Flink相关概念
在上一小节,我们准备好了Flink应用程序开发环境,尝试编写了自己的第一个Flink应用程序,并打包为作业提交给Flink集群去执行。在进一步深入学习Flink技术之前,我们有必要来了解一些Flink的核心概念。
Flink数据流
在Flink中,应用程序由数据流组成,这些数据流可以由用户定义的运算符(注:有时我们称这些运算符为“算子”)进行转换。这些数据流形成有向图,从一个或多个源开始,以一个或多个输出结束。

Flink支持流处理和批处理,它是一个分布式的流批结合的大数据处理引擎。在Flink中,认为所有的数据本质上都是随时间产生的流数据,把批数据看作是流数据的特例,只不过流数据是一个无界的数据流,而批数据是一个有界的数据流(例如固定大小的数据集)。如下图所示:
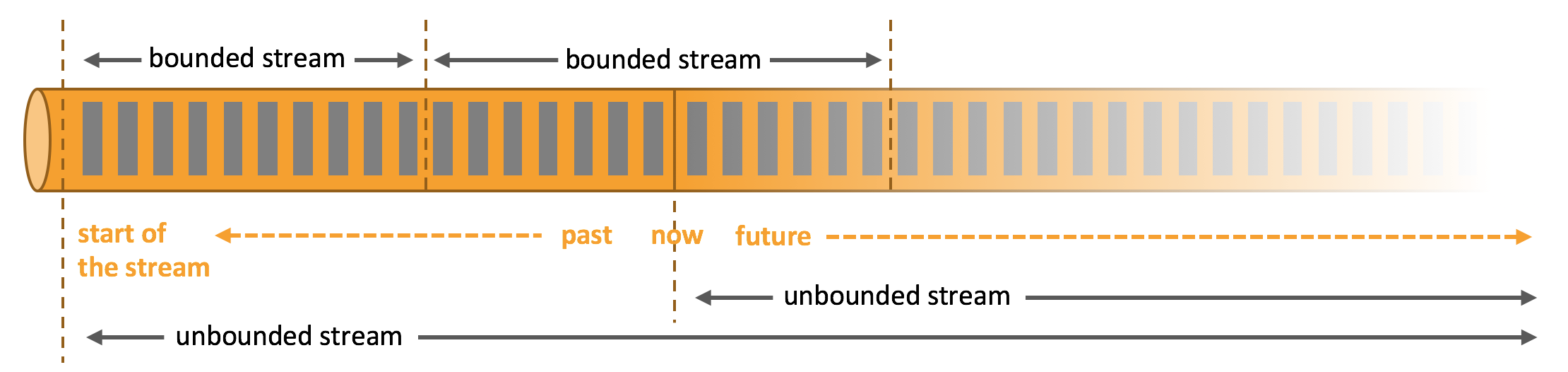
因此,Flink是一个用于在无界和有界数据流上进行有状态计算的通用的处理框架,它既具有处理无界流的复杂功能,也具有专门的运算符来高效地处理有界流。通常我们称无界数据为实时数据,来自消息队列或分布式日志等流源(如Apache Kafka或Kinesis)。