数据采集与实时计算-任务一:实时数据采集
编写Scala工程代码,使用Flink消费Kafka中Topic为order的数据并进行相应的数据统计计算。
子任务
子任务说明
1、在Master节点使用Flume采集实时数据生成器26001端口的socket数据,将数据存入到Kafka的Topic中(topic名称为order,分区数为4),将Flume的配置截图粘贴至对应报告中;
2、Flume接收数据注入kafka 的同时,将数据备份到HDFS目录/user/test/flumebackup下,将备份结果截图粘贴至对应报告中。
实现原理
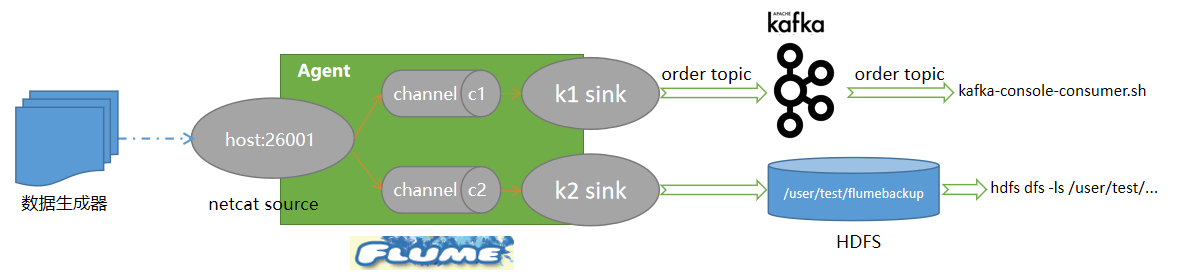
技术参考1:安装Apache Flume。
技术参考2:Flume集成Kafka。
后面的操作基于小白学苑的PBCP(个人大数据竞赛平台)。
Flume配置
在$FLUME_HOME/conf/目录下,创建一个flume配置文件gs2022.conf,编辑内容如下:
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
a1.sources.r1.channels = c1 ......
......
抱歉,只有登录会员才可浏览!会员登录
