Flink数据分区
在Flink中,我们可以对转换后的流数据执行物理分区,以进行低级控制(如果需要的话)。Flink支持以下8种分区方法。
| 分区方法 | 操作方式 |
|---|---|
| shuffle | 随机对数据流进行分区,根据均匀分布随机划分元素。 |
| rebalance | round-robin方式。使用循环分配分区元素的方法,为每个分区创建相等的负载。 |
| rescale | 根据上下游运算符的数量,对元素做一个均匀分配。 |
| broadcast | 将输出元素被广播到下一个操作(算子)的每个并行实例。 |
| keyBy | 按key划分数据流,相同key的元素到一个分区上。 |
| forward | 将输出元素被转发到下一个操作的本地子任务。 |
| global | 将所有的数据都发送到下游 0 号分区中。 |
| 自定义分区 | 使用用户定义的分区程序(Partitioner)为每个元素选择目标任务。 |
不同的分区方法代表了Flink中不同的数据分区策略,数据的分区策略决定了数据会分发到下游算子的那个分区。下面我们详细了解这8种分区方法的原理和应用。
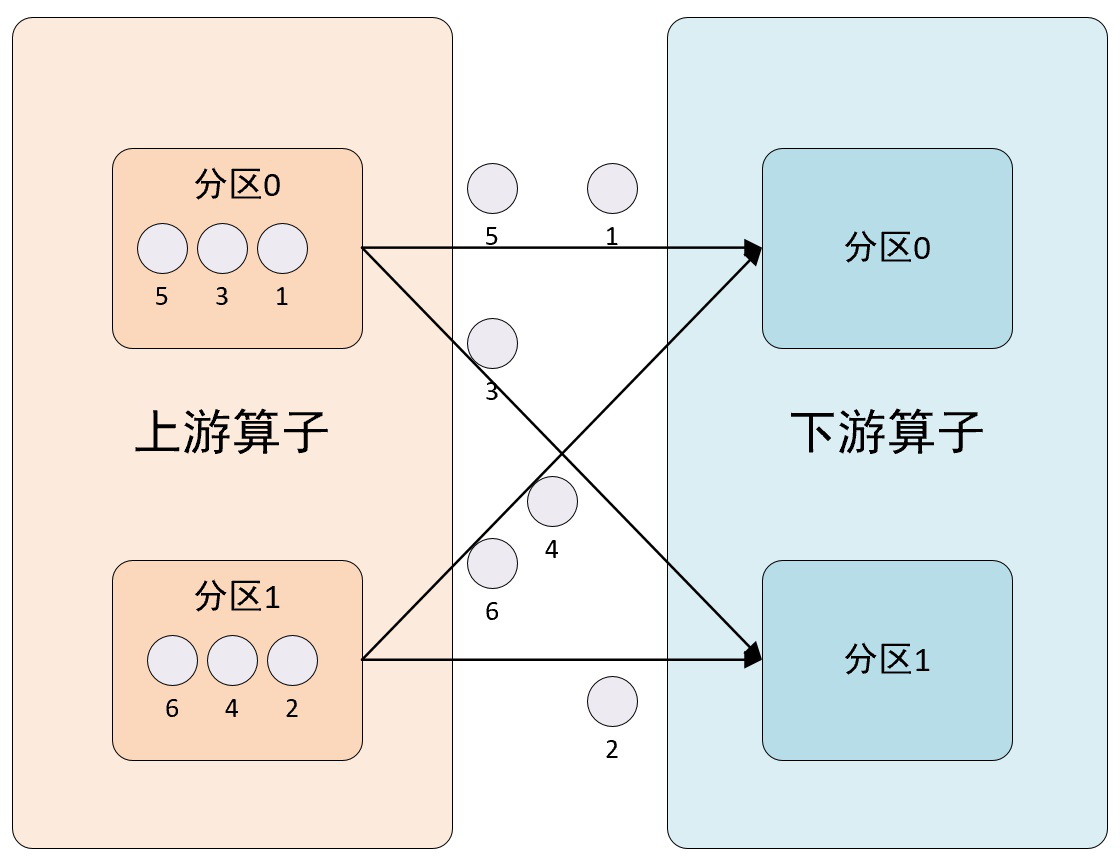
1、shuffle方法
该方法使用ShufflePartitioner分区程序来设置DataStream的分区,通过随机选择一个输出通道平均分配数据。该方法会将输出元素均匀随机地打乱到下一个操作(算子),其分区示意图如下所示:
Scala代码:
import org.apache.flink.streaming.api.scala._
/**
* shuffle方法随机分区
*/
object PartitionShuffle {
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5))
// 这里只是为了能够将并行度设置为 2
val stream2 = stream
.map(v=>{(v%2,v)}) // 偶数key为0,奇数key为1
.keyBy(0) // 按奇偶进行分区
.map(v=>(v._1,v._2))
.setParallelism(2)
println(stream2.parallelism) // 查看并行度
// 查看随机分区的结果
stream2.shuffle.print("shuffle").setParallelism(3)
// 触发流程序执行
env.execute("shuffle分区示例")
}
}
Java代码:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* shuffle方法随机分区
*/
public class PartitionShuffle {
public static void main(String[] args) throws Exception {