而有界数据,通常指的是历史数据,来自各种数据源(如文件、关系型数据库等)。由Flink应用程序产生的结果流可以发送到各种各样的系统,并且可以通过REST API访问Flink中包含的状态。
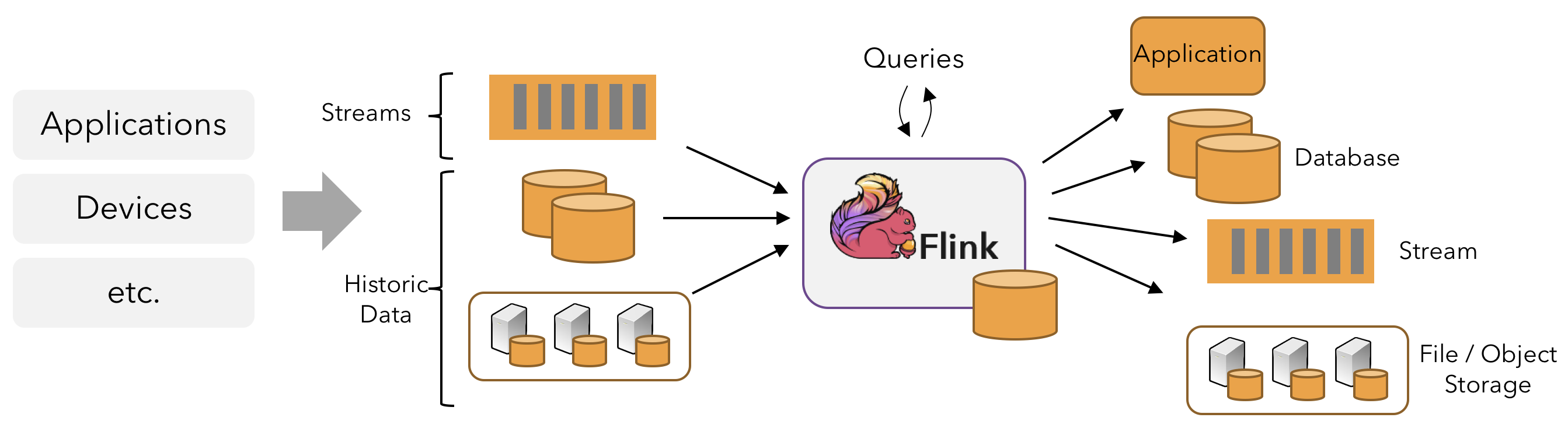
当Flink处理一个有界的数据流时,就是采用的批处理工作模式。在这种操作模式中,我们可以选择先读取整个数据集,然后对数据进行排序、计算全局统计数据或生成总结所有输入的最终报告。 当Flink处理一个无界的数据流时,就是采用的流处理工作模式。对于流数据处理,输入可能永远不会结束,因此我们必须在数据到达时持续不断地对这些数据进行处理。
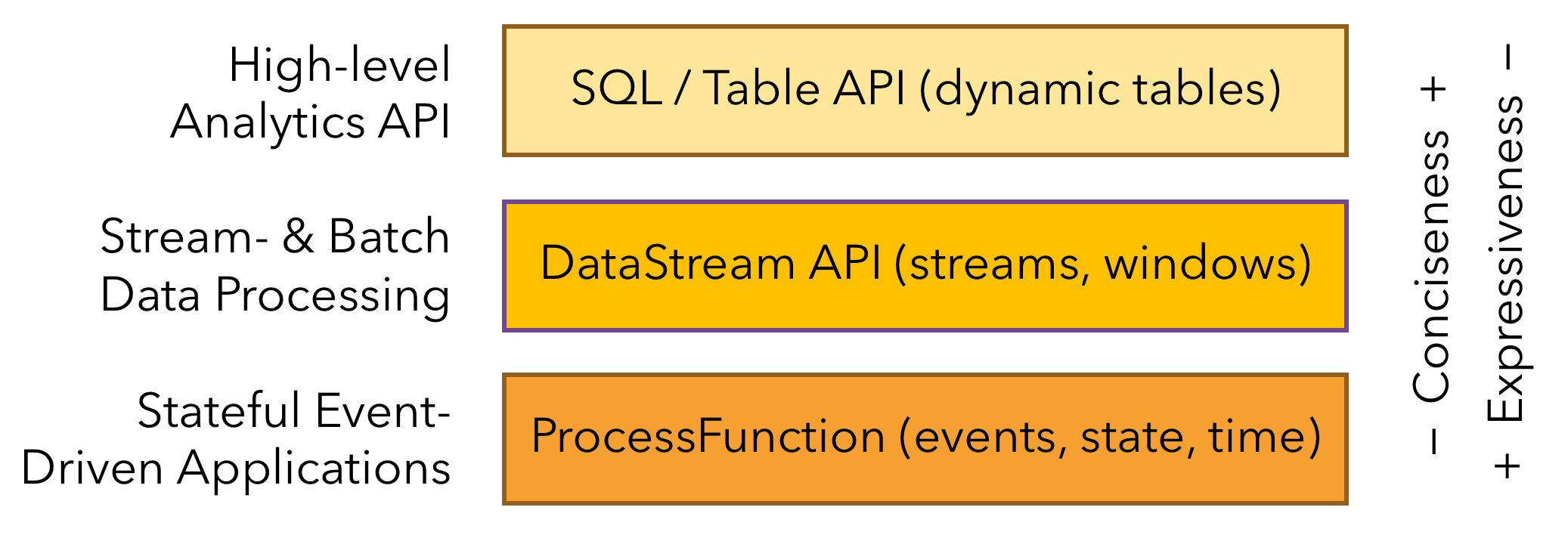
Flink分层API
Flink提供了开发流/批处理应用程序的不同抽象层次。如下图所示:
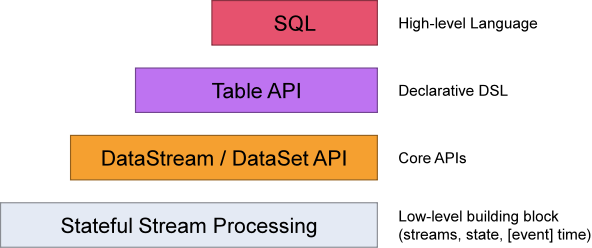
Flink提供了三个分层的API。每个API在简洁性和表达性之间提供了不同的权衡,并针对不同的应用场景。