使用JDBC连接器
JDBC Connector提供了一个接收器,用于将数据写入JDBC数据库。要使用它,请将以下依赖项添加到项目中:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc_2.12</artifactId> <version>1.13.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.48</version> </dependency>
注:mysql的版本可以根据自己的实际安装进行修改。
创建的JDBC接收器提供了“至少一次”的保证。有效使用upsert语句或幂等更新可以实现“精确一次”保证。其用法如下所示:
JdbcSink.sink(
sqlDmlStatement, // 必须的
jdbcStatementBuilder, // 必须的
jdbcExecutionOptions, // 可选的
jdbcConnectionOptions // 必须的
);
SQL DML语句是用户提供的SQL语句,通常带有占位符。
JDBC语句构建器从用户提供的SQL字符串构建一个JDBC预编译语句,并重复调用用户指定的函数来使用流中的每个元素值来更新这个预编译语句。
SQL DML语句是批量执行的,可以选择使用以下实例配置这些语句:
JdbcExecutionOptions.builder()
.withBatchIntervalMs(200) // 可选地: default = 0,这意味着没有基于时间的执行
.withBathSize(1000) // 可选地: default = 5000
.withMaxRetries(5) // 可选地: default = 3
.build()
只要满足以下条件之一,就会执行JDBC批处理:
- 已经过配置的批处理间隔时间;
- 已达到最大批大小;
- Flink检查点已经启动。
数据库连接是用JdbcConnectionOptions实例配置的。
注:从1.13开始,Flink JDBC接收器支持精确一次模式。该实现依赖于XA标准的JDBC驱动程序支持。
注:在1.13中,对于MySQL或其他不支持每个连接多个XA事务的数据库,Flink JDBC接收器不支持精确一次模式。
【示例】使用JdbcSink将流数据写入到MySQL数据库。
请按以下步骤执行。
1)首先,在MySQL中执行如下脚本,创建用来接收写入数据的books数据表。
# 创建数据库xueai8 mysql> create database xueai8; # 切换到数据库xueai8 mysql> use xueai8; # 创建数据表books create table books( id bigint, title varchar(100), authors varchar(50), year int );
2)然后,编写Flink流处理程序,将数据流中的图书信息写入上面创建的books数据表中。
Scala代码:
import java.sql.PreparedStatement
import org.apache.flink.connector.jdbc._
import org.apache.flink.connector.jdbc.JdbcConnectionOptions
import org.apache.flink.streaming.api.scala._
/**
* jdbc连接器示例
*
*/
object JdbcSinkDemo {
// 事件元素类型
case class Book(id: Long, title: String, authors: String,year: Integer)
def main(args: Array[String]) {
// 设置流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env
.fromElements(
Book(101L, "Java从初学到精通", "xinliwei", 2019),
Book(102L, "流处理系统", "someone", 2018),
Book(103L, "Hadoop大数据处理技术", "zhangsan", 2017),
Book(104L, "Spark大数据处理技术", "xinliwei", 2021)
)
.addSink(
JdbcSink.sink(
// SQL语句,带有占位符
"insert into books (id, title, authors, year) values (?, ?, ?, ?)",
// 预编译语句
new JdbcStatementBuilder[Book]{
// 重复调用这个函数,用流的每个值更新这个预编译语句
override def accept(ps: PreparedStatement, book: Book): Unit = {
ps.setLong(1, book.id)
ps.setString(2, book.title)
ps.setString(3, book.authors)
ps.setInt(4, book.year)
}
},
// 可选地,jdbc批处理参数
JdbcExecutionOptions.builder
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build,
// JDBC连接配置信息
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/xueai8?characterEncoding=UTF-8&useSSL=false")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("admin")
.build()
)
)
// 触发流程序执行
env.execute("Flink Streaming Scala API Skeleton")
}
}
Java代码:
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* jdbc连接器示例
*/
public class JdbcSinkDemo1 {
// POJO类,事件类型
public static class Book {
public Long id;
public String title;
public String authors;
public Integer year;
public Book(){}
public Book(Long id, String title, String authors, Integer year) {
this.id = id;
this.title = title;
this.authors = authors;
this.year = year;
}
}
public static void main(String[] args) throws Exception {
// 设置流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(
new Book(101L, "Java从初学到精通", "xinliwei", 2019),
new Book(102L, "Streaming Systems", "Tyler Akidau, Slava Chernyak, Reuven Lax", 2018),
new Book(103L, "Designing Data-Intensive Applications", "Martin Kleppmann", 2017),
new Book(104L, "Spark大数据处理技术", "xinliwei", 2021)
).addSink(
JdbcSink.sink(
// SQL语句,带有占位符
"insert into books (id, title, authors, year) values (?, ?, ?, ?)",
// 重复调用这个函数,用流的每个值更新这个预编译语句
(statement, book) -> {
statement.setLong(1, book.id);
statement.setString(2, book.title);
statement.setString(3, book.authors);
statement.setInt(4, book.year);
},
// 可选地,jdbc批处理参数
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
// JDBC连接配置信息
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/xueai8?characterEncoding=UTF-8&useSSL=false")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("admin")
.build()
));
// 触发流程序执行
env.execute("Jdbc Sink");
}
}
3)执行以上程序。
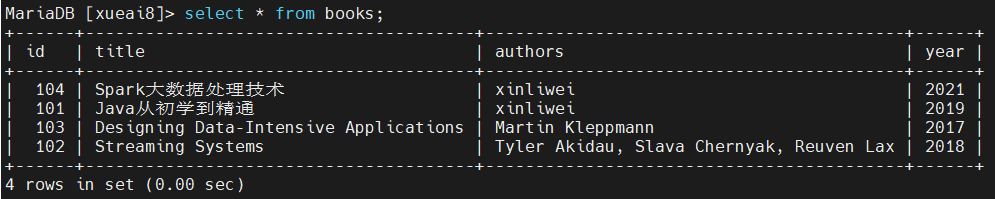
4)在mysql中查询books表,可以看到数据已经被正确写入了。