Flume集成Kafka
在生产环境下,通常使用Flume采集日志数据,并将采集到的日志数据发送到Kafka上。这里Flume充当了Kafka生产者角色。而对于Kafka来说,关键是如何接收来自Flume的数据。我们需要在Kafka中创建一个主题topic,然后Flume将其采集到的日志数据发送到该topic上即可。从整体上讲,逻辑应该是比较简单的,如下图所示:
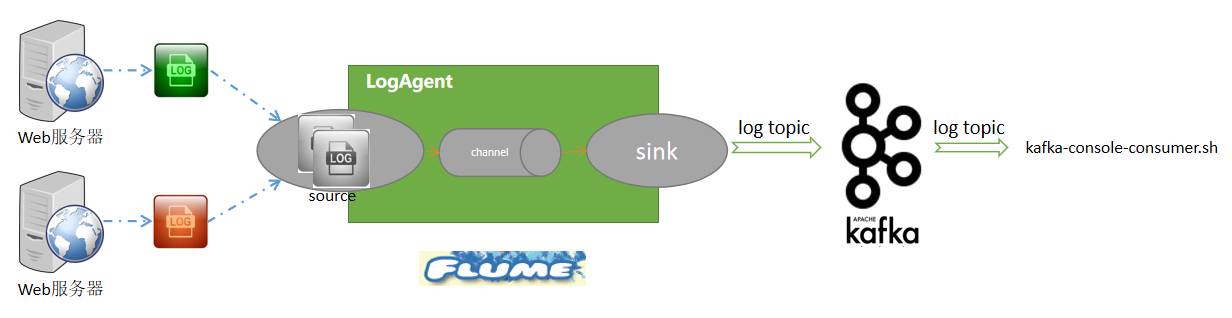
这里我们使用Kafka自带的消费者角色来读取Kafka接收到的日志数据并输出到控制台上显示。
Flume提供了将数据写入Kafka的Kafka Sink组件,因此针对上面这个架构,主要就是配置Flume的Agent,Agent负责实时采集日志文件,将采集到的数据写入Kafka中。
Kafka Sink
Kafka sink是一个Flume sink实现,用于发布数据到Kafka topic。它背后的主要目标是集成Apache Flume和Kafka。这使得基于拉的处理系统可以处理来自各种Flume源的数据。该接收器目前支持Kafka服务器0.10.1.0版本或更高版本。
Kafka Sink的一些属性如下表所示:
| 属性名称 | 默认值 | 描述 |
|---|---|---|
| type | - | 它指定组件类型。必须是 org.apache.flume.sink.kafka.KafkaSink |
| kafka.bootstrap.servers | - | 它指定了Kafka-Sink将要连接到的broker列表,以获得topic分区的列表。这个列表可以是brokers的部分列表。使用的格式是用逗号分隔的主机名:hostname:port。 |
| kafka.topic | default-flume-topic | 它指定消息将被发布到的Kafka主题。如果我们配置这个参数,那么消息将被发布到这个主题。如果事件头包含一个“topic”字段,那么该事件将被发布到该主题,覆盖这里配置的主题。 |
| kafka.flumeBatchSize | 100 | 它指定在一个批处理中应该处理多少条消息。大批量可以提高吞吐量,同时增加延迟。 producer都是按照batch进行发送的,因此batch大小的选择对于producer性能至关重要。producer会把发往同一分区的多条消息封装进一个batch中,当batch满了后,producer才会把消息发送出去。但是也不一定等到满了,这和另外一个参数linger.ms有关。 |
| kafka.producer.acks | 1 | 它指定在认为消息成功写入之前,必须有多少副本确认消息。接受的值为0,表示从不等待应答,1表示只等待leader, -1表示等待所有副本。将此设置为-1,以避免在某些leader失败的情况下数据丢失。 |
| kafka.producer.linger.ms | 0 | 默认是0,表示不做停留。这种情况下,可能有的batch中没有包含足够多的produce请求就被发送出去了,造成了大量的小batch,给网络IO带来的极大的压力。这个值大,则减少了网络IO,提升了整体的TPS。 |
Flume集成Kafka实现
下面我们将演示如何具体实现Flume与Kafka的集成,按照本节一开始描述的流程。请按下面的步骤进行操作。
1)在$FLUME_HOME/conf/目录下,创建一个配置文件file-to-kafka.conf,并编辑内容如下:
# 命名这个agent的组件 agent1.sources = r1 agent1.sinks = sk1 agent1.channels = ch1 # 描述和配置source,注意监视的路径 agent1.sources.r1.type = spooldir agent1.sources.r1.spoolDir=/home/hduser/data/flink/logdata # agent1.sources.r1.includePattern=log-*.txt # 使用一个在内存中缓冲事件的channel agent1.channels.ch1.type = memory agent1.channels.ch1.capacity = 10000 agent1.channels.ch1.transactionCapacity = 100 # 描述sink agent1.sinks.sk1.type = org.apache.flume.sink.kafka.KafkaSink agent1.sinks.sk1.kafka.topic = mylog agent1.sinks.sk1.kafka.bootstrap.servers = xueai8:9092 agent1.sinks.sk1.kafka.flumeBatchSize = 20 agent1.sinks.sk1.kafka.producer.acks = 1 agent1.sinks.sk1.kafka.producer.linger.ms = 10 agent1.sinks.sk1.kafka.producer.compression.type = snappy # 将source和sink绑定到channel agent1.sources.r1.channels = ch1 agent1.sinks.sk1.channel = ch1
在上面的配置文件中,指定监视的文件源路径是/home/hduser/data/flink/logdata。
2)在Kafka中创建主题mylog
