Flink本地集群安装
Flink运行在Linux、Mac OS x和Windows上。本教程中我们将Flink集群搭建在Linux系统上。
使用Flink需要满足以下先决条件:
- 需要安装Java 8/Java11来运行Flink作业/应用程序;
- Scala API(可选地)依赖于Scala 2.11;
- 如果配置为高可用(没有单点故障),需要Apache ZooKeeper;
- 如果配置为高可用(可以从故障中恢复)的流处理,Flink需要某种形式的检查点分布式存储 (HDFS / S3 / NFS / SAN / GFS / Kosmos / Ceph / …)
Flink集群可以运行在单节点上,这称为“Local Cluster”模式。本地集群安装步骤如下所示:
1、要运行Flink,要求必须安装好Java 8.x
使用如下命令检查Java是否已经正确安装:
$ java -version
如果已经正确地安装了Java 8,那么会输出类似如下的内容:

2、下载和安装Flink
下载地址:https://flink.apache.org/downloads.html。可以选择任何喜欢的Hadoop/Scala组合。

将下载的安装包放在"~/software/"目录下,然后将其解压缩到指定的位置(例如,~/bigdata/目录下)。在终端执行如下的命令。
$ cd ~/bigdata $ tar xzf ~/software/flink-1.10.0-bin-scala_2.11.tgz $ cd flink-1.10.0
3、启动一个本地Flink集群
对于单节点设置,Flink是开箱即用的,即不需要更改默认配置,直接启动即可。
$ ./bin/start-cluster.sh
使用jps命令查看,可以看到启动了以下两个进程:
2672 StandaloneSessionClusterEntrypoint 3096 TaskManagerRunner
打开浏览器,输入地址:http://localhost:8081 ,可查看检查调度程序的web前端。web前端应该报告有单个可用的TaskManager实例。
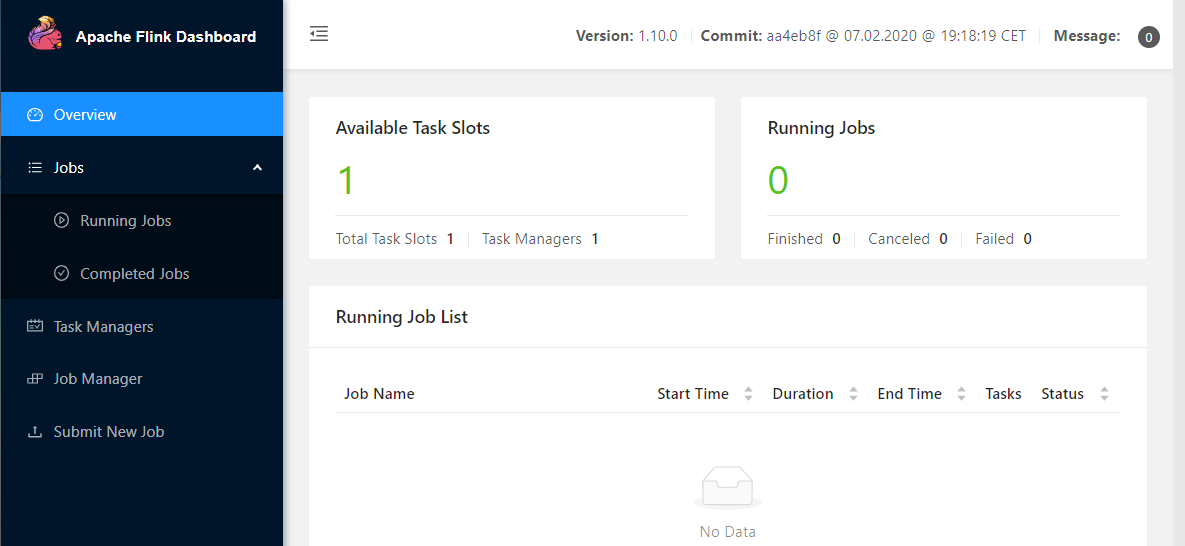
还可以通过检查logs目录中的日志文件来验证系统是否正在运行:
$ tail log/flink-*-standalonesession-*.log
4、运行单词计数程序
1)首先,启动netcat服务器,运行在9000端口:
$ nc -l 9000
2)打开另一个终端,执行以下命令,启动Flink示例程序,监听netcat服务器:
它将从套接字中读取文本,并每5秒打印前5秒内每个不同单词出现的次数,即处理时间的滚动窗口。
$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname localhost --port 9000
3)在netcat控制台,键入一些内容,Flink将会处理它。
good good study day day up
4)启动第三个终端窗口,并在该窗口中执行以下命令,查看日志中的输出:
$ cd ~/bigdata/flink-1.10.0 $ tail -f log/flink-*-taskexecutor-*.out
可以看到如下输出结果:
good : 2 study : 1 day : 2 up : 1
5)还可以检查Flink Web UI来查看job是怎样执行的。
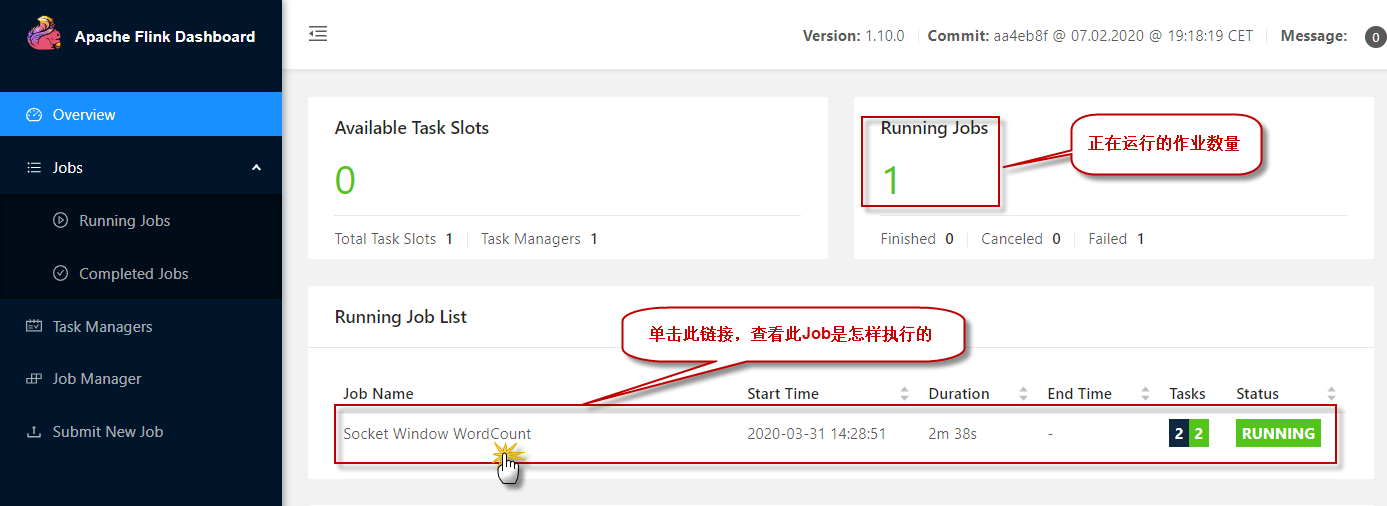
单击图中的【Running Job List】下正在运行的作业列表,查看某一个正在运行的作业执行情况:

5、运行Flink自带的单词计数程序:
Flink安装包自带了一个以文本文件作为数据源的单词计数程序,位于Flink下的"example/batch/"目录下的WordCount.jar包中。可以执行下面的命令来在Flink集群上执行该程序,读取HDFS上的输入数据文件进行处理,并输出计算结果到HDFS上。
注:从flink 1.8开始,Hadoop不再包含在Flink的安装包中,所以需要单独下载并拷贝到Flink的lib目录下。请从Flink官网下载flink-shaded-hadoop2-uber-2.7.5-1.10.0.jar并拷贝到Flink的lib目录下。
$ start-dfs.sh $ ./bin/flink run ./examples/batch/WordCount.jar --input hdfs://hadoop:8020/wc.txt --output hdfs://hadoop:8020/result
上面的命令是在运行WordCount时读写HDFS中的文件,其中--input参数指定要处理的输入文件,--output指定计算结果输出到的结果文件。(注:如果不加hdfs://前缀,默认使用本地文件系统)
执行以下命令查询输出结果:
$ hdfs dfs -cat hdfs://hadoop:8020/result
可以看到以下计算结果:
day 2 good 2 study 1 up 1
6、要停止Flink,在终端窗口输入以下命令:
$ ./bin/stop-cluster.sh