// 设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从自定义的集合中读取数据
DataStream<Integer> stream = env.fromCollection(Arrays.asList(1,2,3,4,5));
// 这里只是为了能够将并行度设置为 2
DataStream<Tuple2<Integer,Integer>> stream2 = stream
.map(new MapFunction<Integer, Tuple2<Integer,Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Integer input) throws Exception {
return new Tuple2<>(input%2, input);
}
}) // 偶数key为0,奇数key为1
.keyBy(t -> t.f0) // 按奇偶进行分区
.map(new MapFunction<Tuple2<Integer,Integer>, Tuple2<Integer,Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Tuple2<Integer, Integer> t) throws Exception {
return new Tuple2<>(t.f0, t.f1);
}
})
.setParallelism(2);
System.out.println(stream2.getParallelism()); // 查看并行度
// 查看随机分区的结果
stream2.shuffle().print("shuffle").setParallelism(3);
// 触发流程序执行
env.execute("shuffle分区示例");
}
}
执行以上代码,输出结果如下所示:
2 shuffle:1> (0,2) shuffle:3> (1,5) shuffle:2> (1,3) shuffle:1> (1,1) shuffle:3> (0,4)
2、rebalance方法
该方法使用RebalancePartitioner分区程序来设置DataStream的分区,使用循环通过输出通道平均分配数据。该方法会将输出元素以轮循方式均匀地分布到下一个操作(算子)的实例中,其分区示意图如下所示:
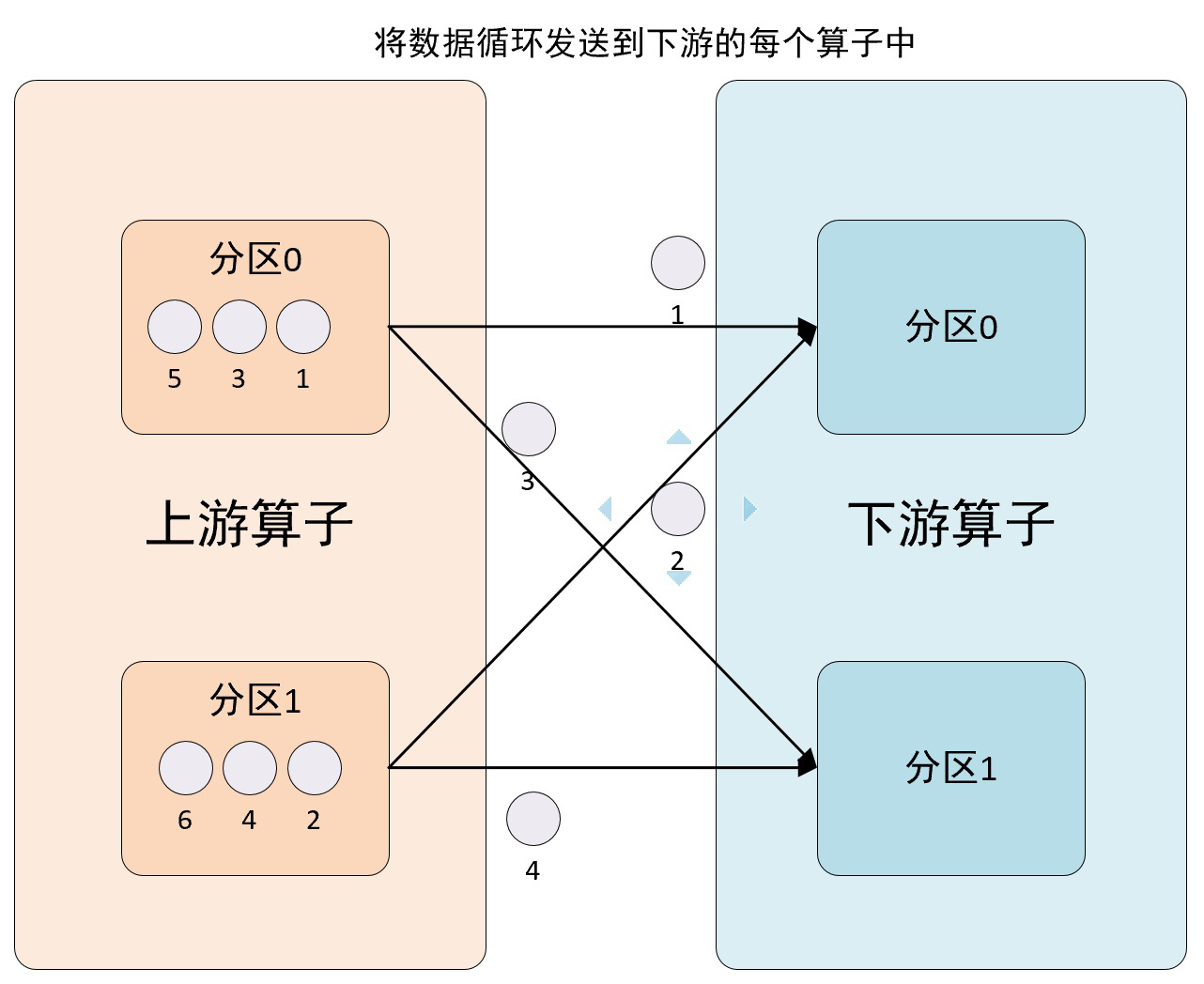
这种类型的分区有助于均匀地分布数据。它使用循环分配分区元素的方法,为每个分区创建相等的负载。这种类型的分区对于存在数据倾斜的情况下的性能优化非常有用。
Scala代码:
import org.apache.flink.streaming.api.scala._
/**
* 该方法使用RebalancePartitioner分区程序来设置DataStream的分区,使用循环通过输出通道平均分配数据。
* 该方法会将输出元素以轮循方式均匀地分布到下一个操作(算子)的实例中。
*/
