RDD上的Transformation和Action操作
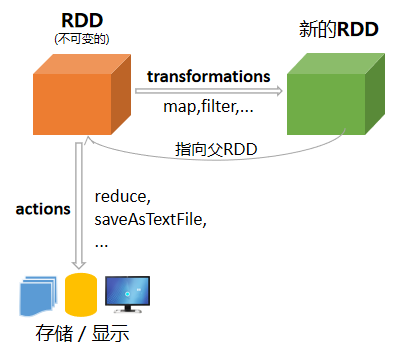
创建了RDD之后,就可以编写Spark程序对RDD进行操作。RDD操作分为两种类型:转换(Transformation)和动作(action)。转换(Transformation)是用来创建RDD的方法,而动作(action)是使用RDD的方法。
RDD Transformation操作
Transformation是转换RDD并返回一个新RDD的操作,如map()和filter()方法,而action是返回一个结果给驱动程序或将结果写入存储并开始一个计算的操作,如count()和first()。
RDD的transformation操作是延迟计算的,只在遇到action时才真正进行计算。许多转换是作用于元素范围内的,也就是一次作用于一个元素。
现在假设有一个RDD,包含元素为{1, 2, 3, 3}。首先,让我们构造出这个RDD:
from pyspark.sql import SparkSession
# 构建SparkSession和SparkContext实例
spark = SparkSession.builder \
.master("spark://xueai8:7077") \
.appName("pyspark demo") \
.getOrCreate()
sc = spark.sparkContext
# 构造一个RDD
rdd = sc.parallelize([1,2,3,3])
接下来,学习普通RDD上的各种转换操作方法:
map(func)
map是使用函数转换每个RDD元素并返回一个新的RDD。
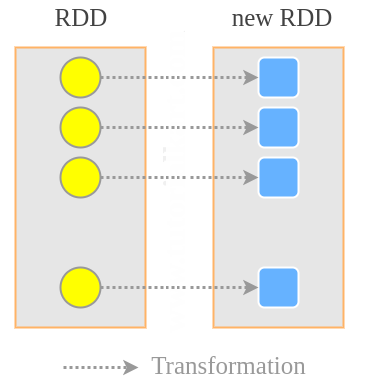
# map转换 rdd1 = rdd.map(lambda x: x + 1) # tansformation rdd1.collect() # action
执行以上代码,输出结果如下:
[2,3,4,4]
mapPartitions(func)
mapPartitions是一个转换操作,应用于RDD中的每个分区。它是RDD的一个属性,它将一个函数应用到RDD的分区上,并返回一个新的RDD。需要在每个分区上一次性调用的数据模型的大量初始化可以通过使用MapPartitions来完成。
# 该函数返回数据分区中列出的元素的和 def fun1(iterator): yield sum(iterator) rdd1 = rdd.mapPartitions(fun1) rdd1.collect()
执行以上代码,输出结果如下:
[3, 6]
mapPartitions将结果保存在内存中,直到所有的行都在分区中处理完毕。 这个函数可以用来创建在每个分区中应用一次的逻辑,比如创建连接、终止连接。
mapPartitionsWithIndex(func)
mapPartitionsWithIndex(f)类似于map,但在每个分区上单独运行f函数,并提供分区的索引。请看下面的示例代码:
x = sc.parallelize([1,2,3,4,5,6,7,8,9,10,11], 2)
# 定义函数 fun3
def fun3(partitionIndex, p):
for row in p:
yield partitionIndex,row
y = x.mapPartitionsWithIndex(fun3)
y.collect()
执行以上代码,输出结果如下:
[(0, 1), (0, 2), (0, 3), (0, 4), (0, 5), (1, 6), (1, 7), (1, 8), (1, 9), (1, 10), (1, 11)]
可将mapPartitionsWithIndex用于确定分区内的数据倾斜。请看下面的示例代码:
x = sc.parallelize([1,2,3,4,5,6,7,8,9,10,11], 2)
# 定义函数
def partitionElementCount(idx, iterator):
count = 0
for _ in iterator:
count += 1
return [idx, count]
# 应用
x.mapPartitionsWithIndex(partitionElementCount).glom().collect()
执行以上代码,输出结果如下:
[[0, 5], [1, 6]]
flatMap(func)
flatMap使用一个函数来转换每个RDD元素,这个函数可以将多个元素返回到新的RDD。