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 # 创建一个名为mylog的topic $ ./bin/kafka-topics.sh --create \ --zookeeper localhost:2181 \ --replication-factor 1 \ --partitions 1 \ --topic mylog
3)启动Zookeeper。打开一个终端窗口,执行如下命令:
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/zookeeper-server-start.sh config/zookeeper.properties
等待约30秒左右,等待ZooKeeper启动,然后保持zookeeper运行。
4)启动Kafka。打开另一个终端窗口,执行如下命令:
# 切换到Kafka的安装目录 $ cd ~/bigdata/kafka_2.12-2.4.1 $ ./bin/kafka-server-start.sh config/server.properties
等待大约30秒左右,Kafka启动。然后保持kafka运行。
5)运行Kafka自带的消费者脚本,让其监听mylog主题。打开另一个终端窗口,执行下面的命令:
# 切换到Kafka的安装目录
$ cd ~/bigdata/kafka_2.12-2.4.1
$ ./bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic my-topic \
--from-beginning
保持运行。
6)启动Flume Agent。另打开一个终端窗口,执行如下命令:
$ ./bin/flume-ng agent \ -n agent1 \ -c ./conf -f ./conf/file-to-kafka.conf \ -Dflume.root.logger=INFO,console
7)任意位置创建一个文件,例如log-01.txt,随意编辑一些内容,比如:
good good study day day up
保存并关闭文件。然后使用如下命令将该文件拷贝或移动到Flume监视的目录位置,命令如下:
$ mv log-01.txt ~/home/hduser/data/flink/logdata/
注意观察Kafka消费者脚本运行窗口,会看到Flume已经快速而准确地把这个日志文件发送给了Kafka,并且消费者脚本程序及时地消费并输出了该日志文件的内容。如下图所示:

另一个示例:模拟日志产生的实时采集
上一个示例中,我们把整个日志文件拷贝到了Flume监视的spoolDir目录下(在file-to-kafka.conf文件中配置的)。实际生产中,日志记录是随时间一行一行产生的。下面我们就配置一个这样的Flume源,并同样发送到Kafka。
同样在$FLUME_HOME/conf/目录下,新创建一个exec-to-kafka.conf配置文件,并编辑其内容如下:
# 命名这个agent的三个组件 agent1.sources = r1 agent1.sinks = sk1 agent1.channels = ch1 # 配置source源,注意这里的类型是exec agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /home/hduser/data/flink/logdata/mylog.log # 使用一个在内存中缓冲事件的channel agent1.channels.ch1.type = memory agent1.channels.ch1.capacity = 1000 agent1.channels.ch1.transactionCapacity = 100 # 配置kafka sink,这个保持不变 agent1.sinks.sk1.type = org.apache.flume.sink.kafka.KafkaSink agent1.sinks.sk1.kafka.topic = mylog agent1.sinks.sk1.kafka.bootstrap.servers = xueai8:9092 agent1.sinks.sk1.kafka.flumeBatchSize = 20 agent1.sinks.sk1.kafka.producer.acks = 1 agent1.sinks.sk1.kafka.producer.linger.ms = 10 agent1.sinks.sk1.kafka.producer.compression.type = snappy # 将source和sink绑定到channel agent1.sources.r1.channels = ch1 agent1.sinks.sk1.channel = ch1
然后,与上一示例类似,先后启动Zookeeper、Kafka、kafka-console-consume.sh消费者脚本程序和Flume Agent。
等以上服务或程序都运行之后,接下来打开一个终端窗口,执行如下语句,将内容(模拟日志记录数据)写入到日志文件log-01.txt的文件末尾:
$ echo "good good study" > /home/hduser/data/flink/log-01.txt
此时Flume可以通过tail -F命令实时监控文件中的新增数据,发现有新数据就写入kafka,然后kafka后面的消费者脚本实时拉取数据并输出到控制台。