object RebalancePartitioner extends App{
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5,6))
// 直接打印数据
stream.rebalance.print("rebalance").setParallelism(2)
env.execute("rebalance分区示例")
}
Java代码:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* 该方法使用RebalancePartitioner分区程序来设置DataStream的分区,使用循环通过输出通道平均分配数据。
* 该方法会将输出元素以轮循方式均匀地分布到下一个操作(算子)的实例中。
*/
public class PartitionRebalance {
public static void main(String[] args) throws Exception {
// 设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从自定义的集合中读取数据
DataStream<Integer> stream = env.fromCollection(Arrays.asList(1,2,3,4,5,6));
// 直接打印数据
stream.rebalance().print("rebalance").setParallelism(2);
// 触发流程序执行
env.execute("rebalance分区示例");
}
}
执行以上代码,输出结果如下所示:
rebalance:2> 1 rebalance:1> 2 rebalance:2> 3 rebalance:1> 4 rebalance:2> 5 rebalance:1> 6
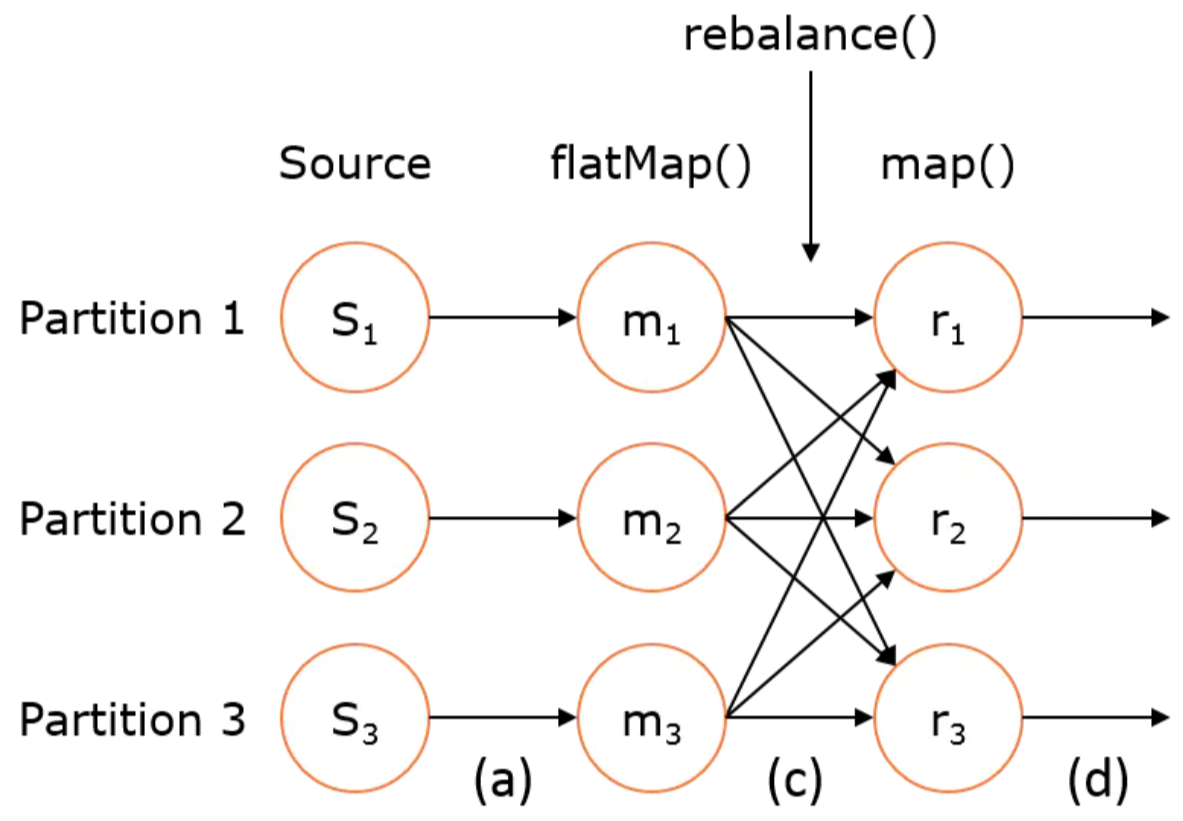
3、rescale方法
该方法使用RescalePartitioner分区程序来设置DataStream的分区,使用循环通过输出通道平均分配数据。该方法会将输出元素以轮循方式均匀地分布到下一个操作(算子)的实例子集,其分区示意图如下所示:
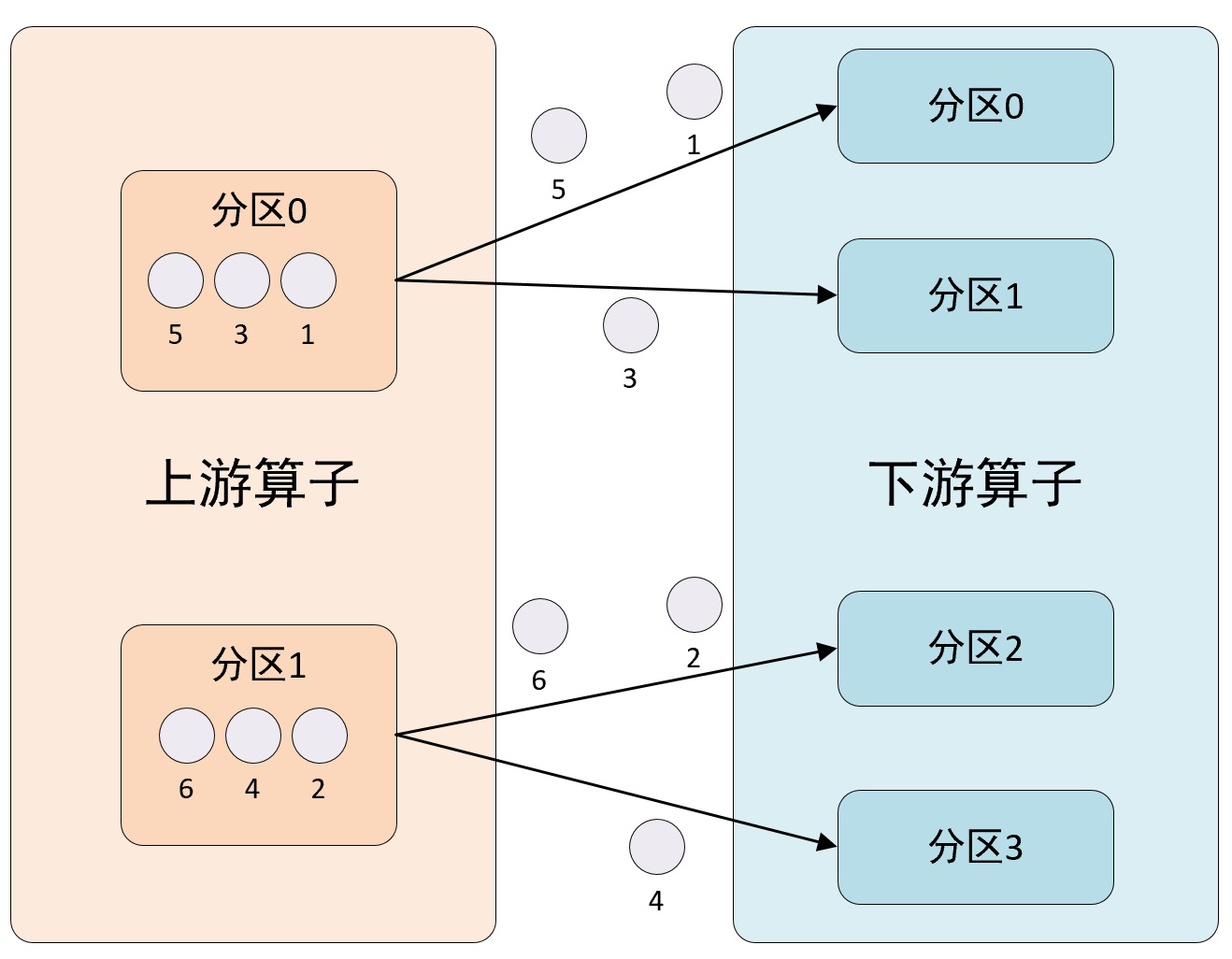
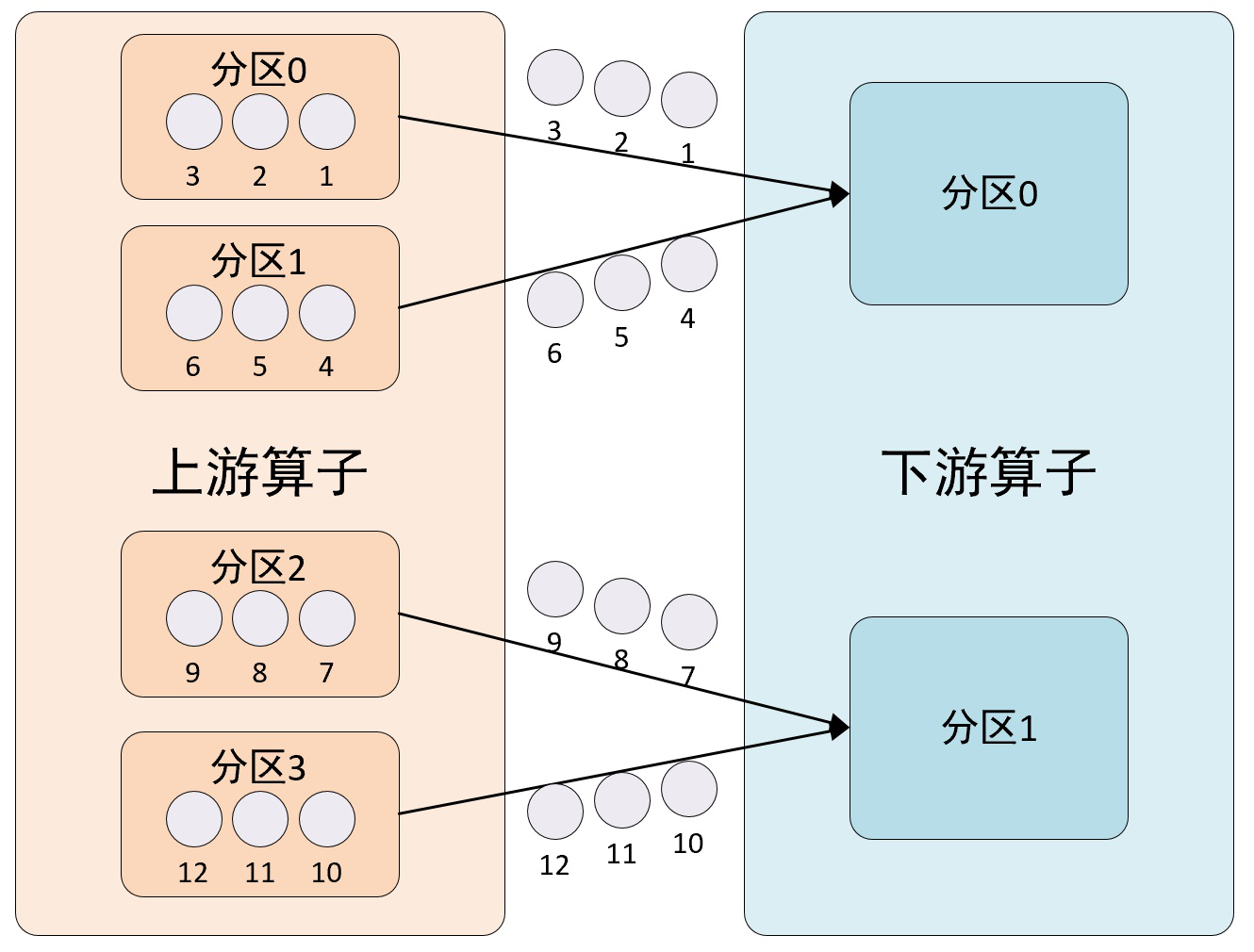
在这种分区方法中,Flink循环将元素划分为下游操作的子集。上游操作向其发送元素的下游操作子集取决于上游和下游操作的并行度。例如,如果上游操作的并行度为2,而下游操作的并行度为4,那么一个上游操作将把元素分配给两个下游操作,而另一个上游操作将分配给另外两个下游操作。另一方面,如果下游操作的并行度为2,而上游操作的并行度为4,那么两个上游操作将分配给一个下游操作,而另外两个上游操作将分配给另一个下游操作。
在上下游算子的并行度不是彼此的倍数的情况下,一个或几个下游操作与上游操作的输入数量不同。
Scala代码:
import org.apache.flink.streaming.api.scala._
/**
* 该方法使用RescalePartitioner分区程序来设置DataStream的分区,使用循环通过输出通道平均分配数据。
* 该方法会将输出元素以轮循方式均匀地分布到下一个操作(算子)的实例子集。
*/
object PartitionRescale {
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5,6,7,8))
stream.print("before rescale")
// 直接打印数据
stream.rescale.print("rescale").setParallelism(2)
// 触发流程序执行
env.execute("rescale分区示例")
}
}
Java代码:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* 该方法使用RescalePartitioner分区程序来设置DataStream的分区,使用循环通过输出通道平均分配数据。
* 该方法会将输出元素以轮循方式均匀地分布到下一个操作(算子)的实例子集。
*/
public class PartitionRescale {
public static void main(String[] args) throws Exception {
// 设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从自定义的集合中读取数据
DataStream<Integer> stream = env.fromCollection(Arrays.asList(1,2,3,4,5,6,7,8));
stream.print("before rescale");
// 直接打印数据
stream.rescale().print("rescale").setParallelism(2);
// 触发流程序执行
env.execute("rescale分区示例");
}
}
执行以上代码,输出结果如下所示:
before rescale:7> 7 before rescale:3> 3 before rescale:1> 1 before rescale:5> 5 before rescale:8> 8 before rescale:4> 4 before rescale:2> 2 before rescale:6> 6 rescale:1> 1 rescale:1> 3 rescale:2> 2 rescale:2> 4 rescale:1> 5 rescale:2> 6 rescale:1> 7 rescale:2> 8
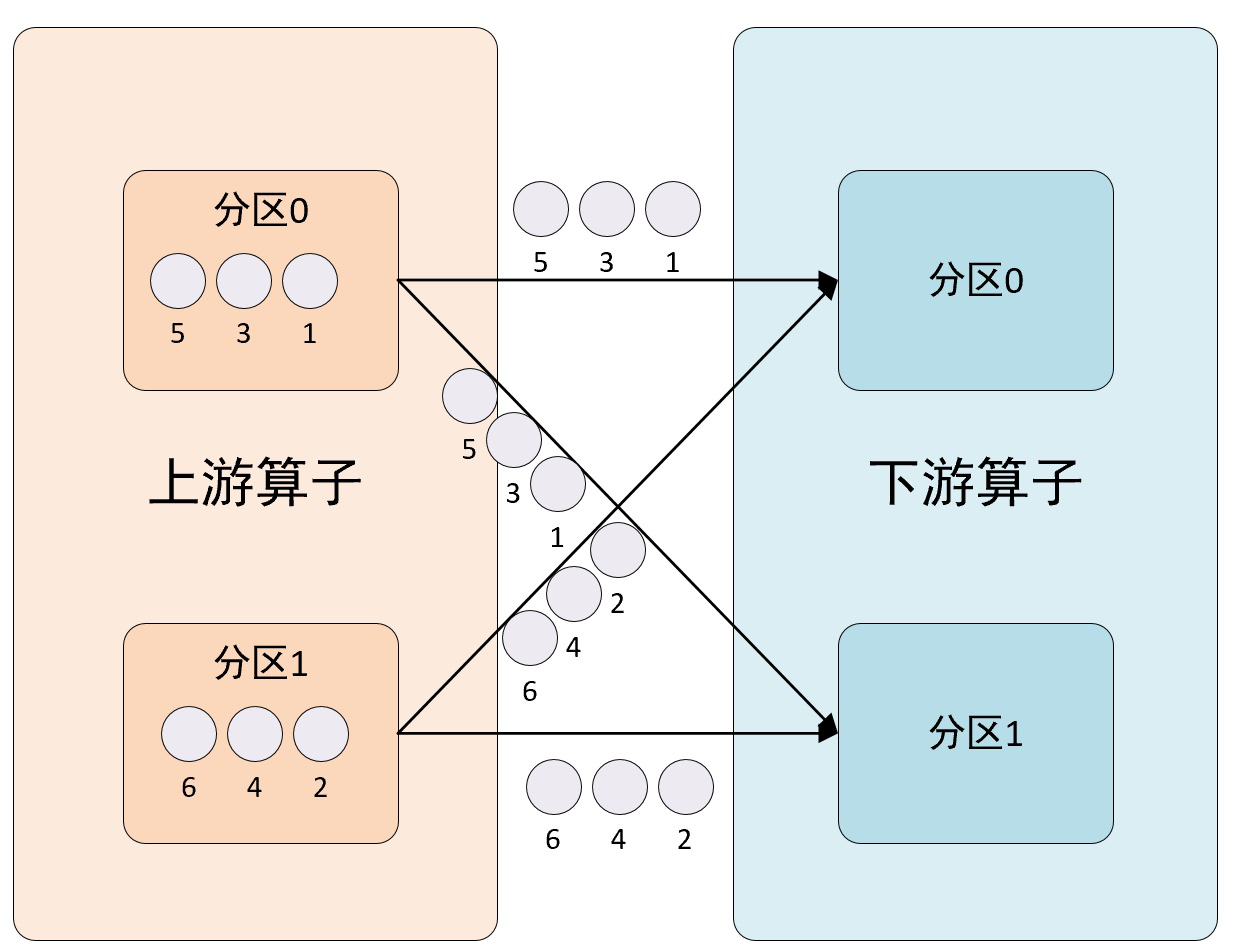
4、broadcast方法