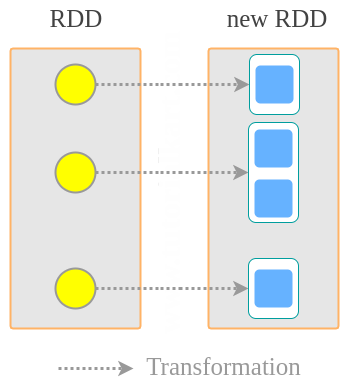
rdd2 = rdd.flatMap(lambda x: range(x,4)) rdd2.collect()
执行以上代码,输出结果如下所示:
[1, 2, 3, 2, 3, 3, 3]
filter(func)
filter使用一个函数来过滤每个RDD元素,返回一个父RDD的一个子集。
# filter转换 rdd3 = rdd.filter(lambda x: x!=1) rdd3.collect()
执行以上代码,输出结果如下所示:
[2, 3, 3]
sample(withReplacement, fraction, seed)
返回这个RDD的一个采样子集。其中各参数含义如下:
- withReplacement:是否可以对元素进行多次采样(采样后替换)
- fraction:抽样因子。对于without replacement,每个元素被选中的概率,fraction值必须是[0,1]之间;对于with replacement,每个元素被选择的期望次数,fraction值必须大于等于0。
- seed:用于随机数生成器的种子。
rdd4 = rdd.sample(False,0.5) rdd4.collect()
执行以上代码,输出结果如下所示:
[2, 3]
distinct([numPartitions]))
返回一个包含这个RDD中不同元素的新RDD。
rdd5 = rdd.distinct() rdd5.collect
执行以上代码,输出结果如下所示:
[2, 1, 3]
keyBy(func): RDD[(K, T)]
当在类型为T的数据集上调用时,返回一个(K, T)元组对的数据集。通过应用func函数创建这个RDD中元素的元组。
x = sc.parallelize(["John", "Fred", "Anna", "James"]) y = x.keyBy(lambda w: w[0]) y.collect()
执行以上代码,输出结果如下所示:
[('J', 'John'), ('F', 'Fred'), ('A', 'Anna'), ('J', 'James')]
groupBy(func),groupBy(func, numPartitions),groupBy(func, partitioner)
当在类型为T的数据集上调用时,返回一个(K, Iterable[T])元组的数据集。
返回分组项的RDD。每个组由一个key和一系列映射到该key的元素组成。每个组内元素的顺序不能得到保证,甚至在每次计算结果RDD时可能会有所不同。这个方法有可能会引起数据shuffle。
# 创建单词的RDD
x = sc.parallelize(["Joseph", "Jimmy", "Tina", "Thomas", "James", "Cory", "Christine", "Jackeline", "Juan"], 4)
# 在x上应用groupBy操作
y = x.groupBy(lambda word: word[0])
for t in y.collect():
print((t[0],[i for i in t[1]]))
执行以上代码,输出结果如下所示:
('J', ['Joseph', 'Jimmy', 'James', 'Jackeline', 'Juan'])
('T', ['Tina', 'Thomas'])
('C', ['Cory', 'Christine'])
sortBy(func,[ascending],[numPartitions])
返回这个按给定key函数排序的RDD。
rdd = sc.parallelize([3,1,90,3,5,12])
rdd.collect() # [3, 1, 90, 3, 5, 12]
// 默认升序
rdd.sortBy(lambda x: x).collect() # [1, 3, 3, 5, 12, 90]
// 降序
rdd.sortBy(lambda x: x, ascending=False).collect() # [90, 12, 5, 3, 3, 1]
# 默认不改变分区数
result = rdd.sortBy(lambda x: x, ascending=False)
print("分区数:", result.getNumPartitions()) # 分区数: 2
# 改变分区数为1
result = rdd.sortBy(lambda x: x, ascending=False, numPartitions=1)
