Kafka Consumer架构-消费者组和订阅
本节我们将介绍Kafka消费者架构的一些较低层次的细节。我们将讨论Kafka消费者架构,讨论消费者组,以及记录处理如何在消费者组之间共享,和Kafka消费者的故障转移。
Kafka消费者组
可以根据用例或组的功能将消费者分组到一个消费者组中。一个消费组可能负责将记录传送到高速的内存微服务,而另一个消费组将这些记录流到Hadoop。消费者组之间用名称来区分。
每个消费者组都有唯一的id。每个消费者组是一个或多个Kafka主题的订阅者。每个消费者组维护其在每个主题分区的偏移量。如果需要多个订阅者,那么就有多个消费者组。一个记录只传递给一个消费者组中的一个消费者。
一个消费者组中的每个消费者都处理记录,并且该组中只有一个消费者会得到相同的记录。一个消费者组中的消费者进行负载平衡记录处理。
消费者记得他们离开读取的偏移量。每个消费者组在每个分区上都有自己的偏移量。消费者组如下图所示:
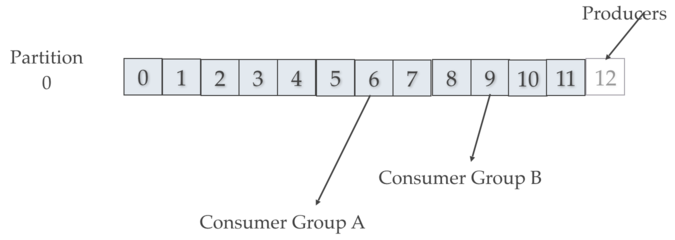
Kafka消费者负载共享
Kafka Consumer消费在Consumer Group内划分了消费者实例的分区。消费者组中的每个消费者都是分区的“公平份额”的唯一消费者。这就是Kafka如何在一个消费者组中对消费者进行负载平衡。消费者组中的消费者成员是由Kafka协议动态处理的。如果新的消费者加入一个消费者组,它将获得分区的份额。如果一个消费者死掉了,它的分区将在消费者组中其余的活动消费者之间进行分割。这是Kafka如何在一个消费者组中执行消费者的故障转移。
Kafka消费者故障转移
消费者在成功处理记录时通知Kafka Broker,这将推进偏移量(offset)。
如果一个消费者在发送提交偏移量给Kafka Broker之前失败了,那么另一个消费者可以从上次提交的偏移量继续。
如果一个消费者在处理记录之后,但在发送提交给Broker之前失败了,那么一些Kafka记录可能会被重新处理。在这个场景中,Kafka实现了“至少一次”的行为,我们应该确保消息(记录传递)是幂等的。
偏移量(offset)管理
Kafka在一个名为“__consumer_offset”的主题中存储偏移量数据。这些主题使用日志压缩,这意味着它们只保存每个键最近的值。
当消费者处理完数据后,它应该提交偏移值(offset)。如果消费者进程死掉,它将能够启动并根据存储在“__consumer_offset”中的偏移量从它停止的位置开始读取,或者如前所述,由消费者组中的另一个消费者接管。
Kafka消费者能看到什么?
Kafka消费者可以消费哪些记录?消费者无法读取未复制的数据。Kafka消费者只能消费超出分区“高水位”偏移量的消息。“日志结束偏移量(log end offset)”是写入日志分区的最后一条记录的偏移量,也是生产者写入下一条记录的位置。“高水位”是成功复制到所有分区的followers的最后一条记录的偏移量。消费者只可以读“高水位”。
分区基数的消费者-负载共享的回归
只有来自同一消费者组的单个消费者可以访问单个分区。如果消费者组中消费者数量超过分区数量,那么额外的消费者将保持空闲。Kafka可以使用空闲消费者进行故障转移。如果有比消费者组更多的分区,那么一些消费者将从多个分区读取数据。
下图显示了在具有2个Kafka服务器、6个分区和2个消费者组的Kafka集群中,消费者组中消费者到分区的关系。
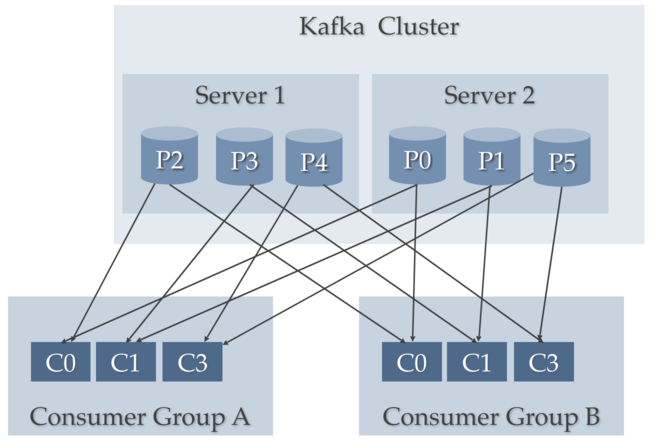
注意服务器1有主题分区P2、P3和P4,而服务器2有分区P0、P1和P5。注意,来自消费者组A的消费者C0正在处理P0和P2的记录。注意,任何消费者组的任何消费者都不会共享单个分区。请注意,每个分区都获得了主题分区的公平份额。
多线程Kafka消费者
可以使用线程在一个JVM进程中运行多个Consumer。
具有多个线程的消费者
如果处理一个记录需要一段时间,单个Consumer可以运行多个线程来处理记录,但管理每个线程/任务的偏移量就更困难了。如果一个消费者运行多个线程,那么相同分区上的两个消息可能由两个不同的线程处理,这使得在没有复杂的线程协调的情况下很难保证记录的传递顺序。如果处理单个任务需要很长时间,那么这种设置可能是合适的,但请尽量避免这样做。
每个消费者线程
如果需要运行多个消费者,那么在它们自己的线程中运行每个消费者。通过这种方式,Kafka可以向消费者交付批量记录,而消费者不必担心偏移顺序。每个消费者使用一个线程可以更容易地管理offset。管理故障转移也更简单(每个进程运行X个消费线程),因为可以让Kafka做主要的工作。
Kafka Consumer架构常见问题
问:什么是消费者组?
答:消费者组是一组执行任务的相关消费者,比如将数据放入Hadoop或向服务发送消息。每个消费者组每个分区都有唯一的偏移量。不同的消费者组可以从分区中的不同位置读取数据。
问:每个消费者组都有自己的offset吗?
答:是的。对于主题中的每个分区,消费者组都有自己的偏移量,这与其他消费者组的偏移量是唯一的。
问:消费者什么时候可以看到记录?
答:消费者可以在记录被完全复制到所有followers之后看到该记录。
问:如果消费者多于分区,会发生什么?
答:额外的消费者保持空闲,直到另一个消费者死亡。
问:如果在同一个JVM的多个线程中运行多个消费者,会发生什么情况?
答:每个线程管理该消费组的分区共享。
