PySpark RDD编程模型
在Spark中,使用RDD对数据进行处理,通常遵循如下的模型:
- 首先,将待处理的数据构造为RDD;
- 对RDD进行一系列操作,包括Transformation和Action两种类型操作;
- 最后,输出或保存计算结果。
这个处理流程可以用下图表示:

接下来我们通过一个具体的示例来掌握RDD编程的一般流程。
单词计数应用程序
【示例】使用Spark RDD实现单词计数。这里我们使用Jupyter Notebook作为开发工具,大家可以根据自己的喜好选择任意其他工具。
(1)首先启动HDFS集群和Spark集群。
$ start-dfs.sh $ cd ~/bigdata/spark-3.1.2 $ ./sbin/start-all.sh
(2)首先准备一个文本文件word.txt,内容如下:
good good study day day up
(3)将该文本文件上传到HDFS的"/data/spark/"目录下:
$ hdfs dfs -put word.txt /data/spark/
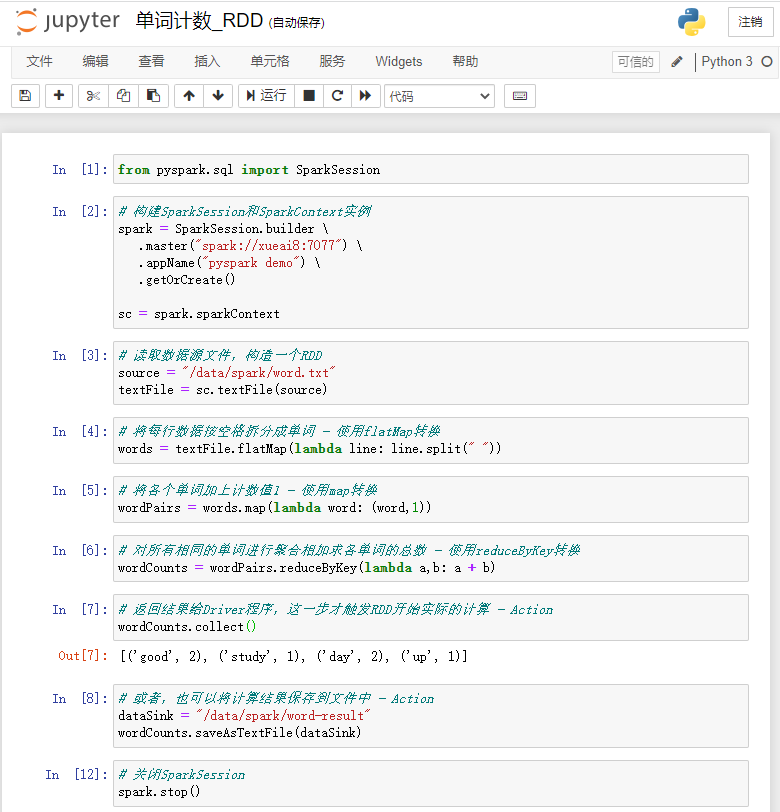
(4)在Jupyter中新建一个notebook。在notebook的单元格中,执行代码。
(5)首先创建SparkSession和SparkContext的实例。
from pyspark.sql import SparkSession
# 构建SparkSession和SparkContext实例
spark = SparkSession.builder \
.master("spark://xueai8:7077") \
.appName("pyspark demo") \
.getOrCreate()
sc = spark.sparkContext
(6)读取数据源文件,构造一个RDD。
source = "/data/spark/word.txt" textFile = sc.textFile(source)
(7)将每行数据按空格拆分成单词 - 使用flatMap转换
words = textFile.flatMap(lambda line: line.split(" "))
(8)将各个单词加上计数值1 - 使用map转换
wordPairs = words.map(lambda word: (word,1))
(9)对所有相同的单词进行聚合相加求各单词的总数 - 使用reduceByKey转换
wordCounts = wordPairs.reduceByKey(lambda a,b: a + b)
(10)返回结果给Driver程序,这一步才触发RDD开始实际的计算 - Action
wordCounts.collect()
可以看到输出结果如下:
[('good', 2), ('study', 1), ('day', 2), ('up', 1)]
(11)或者,也可以将计算结果保存到文件中 - Action
dataSink = "/data/spark/word-result" wordCounts.saveAsTextFile(dataSink)
在Jupyter Notebook中交互式数据处理过程如下图所示:
以上代码也可以精简为下面一句:
source = "/data/spark/word.txt"
sc.textFile(source) \
.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word,1)) \
.reduceByKey(lambda a,b: a + b) \
.collect()