print("分区数:", result.getNumPartitions()) # 分区数: 1
上面的实例对rdd中的元素进行升序排序。并对排序后的RDD的分区个数进行了修改,上面的result就是排序后的RDD,默认的分区个数是2,而我们对它进行了修改,所以最后变成了1。
glom():RDD[Array[T]]
返回将每个分区中的所有元素合并到一个数组中创建的RDD,一个分区一个数组。当在类型为T的RDD上调用时,返回一个Array[T]的RDD。
# 构造RDD x = sc.parallelize([1,2,3,4,5,6,7,8,9,10], 2) # 将每个分区中的所元素合并成一个数组并返回 x.glom().collect() # [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]] # 分区求和 x.glom().map(lambda x: sum(x)).collect() # [15, 40]
repartition(numPartitions)
随机地重新shuffle RDD中的数据,以创建更多或更少的分区,并在它们之间进行平衡。repartition()用于增加或减少RDD分区。需要注意的一点是,PySpark的repartition()是非常昂贵的操作,因为它会跨多个分区转移数据。
rdd = sc.parallelize(range(0,20))
print("当前分区数:", rdd.getNumPartitions()) # 2
rdd2 = rdd.repartition(4)
print("重分区后的分区数:", rdd2.getNumPartitions()) # 4
coalesce(numPartitions)
将RDD中的分区数量减少到numpartition。coalesce()仅用于以一种有效的方式减少分区数量,适用于过滤大型数据集后更有效地运行操作。这是repartition()的优化或改进版本,其中使用合并可以降低跨分区的数据移动。
rdd = sc.parallelize(range(0,20))
print("当前分区数:", rdd.getNumPartitions()) # 2
rdd3 = rdd.coalesce(1)
print("重分区后的分区数:", rdd3.getNumPartitions()) # 1
randomSplit(weights, seed)
使用提供的权重随机分割这个RDD,以数组形式返回拆分后的RDD(即拆分后的RDD组成的数组并返回)。其中各参数含义如下:
- weights:分割的权重,如果它们的和不等于1,将被标准化。
- seed:随机种子
# 构造一个RDD rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9,10]) # 按80/20分割数据集 splitedRDD = rdd1.randomSplit([0.8, 0.2]) # 查看 splitedRDD[0].collect() # [1, 2, 3, 6, 7, 8, 9] splitedRDD[1].collect() # [4, 5, 10]
RDD集合运算
现在假设有两个RDD,分别包含{1,2,3,3}和{3,4,5}。首先,让我们构造出这两个RDD:
# 构造这两个RDD
rdd1 = sc.parallelize([1,2,3,3])
rdd2 = sc.parallelize([3,4,5])
for i in rdd1.collect():
print(i, end=" ")
print()
rdd2.collect() # [3,4,5]
接下来操作这两个RDD,如下:
union(otherDataset)
将两个RDD进行垂直合并,其作用相当于SQL中的union all操作。
# union转换 rdd3 = rdd1.union(rdd2) rdd3.collect() # [1, 2, 3, 3, 3, 4, 5]
intersection(otherDataset)
计算两个RDD的交集,即返回包含两个RDD共同元素的新RDD。
# intersection转换 rdd4 = rdd1.intersection(rdd2) rdd4.collect() # [3]
subtract(otherDataset)
计算两个RDD的差集,即返回仅包含第一个RDD中有而第二个RDD中没有的元素的新RDD。
