使用spark-submit提交PySpark程序
对于公司大数据的批量处理或周期性数据分析/处理任务,通常采用编写好的Spark程序,并通过spark-submit指令的方式提交给Spark集群进行具体的任务计算,spark-submit指令可以指定一些向集群申请资源的参数。
Spark安装包附带有spark-submit.sh脚本文件(适用于Linux、Mac)和spark-submit.cmd命令文件(适用于Windows)。这些脚本可以在$SPARK_HOME/bin目录下找到。
spark-submit命令是一个实用程序,通过指定选项和配置向集群中运行或提交PySpark应用程序(或job作业)。spark-submit命令支持以下功能。
- 在Yarn、Kubernetes、Mesos、Stand-alone等不同的集群管理器上提交Spark应用。
- 在client客户端部署模式或cluster集群部署模式下提交Spark应用。
下面是一个带有最常用命令选项的spark-submit命令。
./bin/spark-submit \ --master\ --deploy-mode \ --conf \ --driver-memory g \ --executor-memory g \ --executor-cores \ --jars --class \ \ [application-arguments]
提交pi.py程序,计算圆周率π值
Spark安装包中自带了一个使用蒙特卡罗方法求圆周率π值的程序。下面我们使用spark-submit将其提交到PySpark集群上以standalone模式运行,以掌握spark-submit提交PySpark程序的方法。
请按以下步骤操作。
1)打开终端窗口。
2)确保已经启动了Spark集群(standalone)模式(启动方式见上一节)
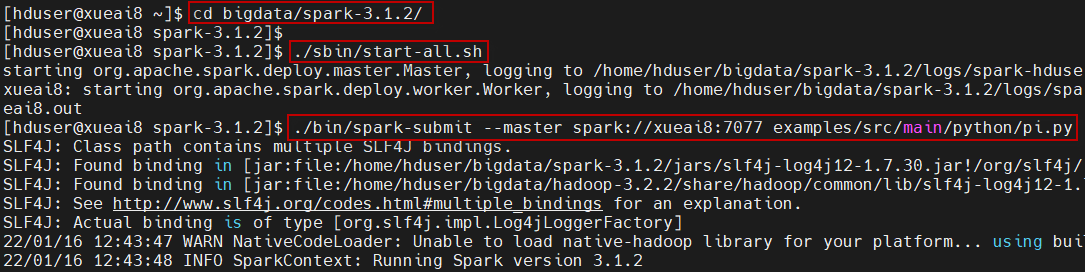
3)进入到Spark主目录下,执行以下操作:
$ cd ~/bigdata/spark-3.1.2 $ ./bin/spark-submit --master spark://xueai8:7077 examples/src/main/python/pi.py
说明:
- --master参数指定要连接的集群管理器,这里是standalone模式。
- 最后一个参数是所提交的python程序。
运行结果如下图所示:
......

提交PySpark程序到YARN集群上执行
也可以将PySpark程序运行在YARN集群上,由YARN来管理集群资源。下面我们使用spark-submit将pi.py程序提交到Spark集群上以YARN模式运行。
请按以下步骤执行。
1)打开终端窗口。
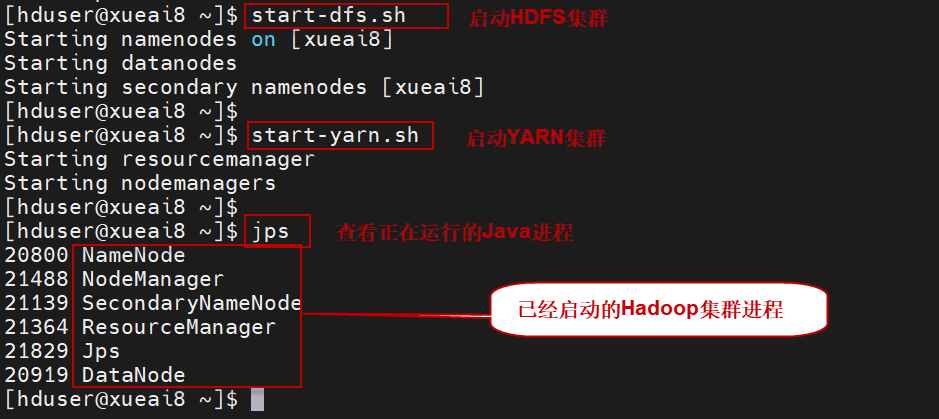
2)不需要启动Spark集群。启动Hadoop/YARN集群:
$ start-dfs.sh $ start-yarn.sh
执行过程如下图所示:
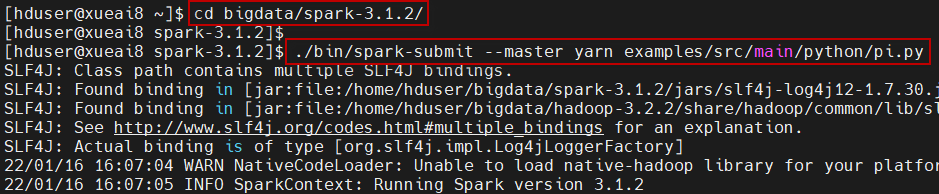
3)进入到Spark主目录下,执行以下操作:
$ cd ~/bigdata/spark-3.1.2 $ ./bin/spark-submit --master yarn examples/src/main/python/pi.py
执行过程如下图所示:
执行结果如下图所示:

