Kafka核心架构与设计模式
Apache Kafka帮助我们解决了来自多个数据源的高负载数据利用的挑战,借助具有数据分析能力的消息传递系统,并克服了这种实时挑战。
Kafka支持很多特性,比如内建的数据分区、最可靠的复制技术和内建的容错机制,这些特性提供了高规模的消息处理利用率。它具有定义分布式平台、订阅记录流并在消息队列中发布这些记录的能力。
Kafka由记录(record)、主题(topic)、消费者(consumer)、生产者(producer)、Broker、日志、分区和集群组成。
- 记录可以有键(可选)、值和时间戳。Kafka记录是不可变的。
- Kafka Topic是一个记录流(例如,"/orders", "/user-signups")。可以将Topic看作提要名称。
- 一个主题有一个日志,它是主题在磁盘上的存储。Topic Log被划分为分区(partition)和段(segment)。
- Kafka Producer API用于产生数据记录流。
- Kafka Consumer API用于消费来自Kafka的记录流。
- Broker是运行在Kafka集群中的Kafka服务器。
- 一组Kafka broker形成一个集群。Kafka集群由多个服务器上的多个Kafka broker组成。Broker有时更多的是指一个逻辑系统或作为一个整体的Kafka。
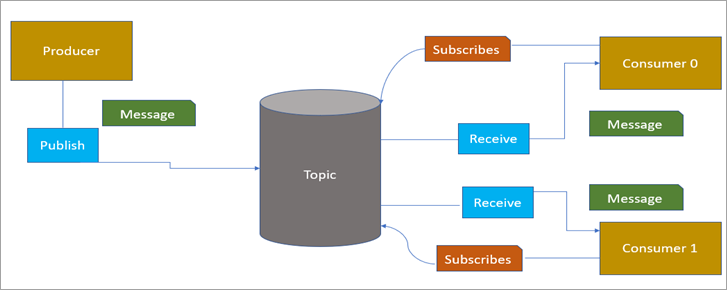
Publish-Subscribe(发布-订阅)Kafka架构
在这个发布-订阅的Kafka架构中,我们有一个消息传递进程,它作为生产者并发布消息,而消费者提取数据。该模型作为松散耦合的微服务工作。
我们可以将Kafka架构分为四种类型的API,它们有各自的特定功能,并且各自独立执行。
- Producer API:它具有作为应用程序将一个或多个Kafka主题中的记录流发布的机制。
- Consumer API:使用此API应用程序可以订阅多个主题,还可以处理并生成记录流。
- Streams API:这个API主要作为一个流处理器来操作,它利用来自多个主题的输入流,并且允许在多个输出主题中使用输出流。这个API可以在应用程序中使用。
- Connector API:此API作为可重用的生产者或消费者运行。使用连接器API,我们可以将Kafka主题用于关系数据库中的现有应用程序和数据操作。
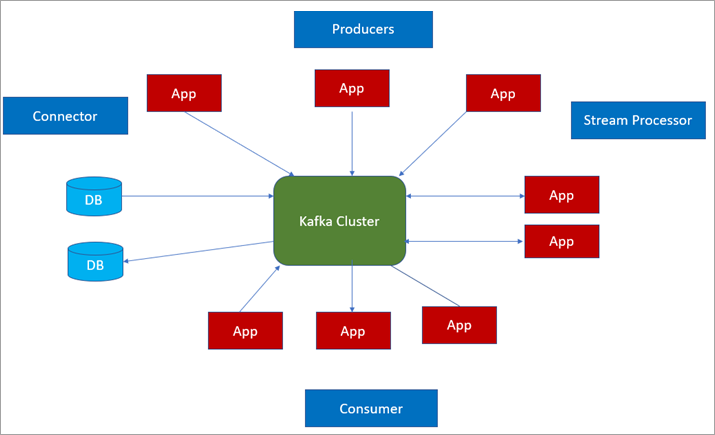
Kafka集群
一个Kafka集群由多个Kafka Broker组成。每个Kafka Broker都有一个唯一的ID(数字)。Kafka Broker包含主题日志分区。连接到一个Broker将引导一个客户端到整个Kafka集群。对于故障转移,希望开始时至少使用3到5个Broker。如果需要的话,一个Kafka集群中可以有10个、100个或1000个Broker。
Kafka集群能平衡来自多个虚拟服务器环境的负载来处理负载,我们可以使用下面的工作流配置Kafka集群。

开发人员可以在本地系统环境中运行Kafka集群,并在应用程序中使用它。
Kafka集群的优势:
- Kafka是高级流处理的中央存储库,它充当一个数据库,并具有Pub-Sub技术的优点。
- 它是一种灵活的工具。
- 具有可靠的分类、分区、复制和容错方式。
- 它能够被扩展,并执行平稳的运行时以及更快的获取结果。
- 持久性——Kafka提供了“分布式提交日志”技术,它通过持久性机制尽可能有效地将消息发送到磁盘上继续。
- 性能——使用快速流集(fast stream set)方法,它提供了多负载数据的快速运行时性能。
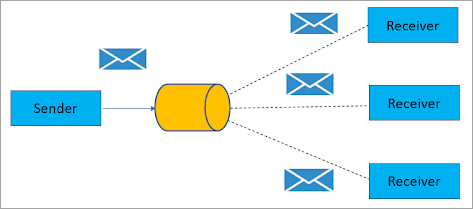
Apache Kafka中的发布/订阅角色
Apache Kafka提供了一种设计模式,我们可以把它看作是一个发布/订阅(publish/subscribe)消息系统,它由发送方作为消息发布者,而订阅方作为消息接收者执行。
我们可以将这两者的工作方式描述如下:
- Consumer(消费者) -> 订阅主题 -> 使用特定主题上的消息
- Reciever(接收方) -> 接收消息 -> 广播给订阅者
基于在集群中所扮演的角色,任何应用程序都可以成为生产者、消费者或流处理器。Kafka集群对于应用程序如何连接到它是灵活的。
Kafka架构-核心Kafka
Kafka使用ZooKeeper来管理集群。ZooKeeper用于协调broker /cluster拓扑。ZooKeeper是一个一致的配置信息文件系统。ZooKeeper用于Broker Topic Partition leader的leader选举。
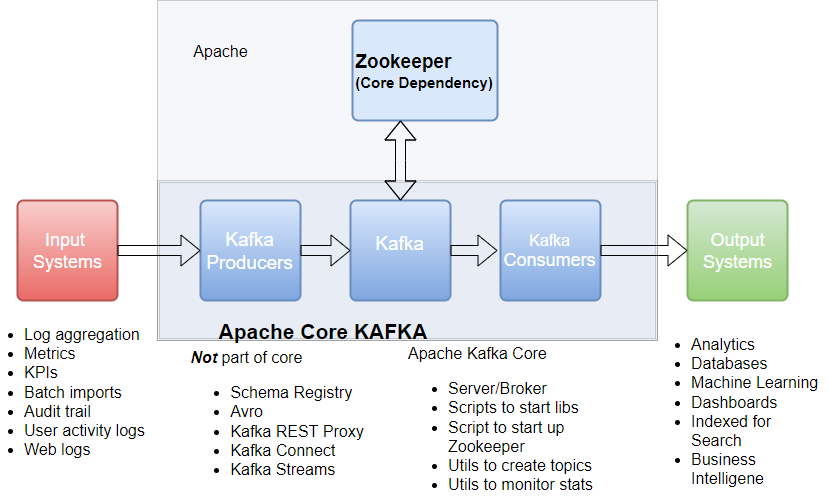
Kafka使用Zookeeper进行Kafka Broker和Topic Partition对的leader选举。Kafka使用Zookeeper来管理集群中Kafka broker的服务发现。Zookeeper将拓扑的变化发送给Kafka,这样集群中的每个节点都知道何时有一个新的broker加入,broker死亡,topic被删除或topic被添加,等等。Zookeeper提供了Kafka集群配置的同步视图。
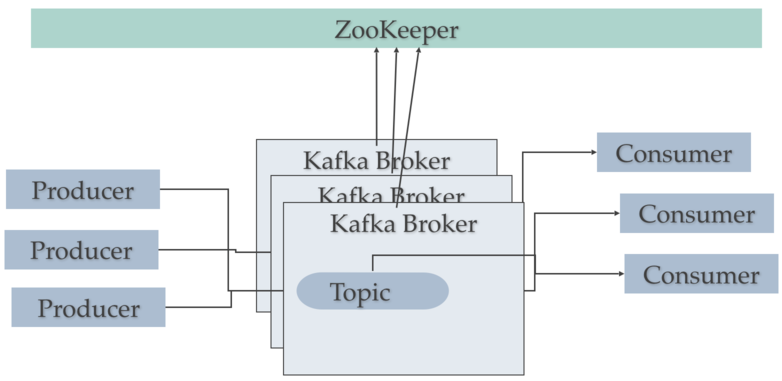
Kafka producer将流数据记录写入topic。Kafka consumer从topic读取数据。主题与日志相关联,日志是磁盘上的数据结构。Kafka将生产者的记录附加到主题日志的末尾。
一个主题日志由多个分区组成,这些分区分布在多个Kafka集群节点上的多个文件上。消费者可以按照自己的节奏读取Kafka主题,并在主题日志中选择自己的位置(偏移)。每个消费者组从他们停止阅读的地方开始跟踪偏移量。Kafka将主题日志分区分布在集群的不同节点上,以实现高性能和水平可伸缩性。扩展分区有助于快速写入数据。主题日志分区是Kafka对主题日志进行分片读写的方式。同样,分区需要让一个消费者组中的多个消费者同时工作。Kafka将分区复制到多个节点以提供故障转移。
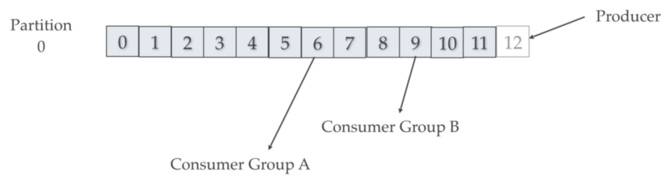
在上图中,消费者组(Consumer Group)记住他们离开时的偏移量(offset)。每个消费者组有他们自己的偏移量。Producer写到Partition 0的offset 12位置处,同时,Consumer Group A从offset 6读取,Consumer Group B从offset 9读取。
如果多个生产者和消费者在同一时间读和写相同的Kafka主题日志,Kafka如何扩展?首先,Kafka是快速的,Kafka按顺序写入文件系统是快速的。在一个现代的快速驱动器上,Kafka可以轻松地每秒写入高达700 MB或更多字节的数据。Kafka通过将主题日志分片到分区来扩展写和读。主题日志可以划分为多个分区,这些分区可以存储在多个不同的服务器上,这些服务器可以使用多个磁盘。多个生产者可以写同一主题的不同分区。来自多个消费者组的多个消费者可以有效地从不同的分区读取数据。
Kafka 故障转移 vs. Kafka灾难恢复
Kafka使用复制备份来进行故障转移。Kafka主题日志分区的复制允许机架或AWS可用分区(AZ)的失败。需要至少3个复制因子才能在一次AZ故障中存活。需要使用Mirror Maker(Kafka core自带的一个Kafka实用程序)用于灾难恢复。Mirror Maker将Kafka集群复制到另一个数据中心或AWS region。
设计模式
我们可以将Kafka设计模式分为两种方式:
1) 流处理设计模式。此模式最适合于从日常使用中的不同类型数据源生成实时数据。
例如,移动设备、网站、各种在线传播媒介。Apache Kafka流集提供了快速处理准确数据的能力和基于流的应用程序的可伸缩性。流设计模式有利于生成实时预测模型。
2) 单事件处理模式。在此设计模式中,我们在常见的实时用例中使用聚合数据、数据处理和流的决策类型。我们可以将该模式视为map过滤器,它映射并清除未识别的事件。
该模式从流执行它并转换每个事件,然后将它们转换到不同的流。我们可以把它看作一个应用程序的完美例子,它从一个流中读取日志消息,并使用高优先级流在一个事件中写入特定异常的结果。
它有一个负载平衡进程,使响应时间更快,执行没有任何失败的应用程序。