# subtract转换 rdd5 = rdd1.subtract(rdd2) rdd5.collect() # [1, 2]
cartesian(otherDataset)(即笛卡尔集)
当在类型为T和U的RDD上调用时,返回一个(T, U)对(所有元素对)的RDD。
# cartesian转换(即笛卡尔集) rdd6 = rdd1.cartesian(rdd2) rdd6.collect()
执行上面的代码,输出结果如下:
[(1, 3), (2, 3), (1, 4), (2, 4), (1, 5), (2, 5), (3, 3), (3, 3), (3, 4), (3, 4), (3, 5), (3, 5)]
zip(other)
当在类型为T和U的RDD上调用时,返回一个(T, U)对的RDD,其中元组第一个元素来自第一个RDD,第二个元素来自第二个RDD。这类似于拉链操作。假设两个RDD具有相同数量的分区和每个分区中相同数量的元素(例如,一个RDD通过另一个RDD上的map生成)。
rdd1 = sc.parallelize(["aa","bb","cc"])
rdd2 = sc.parallelize([1,2,3])
rdd3 = rdd1.zip(rdd2)
rdd3.collect() # [('aa', 1), ('bb', 2), ('cc', 3)]
RDD Action操作
Action是返回一个结果给驱动程序或将结果写入存储的操作,并开始一个计算,如count()和first()。
一旦创建了RDD,就只有在执行了action时才会执行各种转换。一个action的执行结果可以是将数据写回存储系统,或者返回到驱动程序,以便在本地进行进一步的计算。
常用的action操作函数如下:
- reduce(func):使用函数func(接受两个参数并返回一个参数)聚合数据集的元素。这个函数应该是交换律和结合律,这样才能并行地正确地计算它。
- collect():将RDD操作的所有结果返回给驱动程序。这通常对产生足够小的数据集的操作很有用。
- count():这会返回数据集中的元素数量或RDD操作的结果输出。
- first():返回数据集的第一个元素或RDD操作产生的结果输出。它的工作原理类似于take(1)函数。
- take(n):返回RDD的前n个元素。它首先扫描一个分区,然后使用该分区的结果来估计满足该限制所需的其他分区的数量。这个方法应该只在预期得到的数组很小的情况下使用,因为所有的数据都加载到驱动程序的内存中。
- top(n):按照指定的隐式排序[T]从这个RDD中取出最大的k个元素,并维护排序。这与takeOrdered相反。这个方法应该只在预期得到的数组很小的情况下使用,因为所有的数据都加载到驱动程序的内存中。
- takeSample(withReplacement, num, [seed]):返回一个数组,其中包含来自数据集的元素的num个随机样本。
- takeOrdered(n):返回RDD的前n个(最小的)元素,并维护排序。这和top是相反的。这个方法应该只在预期得到的数组很小的情况下使用,因为所有的数据都加载到驱动程序的内存中。
- saveAsTextFile(path):将数据集的元素作为文本文件(或文本文件集)写入本地文件系统、HDFS或任何其他hadoop支持的文件系统的给定目录中。Spark将对每个元素调用toString,将其转换为文件中的一行文本。
- countByKey():仅在类型(K, V)的RDDs上可用。返回(K, Int)对的hashmap和每个键的计数。
- foreach(func):在数据集的每个元素上运行函数func。
假设一个RDD,包含{1, 2, 3, 3}。下面是一些常用action操作代码示例。
// 构造RDD val rdd1 = spark.sparkContext.parallelize(Array(4,5,1,2,8,9,3,6,7,10)) rdd.count rdd.first rdd.collect // countByValue: 返回每个元素在RDD中出现的次数 rdd.countByValue // take(n):返回RDD中的前n个元素 rdd.take(3) // top(n):返回RDD中的top(n)个元素 rdd.top(3) // takeOrdered(n):返回n个元素,基于隐含的顺序 rdd.takeOrdered(3) // takeSample(withReplacement,num,[seed]):随机返回num个元素 rdd.takeSample(false,2)
下面我们着重介绍其中几个action函数。