该方法使用BroadcastPartitioner分区程序来设置DataStream的分区,通过选择所有输出通道将所有记录分发到每个分区。该方法会将输出元素被广播到下一个操作(算子)的每个并行实例,其分区示意图如下所示:
Scala代码:
import org.apache.flink.streaming.api.scala._
/**
* 该方法使用BroadcastPartitioner分区程序来设置DataStream的分区,通过选择所有输出通道将所有记录
* 分发到每个分区。该方法会将输出元素被广播到下一个操作(算子)的每个并行实例。
*/
object PartitionBroadcast {
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5))
// 直接打印数据
stream.broadcast.print("broadcast").setParallelism(2)
// 触发流程序执行
env.execute("broadcast分区示例")
}
}
Java代码:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* 该方法使用BroadcastPartitioner分区程序来设置DataStream的分区,通过选择所有输出通道将所有记录
* 分发到每个分区。该方法会将输出元素被广播到下一个操作(算子)的每个并行实例。
*/
public class PartitionBroadcast {
public static void main(String[] args) throws Exception {
// 设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从自定义的集合中读取数据
DataStream<Integer> stream = env.fromCollection(Arrays.asList(1,2,3,4,5));
// 直接打印数据
stream.broadcast().print("broadcast").setParallelism(2);
// 触发流程序执行
env.execute("broadcast分区示例");
}
}
执行以上代码,输出结果如下所示:
broadcast:1> 1 broadcast:2> 1 broadcast:1> 2 broadcast:2> 2 broadcast:1> 3 broadcast:2> 3 broadcast:1> 4 broadcast:2> 4 broadcast:1> 5 broadcast:2> 5
5、forward方法
该方法使用ForwardPartitioner分区程序来设置DataStream的分区,仅将元素转发到本地运行的下游操作(算子)。该方法会将输出元素被转发到下一个操作(算子)的本地子任务,其分区示意图如下所示:
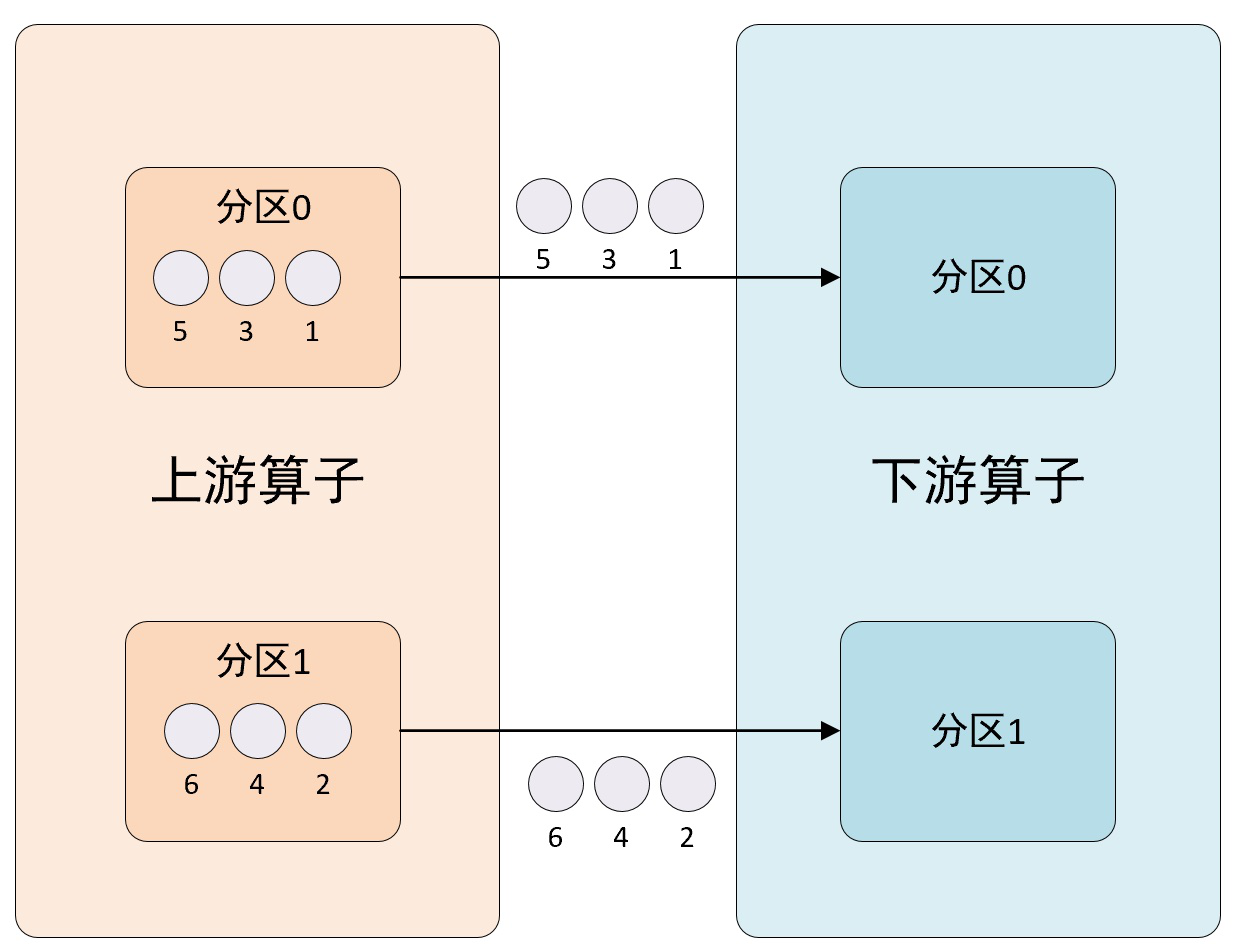
在上下游的算子没有指定分区器的情况下,如果上下游的算子并行度一致,则使用ForwardPartitioner,否则使用RebalancePartitioner。对于ForwardPartitioner,必须保证上下游算子并行度一致,即上有算子与下游算子是1 对 1的关系,否则会抛出异常。
Scala代码:
import org.apache.flink.streaming.api.scala._
/**
* 该方法使用ForwardPartitioner分区程序来设置DataStream的分区,仅将元素转发到本地运行的
* 下游操作(算子)。该方法会将输出元素被转发到下一个操作(算子)的本地子任务。
*/
object PartitionForward {
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5))
// 直接打印数据
stream.map(v=>{v * v}).setParallelism(2).forward.print().setParallelism(2)
// 触发流程序执行
env.execute("forward分区示例")
}
}
Java代码:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* 该方法使用ForwardPartitioner分区程序来设置DataStream的分区,仅将元素转发到本地运行的下游操作(算子)。
* 该方法会将输出元素被转发到下一个操作(算子)的本地子任务。
*/
public class PartitionForward {
public static void main(String[] args) throws Exception {
// 设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从自定义的集合中读取数据
DataStream<Integer> stream = env.fromCollection(Arrays.asList(1,2,3,4,5));
// 直接打印数据
stream.map(
new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer input) throws Exception {
return input * input;
}
})
.setParallelism(2)
.forward()
.print("forward")
.setParallelism(2);
// 触发流程序执行
env.execute("forward分区示例");
}
}
执行以上代码,输出结果如下所示:
forward:1> 1 forward:2> 4 forward:1> 9 forward:2> 16 forward:1> 25
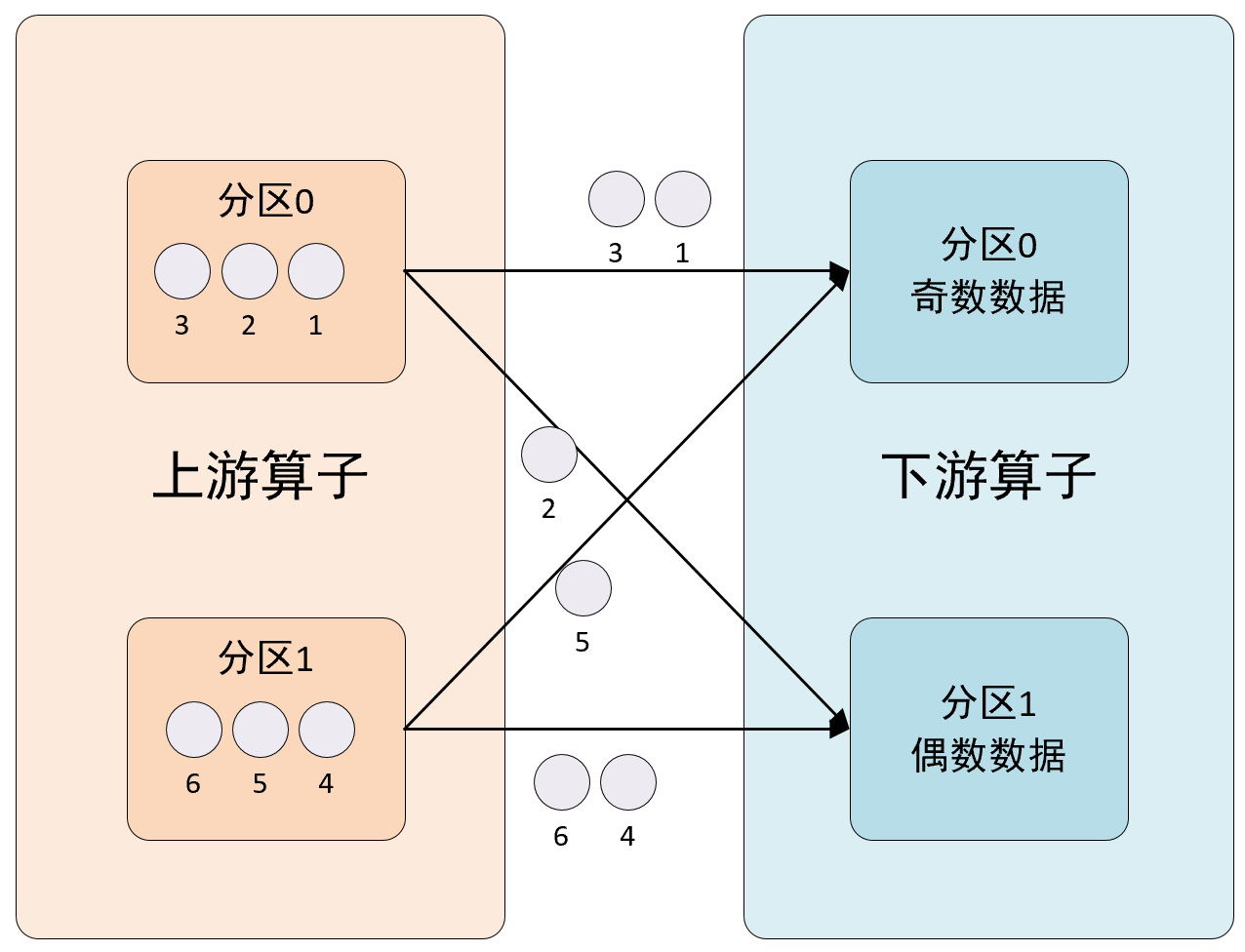
6、keyBy方法
