构造DataFrame-简单创建方式
有多种方式可用来创建DataFrame:
- 简单创建单列和多列DataFrame;
- 转换已经存在的RDD;
- 加载外部数据。
创建单列DataFrame
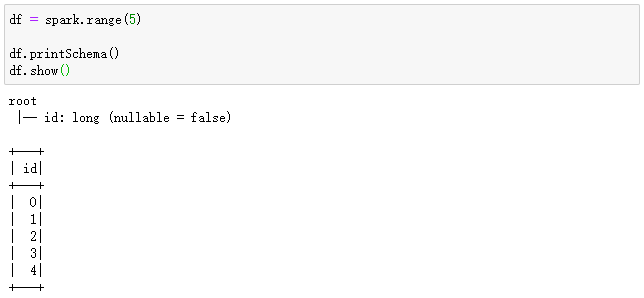
SparkSession有一个函数叫range,可以很容易地创建单列DataFrame,带有列名id和类型LongType。
请执行以下的代码:
# 创建单列DataFrame,默认列名是id,类型是LongType df = spark.range(5) df.printSchema() df.show()
输出结果如下所示:
还可以指定列名:
df1 = spark.range(5).toDF("num")
df1.printSchema()
df1.show()
输出结果如下所示:

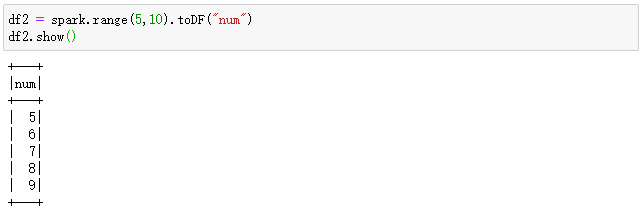
另外,还可以指定范围的起始(含)和结束值(不含):
df2 = spark.range(5,10).toDF("num")
df2.show()
输出结果如下所示:
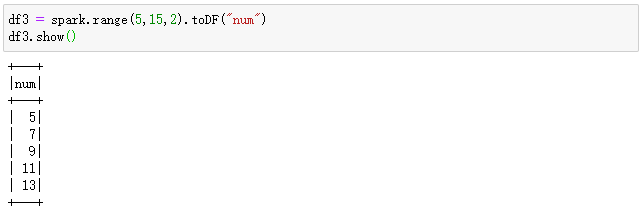
另外,还可以指定步长:
df3 = spark.range(5,15,2).toDF("num")
df3.show()
输出结果如下所示:
请注意,toDF采用的是元组列表,而不是标量元素。
创建多列DataFrame
通过将一个元组集合转换为一个DataFrame,可创建多列DataFrame。这需要使用SparkSession对象的toDF方法。toDF方法将列标签列表作为可选的参数,以指定转换后的DataFrame的标题行。
请执行下面的代码:
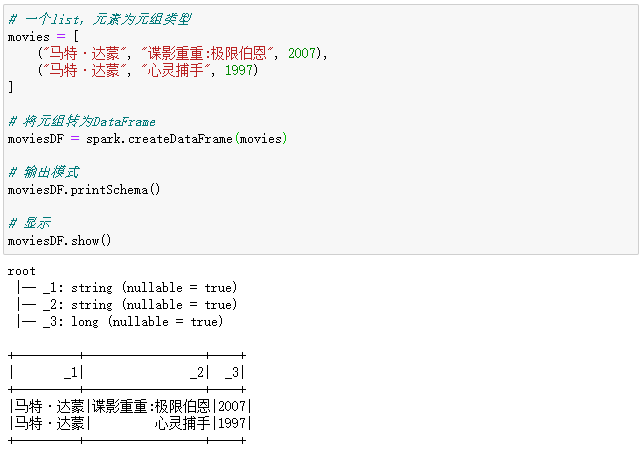
# 一个list,元素为元组类型
movies = [
("马特·达蒙", "谍影重重:极限伯恩", 2007),
("马特·达蒙", "心灵捕手", 1997)
]
# 将元组转为DataFrame
moviesDF = spark.createDataFrame(movies, schema=['actor', 'title', 'year'])
# 输出模式
moviesDF.printSchema()
# 显示
moviesDF.show()
输出结果如下所示:
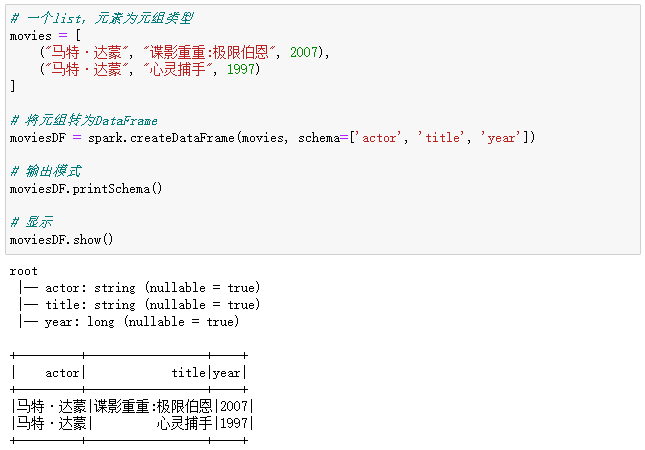
通过元组来创建单列或多列DataFrame,每个元组类似于一行。可以选择标题列;否则,Spark会创建一些模糊的名称,比如_1、_2。列的类型推断是隐式的。