reduce
这是一个action,并且一个宽依赖操作。例如,在下面的示例中,使用reduce计算List(1,2,3,3)中所有元素的和。
# 构造RDD rdd = sc.parallelize([1,2,3,3]) # reduce(func) rdd.reduce(lambda x,y: x + y) # 9
aggregate(zeroValue)(seqOp,combOp)
类似于reduce,但用来返回不同的类型。这个函数聚合每个分区的元素,然后使用给定的combine组合函数和一个中性的“零值”,对所有分区的结果进行聚合。
例如,有一个RDD,包含元素[1,2,3,4],分区数为2。那么可以通过aggregate函数来计算RDD元素的平均值。计算过程如下图所示。
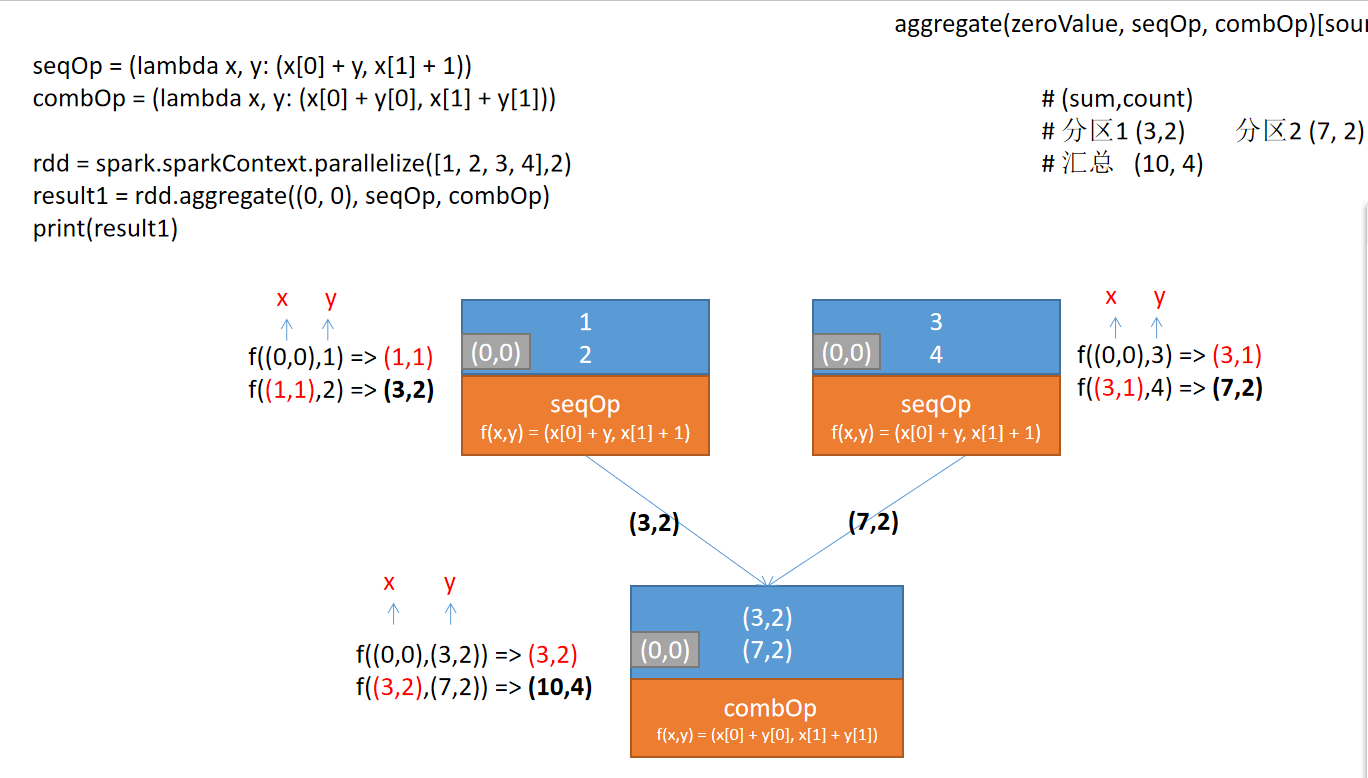
【示例】使用Spark RDD aggregate()函数计算RDD元素的平均值。
分析:要算平均值,需求计算出两个值,一个是RDD的各元素的累加和,另一个是元素计数。对于加法计算,要初始化为(0, 0)。
from pyspark.sql import SparkSession
# 构建SparkSession和SparkContext实例
spark = SparkSession.builder \
.master("spark://xueai8:7077") \
.appName("pyspark demo") \
.getOrCreate()
sc = spark.sparkContext
# 构造RDD
rdd = sc.parallelize([1,2,3,4,5,3,2])
# 定义分区计算函数
seqOp = (lambda accu, v: (accu[0] + v, accu[1] + 1))
# 定义分区结果合并函数
combOp = (lambda accu1, accu2: (accu1[0] + accu2[0], accu1[1] + accu2[1]))
# 执行aggregate聚合计算
result = rdd.aggregate((0, 0), seqOp, combOp)
# 输出
print(result) # (20, 7)
# 计算平均值
avg = result[0] / result[1]
print("RDD元素的平均值为:", avg) # 2.857142857142857
# 停止
sc.stop()
spark.stop()
执行以上代码,输出结果如下:
(20, 7)
RDD上的描述性统计操作
Spark在包含数值数据的RDD上提供了许多描述性统计操作。描述性统计都是在数据的单次传递中计算的。请看下面的代码:
# 构造一个RDD rdd1 = sc.parallelize(range(1,21,2)) rdd1.collect() # [1, 3, 5, 7, 9, 11, 13, 15, 17, 19] # 描述性统计方法 rdd1.sum() # 100 rdd1.max() # 19 rdd1.min() # 1 rdd1.count() # 10 rdd1.mean() # 10.0 rdd1.variance() # 33.0 rdd1.stdev() # 5.744562646538029 # 用直方图可视化数据分布: # 方法1 # rdd1.histogram([1.0, 10.0, 20.9]) # ([1.0, 10.0, 20.9], [5, 5]) rdd1.histogram([1.0, 8.0, 20.9]) # ([1.0, 8.0, 20.9], [4, 6]) # 方法2 rdd1.histogram(3) # ([1, 7, 13, 19], [3, 3, 4])
如果是多次调用描述性统计方法,则可以使用StatCounter对象。可以通过调用stats()方法返回一个StatCounter对象:
# 通过调用stats()方法返回一个StatsCounter对象 status = rdd1.stats() print(status.count()) print(status.mean()) print(status.stdev()) print(status.max()) print(status.min()) print(status.sum()) print(status.variance())
执行以上代码,输出结果如下:
10 10.0 5.744562646538029 19.0 1.0 100.0 33.0