该方法使用KeyGroupStreamPartitioner分区程序来设置DataStream的分区,根据key的分组索引选择目标通道,将输出元素发送到相对应的下游分区。该方法的分区示意图如下所示:
Scala代码:
import org.apache.flink.streaming.api.scala._
/**
* 该方法使用KeyGroupStreamPartitioner分区程序来设置DataStream的分区,
* 根据key的分组索引选择目标通道,将输出元素发送到相对应的下游分区。
* 该方法会创建一个新的KeyedStream,使用提供的key来划分其操作符(算子)状态。
*/
object PartitionKeyBy {
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5,6))
// 先转换为(k,v)对,再执行keyBy,然后打印数据
val stream2 = stream.map(v => {(v%3,v)})
stream2.setParallelism(2).keyBy(0).print("key")
// 触发流程序执行
env.execute("keyBy分区示例")
}
}
Java代码:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* 该方法使用KeyGroupStreamPartitioner分区程序来设置DataStream的分区,
* 根据key的分组索引选择目标通道,将输出元素发送到相对应的下游分区。
* 该方法会创建一个新的KeyedStream,使用提供的key来划分其操作符(算子)状态。
*/
public class PartitionKeyBy {
public static void main(String[] args) throws Exception {
// 设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从自定义的集合中读取数据
DataStream<Integer> stream = env.fromCollection(Arrays.asList(1,2,3,4,5,6));
// 直接打印数据
DataStream<Tuple2<Integer, Integer>> stream2 = stream.map(
new MapFunction<Integer, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Integer input) throws Exception {
return new Tuple2<>(input % 3, input);
}
}
).setParallelism(2);
stream2.keyBy(t -> t.f0).print("key");
// 触发流程序执行
env.execute("keyBy分区示例");
}
}
该方法会创建一个新的KeyedStream,使用提供的key来划分其操作符(算子)状态。
执行以上代码,输出结果如下所示:
key:8> (2,2) key:6> (1,1) key:6> (0,3) key:8> (2,5) key:6> (1,4) key:6> (0,6)
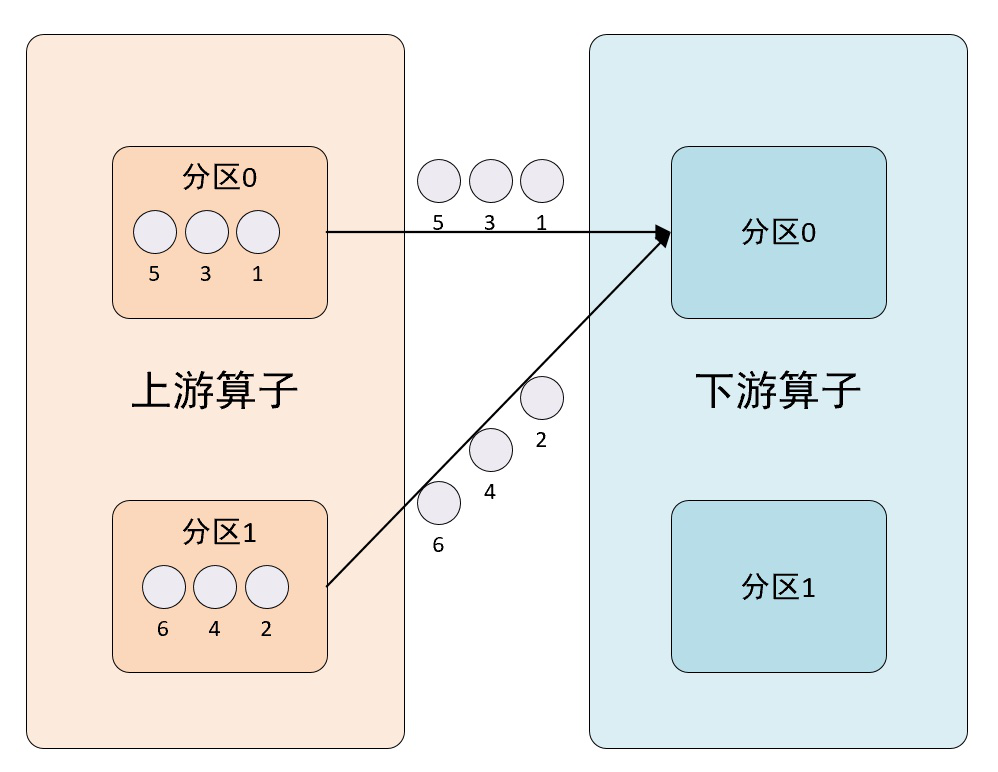
7、global方法
该方法使用GlobalPartitioner分区程序来设置DataStream的分区,以便将输出值都转到下一个处理操作符(算子)的第一个实例。使用此设置时要小心,因为它可能会在应用程序中造成严重的性能瓶颈。该方法的分区示意图如下所示:
Scala代码:
import org.apache.flink.streaming.api.scala._
/**
* 该方法使用GlobalPartitioner分区程序来设置DataStream的分区,
* 以便将输出值都转到下一个处理操作符(算子)的第一个实例。
* 使用此设置时要小心,因为它可能会在应用程序中造成严重的性能瓶颈。
*/
object PartitionGlobal {
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从自定义的集合中读取数据
val stream = env.fromCollection(List(1,2,3,4,5))
// 直接打印数据
stream.print()
// 使用 GLobalPartitioner 之后打印数据
stream.global.print("global")
// 触发流程序执行
env.execute("global分区示例")
}
}
Java代码:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* 该方法使用GlobalPartitioner分区程序来设置DataStream的分区,
* 以便将输出值都转到下一个处理操作符(算子)的第一个实例。
* 使用此设置时要小心,因为它可能会在应用程序中造成严重的性能瓶颈。
*/
public class PartitionGlobal {
public static void main(String[] args) throws Exception {
// 设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从自定义的集合中读取数据
DataStream<Integer> stream = env.fromCollection(Arrays.asList(1,2,3,4,5));
// 直接打印数据
stream.print();
// 使用 GLobalPartitioner 之后打印数据
stream.global().print("global");
// 触发流程序执行
env.execute("global分区示例");
}
}
执行以上代码,输出结果如下所示:
global:1> 2 global:1> 3 global:1> 4 global:1> 5
