 = spark.read \
.format("jdbc") \
.option("url", "jdbc:mysql://localhost:3306/xueai8") \
.option("query", "select name,age from peoples") \
.option("user", "root") \
.option("password", "admin") \
.load()
jdbc_df4.printSchema()
jdbc_df4.show()
执行过程和结果如下:

